Li Yuanyuan, Kang Kai, Krahn Juno M, Croutwater Nicole, Lee Kevin, Umbach David M, Li Leping
Biostatistics and Computational Biology Branch, National Institute of Environmental Health Sciences, NIH, Durham, NC, 27709, USA.
Genome Integrity & Structural Biology Laboratory, National Institute of Environmental Health Sciences, NIH, Durham, NC, 27709, USA.
BMC Genomics. 2017 Jul 3;18(1):508. doi: 10.1186/s12864-017-3906-0.
The Cancer Genome Atlas (TCGA) has generated comprehensive molecular profiles. We aim to identify a set of genes whose expression patterns can distinguish diverse tumor types. Those features may serve as biomarkers for tumor diagnosis and drug development.
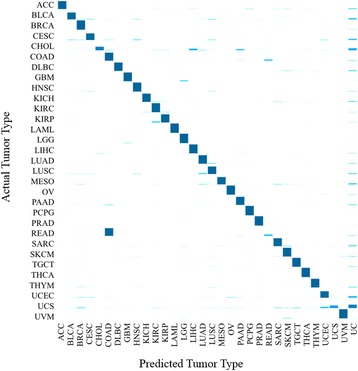
Using RNA-seq expression data, we undertook a pan-cancer classification of 9,096 TCGA tumor samples representing 31 tumor types. We randomly assigned 75% of samples into training and 25% into testing, proportionally allocating samples from each tumor type.
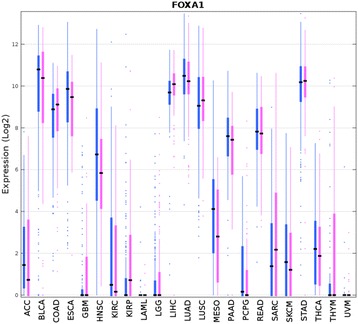
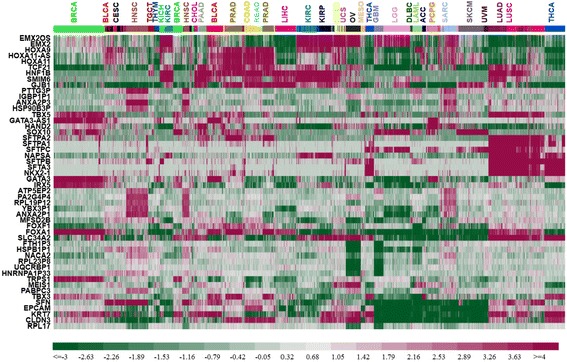
We could correctly classify more than 90% of the test set samples. Accuracies were high for all but three of the 31 tumor types, in particular, for READ (rectum adenocarcinoma) which was largely indistinguishable from COAD (colon adenocarcinoma). We also carried out pan-cancer classification, separately for males and females, on 23 sex non-specific tumor types (those unrelated to reproductive organs). Results from these gender-specific analyses largely recapitulated results when gender was ignored. Remarkably, more than 80% of the 100 most discriminative genes selected from each gender separately overlapped. Genes that were differentially expressed between genders included BNC1, FAT2, FOXA1, and HOXA11. FOXA1 has been shown to play a role for sexual dimorphism in liver cancer. The differentially discriminative genes we identified might be important for the gender differences in tumor incidence and survival.
We were able to identify many sets of 20 genes that could correctly classify more than 90% of the samples from 31 different tumor types using TCGA RNA-seq data. This accuracy is remarkable given the number of the tumor types and the total number of samples involved. We achieved similar results when we analyzed 23 non-sex-specific tumor types separately for males and females. We regard the frequency with which a gene appeared in those sets as measuring its importance for tumor classification. One third of the 50 most frequently appearing genes were pseudogenes; the degree of enrichment may be indicative of their importance in tumor classification. Lastly, we identified a few genes that might play a role in sexual dimorphism in certain cancers.
癌症基因组图谱(TCGA)已生成全面的分子图谱。我们旨在鉴定一组基因,其表达模式能够区分不同的肿瘤类型。这些特征可作为肿瘤诊断和药物开发的生物标志物。
利用RNA测序表达数据,我们对代表31种肿瘤类型的9096个TCGA肿瘤样本进行了泛癌分类。我们将75%的样本随机分配到训练组,25%分配到测试组,并按比例分配每种肿瘤类型的样本。
我们能够正确分类超过90%的测试集样本。除了31种肿瘤类型中的三种之外,其他所有类型的准确率都很高,特别是直肠腺癌(READ),它在很大程度上与结肠腺癌(COAD)难以区分。我们还对23种非性别特异性肿瘤类型(与生殖器官无关的肿瘤)分别针对男性和女性进行了泛癌分类。这些性别特异性分析的结果在很大程度上重现了忽略性别时的结果。值得注意的是,从男性和女性中分别选出的100个最具鉴别力的基因中,超过80%是重叠的。在性别之间差异表达的基因包括BNC1、FAT2、FOXA1和HOXA11。FOXA1已被证明在肝癌的性别二态性中发挥作用。我们鉴定出的差异鉴别基因可能对肿瘤发病率和生存率的性别差异很重要。
我们能够利用TCGA RNA测序数据鉴定出许多组20个基因,这些基因能够正确分类来自31种不同肿瘤类型的超过90%的样本。考虑到肿瘤类型的数量和所涉及的样本总数,这个准确率是非常显著的。当我们分别对男性和女性分析23种非性别特异性肿瘤类型时,也取得了类似的结果。我们将一个基因在这些基因集中出现的频率视为衡量其对肿瘤分类重要性的指标。出现频率最高的50个基因中有三分之一是假基因;其富集程度可能表明它们在肿瘤分类中的重要性。最后,我们鉴定出了一些可能在某些癌症的性别二态性中发挥作用的基因。