Getz Laura M, Nordeen Elke R, Vrabic Sarah C, Toscano Joseph C
Department of Psychology, Villanova University, Villanova, PA 19085, USA.
Brain Sci. 2017 Mar 21;7(3):32. doi: 10.3390/brainsci7030032.
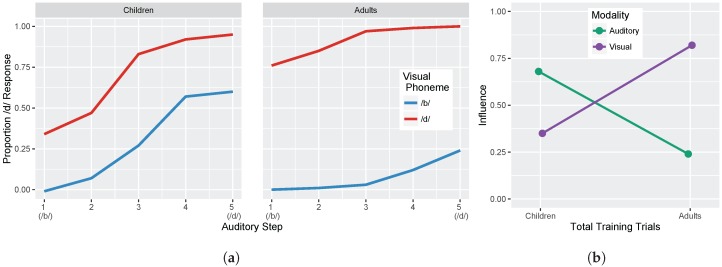
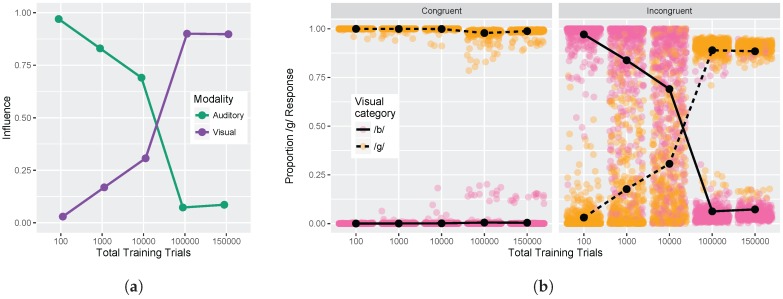
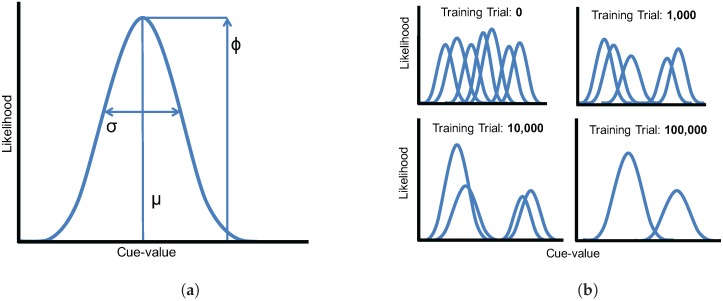
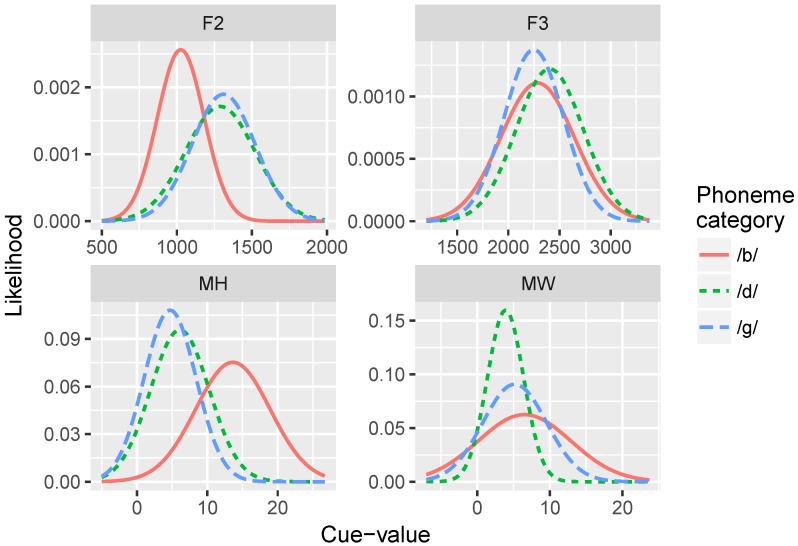
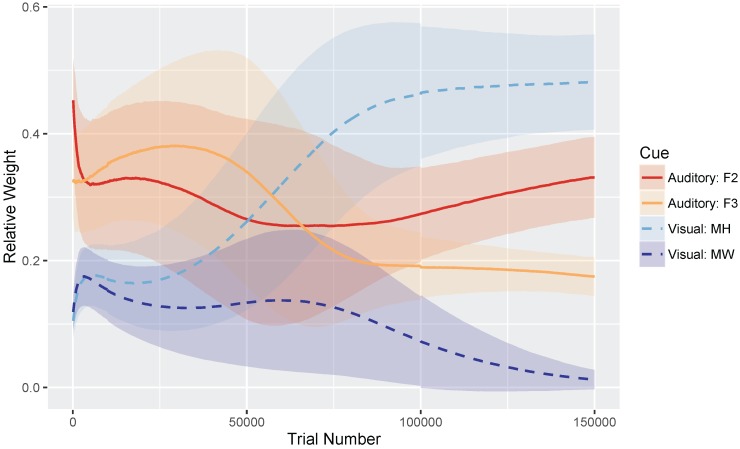
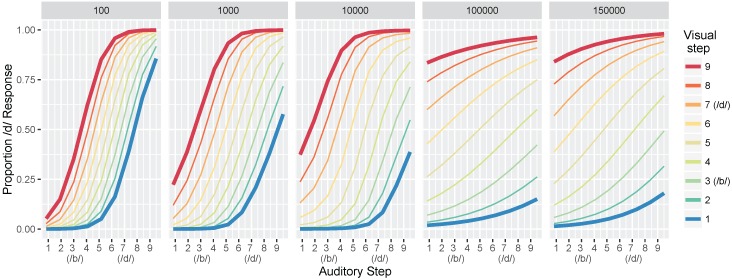
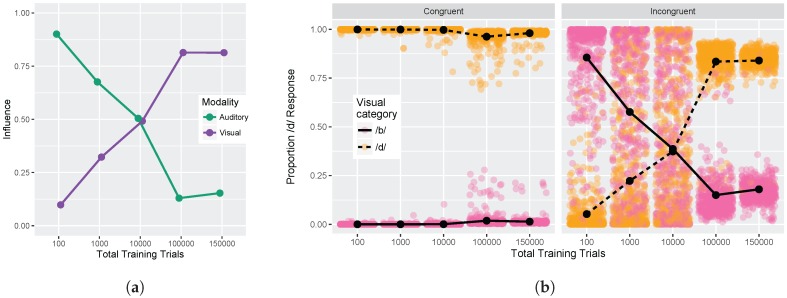
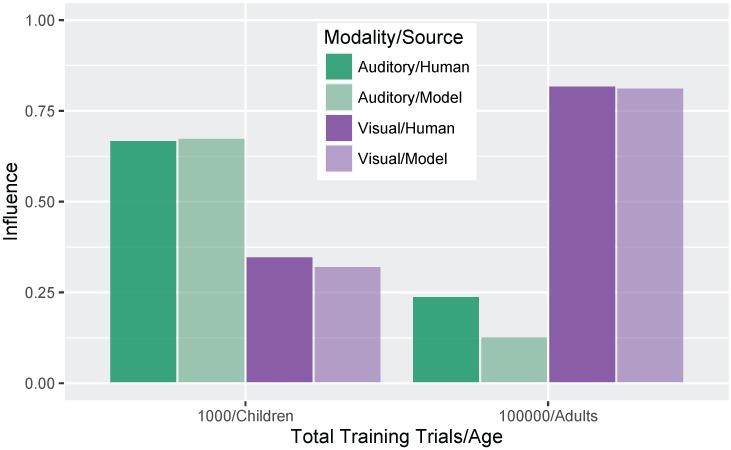
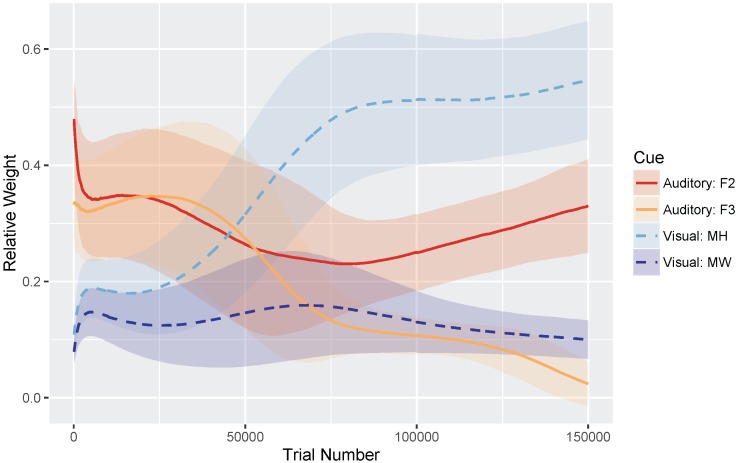
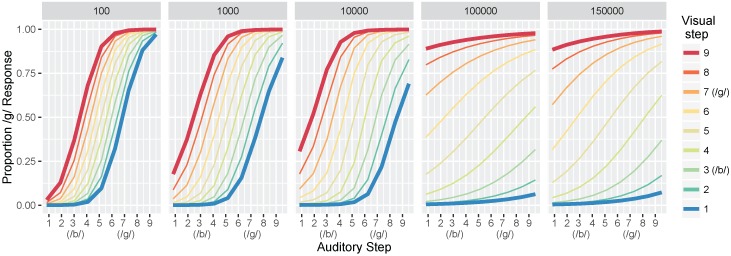
Adult speech perception is generally enhanced when information is provided from multiple modalities. In contrast, infants do not appear to benefit from combining auditory and visual speech information early in development. This is true despite the fact that both modalities are important to speech comprehension even at early stages of language acquisition. How then do listeners learn how to process auditory and visual information as part of a unified signal? In the auditory domain, statistical learning processes provide an excellent mechanism for acquiring phonological categories. Is this also true for the more complex problem of acquiring audiovisual correspondences, which require the learner to integrate information from multiple modalities? In this paper, we present simulations using Gaussian mixture models (GMMs) that learn cue weights and combine cues on the basis of their distributional statistics. First, we simulate the developmental process of acquiring phonological categories from auditory and visual cues, asking whether simple statistical learning approaches are sufficient for learning multi-modal representations. Second, we use this time course information to explain audiovisual speech perception in adult perceivers, including cases where auditory and visual input are mismatched. Overall, we find that domain-general statistical learning techniques allow us to model the developmental trajectory of audiovisual cue integration in speech, and in turn, allow us to better understand the mechanisms that give rise to unified percepts based on multiple cues.
当从多种模态提供信息时,成人的言语感知通常会得到增强。相比之下,婴儿在发育早期似乎无法从结合听觉和视觉言语信息中受益。尽管在语言习得的早期阶段,这两种模态对言语理解都很重要,但情况确实如此。那么,听众是如何学习将听觉和视觉信息作为统一信号的一部分进行处理的呢?在听觉领域,统计学习过程为获取音系范畴提供了一种出色的机制。对于获取视听对应关系这个更复杂的问题,情况也是如此吗?获取视听对应关系要求学习者整合来自多种模态的信息。在本文中,我们展示了使用高斯混合模型(GMM)的模拟,该模型学习线索权重并根据其分布统计信息组合线索。首先,我们模拟从听觉和视觉线索中获取音系范畴的发育过程,探讨简单的统计学习方法是否足以学习多模态表征。其次,我们利用这个时间进程信息来解释成年感知者的视听言语感知,包括听觉和视觉输入不匹配的情况。总体而言,我们发现通用领域的统计学习技术使我们能够对言语中视听线索整合的发育轨迹进行建模,进而使我们能够更好地理解基于多种线索产生统一感知的机制。