DKMS Life Science Lab, Dresden, Germany.
Deep Sequencing Group, CRTD - Center for Regenerative Therapies Dresden, Dresden, Germany.
HLA. 2017 Aug;90(2):79-87. doi: 10.1111/tan.13057. Epub 2017 May 25.
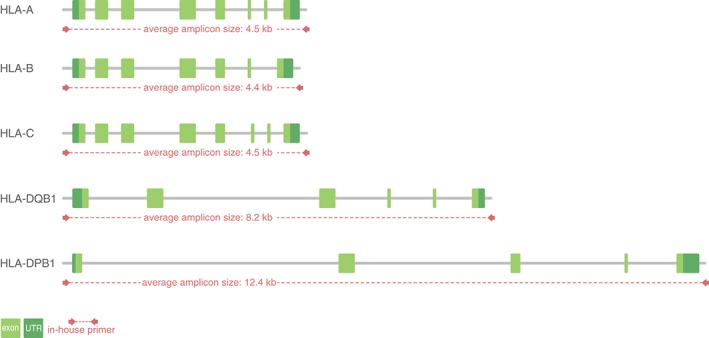
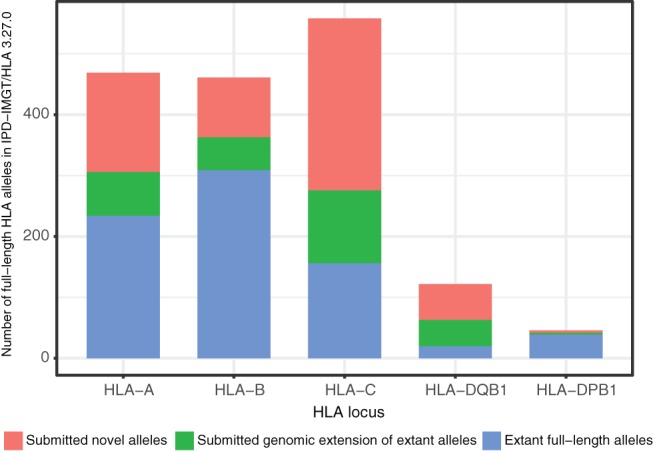
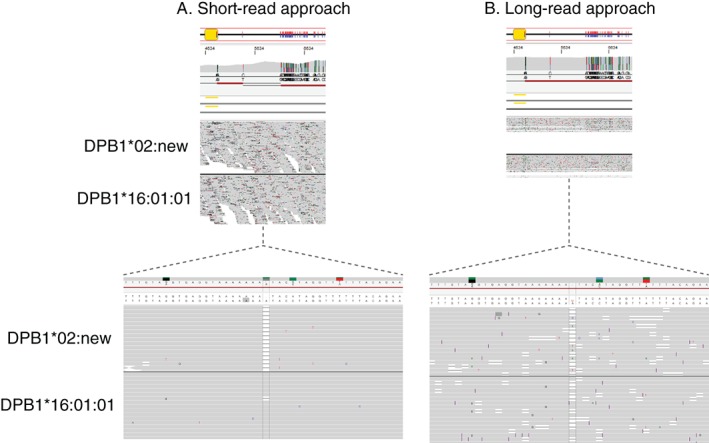
The high-throughput department of DKMS Life Science Lab encounters novel human leukocyte antigen (HLA) alleles on a daily basis. To characterise these alleles, we have developed a system to sequence the whole gene from 5'- to 3'-UTR for the HLA loci A, B, C, DQB1 and DPB1 for submission to the European Molecular Biology Laboratory - European Nucleotide Archive (EMBL-ENA) and the IPD-IMGT/HLA Database. Our workflow is based on a dual redundant sequencing strategy. Using shotgun sequencing on an Illumina MiSeq instrument and single molecule real-time (SMRT) sequencing on a PacBio RS II instrument, we are able to achieve highly accurate HLA full-length consensus sequences. Remaining conflicts are resolved using the R package DR2S (Dual Redundant Reference Sequencing). Given the relatively high throughput of this strategy, we have developed the semi-automated web service TypeLoader, to aid in the submission of sequences to the EMBL-ENA and the IPD-IMGT/HLA Database. In the IPD-IMGT/HLA Database release 3.24.0 (April 2016; prior to the submission of the sequences described here), only 5.2% of all known HLA alleles have been fully characterised together with intronic and UTR sequences. So far, we have applied our strategy to characterise and submit 1056 HLA alleles, thereby more than doubling the number of fully characterised alleles. Given the increasing application of next generation sequencing (NGS) for full gene characterisation in clinical practice, extending the HLA database concomitantly is highly desirable. Therefore, we propose this dual redundant sequencing strategy as a workflow for submission of novel full-length alleles and characterisation of sequences that are as yet incomplete. This would help to mitigate the predominance of partially known alleles in the database.
DKMS 生命科学实验室高通量部门每天都会遇到新的人类白细胞抗原 (HLA) 等位基因。为了对这些等位基因进行特征描述,我们开发了一种从 5'UTR 到 3'UTR 对 HLA 基因座 A、B、C、DQB1 和 DPB1 进行全基因测序的系统,以便提交给欧洲分子生物学实验室-欧洲核苷酸档案库 (EMBL-ENA) 和国际组织相容性和基因命名委员会数据库 (IMGT/HLA)。我们的工作流程基于双重冗余测序策略。我们使用 Illumina MiSeq 仪器进行鸟枪法测序和 PacBio RS II 仪器进行单分子实时 (SMRT) 测序,从而能够获得高度准确的 HLA 全长共识序列。使用 R 包 DR2S(双重冗余参考测序)解决剩余的冲突。鉴于该策略具有较高的通量,我们开发了半自动网络服务 TypeLoader,以帮助向 EMBL-ENA 和 IPD-IMGT/HLA 数据库提交序列。在 IPD-IMGT/HLA 数据库 3.24.0 版(2016 年 4 月;在提交此处描述的序列之前)中,只有 5.2%的已知 HLA 等位基因与内含子和 UTR 序列一起得到了完全特征描述。到目前为止,我们已经应用该策略对 1056 个 HLA 等位基因进行了特征描述和提交,从而使完全特征描述的等位基因数量增加了一倍以上。鉴于下一代测序 (NGS) 在临床实践中对全基因特征描述的应用不断增加,同时扩展 HLA 数据库是非常需要的。因此,我们建议采用这种双重冗余测序策略作为提交新全长等位基因和特征描述的工作流程,以解决数据库中部分已知等位基因占主导地位的问题。