Pieces Technologies Inc, Dallas, TX, USA.
Department of Biomedical Informatics, Vanderbilt University, Nashville, TN, USA.
BMC Med Inform Decis Mak. 2017 Jul 5;17(Suppl 2):82. doi: 10.1186/s12911-017-0466-9.
Active learning (AL) has shown the promising potential to minimize the annotation cost while maximizing the performance in building statistical natural language processing (NLP) models. However, very few studies have investigated AL in a real-life setting in medical domain.
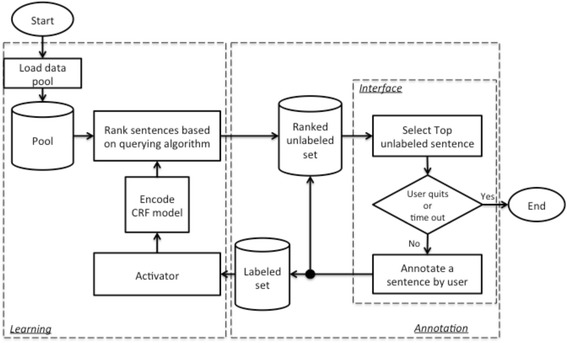
In this study, we developed the first AL-enabled annotation system for clinical named entity recognition (NER) with a novel AL algorithm. Besides the simulation study to evaluate the novel AL algorithm, we further conducted user studies with two nurses using this system to assess the performance of AL in real world annotation processes for building clinical NER models.
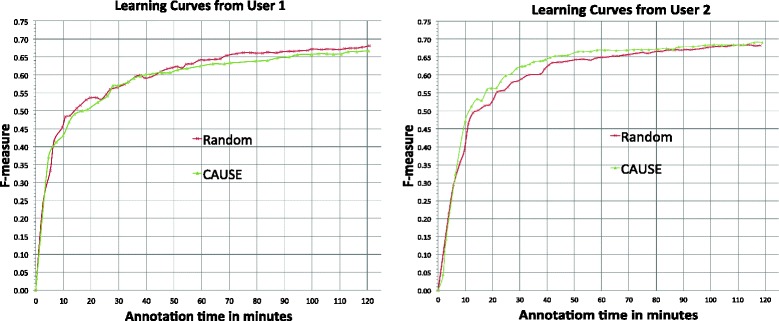
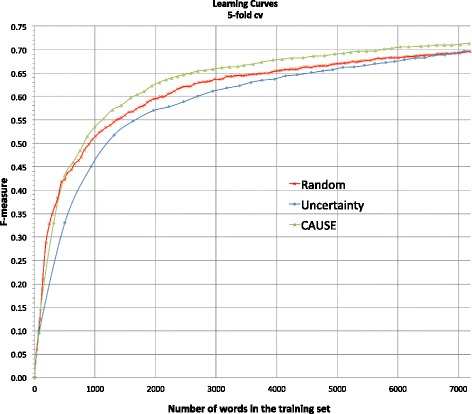
The simulation results show that the novel AL algorithm outperformed traditional AL algorithm and random sampling. However, the user study tells a different story that AL methods did not always perform better than random sampling for different users.
We found that the increased information content of actively selected sentences is strongly offset by the increased time required to annotate them. Moreover, the annotation time was not considered in the querying algorithms. Our future work includes developing better AL algorithms with the estimation of annotation time and evaluating the system with larger number of users.
主动学习(AL)已显示出在构建统计自然语言处理(NLP)模型时具有减少注释成本和最大化性能的巨大潜力。然而,很少有研究在医学领域的实际环境中研究 AL。
在这项研究中,我们开发了第一个具有新颖 AL 算法的用于临床命名实体识别(NER)的 AL 启用注释系统。除了对新型 AL 算法进行模拟研究以评估其性能外,我们还进一步让两名护士使用该系统进行用户研究,以评估 AL 在真实世界的注释过程中构建临床 NER 模型的性能。
模拟结果表明,新型 AL 算法优于传统的 AL 算法和随机抽样。然而,用户研究告诉我们一个不同的故事,即对于不同的用户,AL 方法并不总是比随机抽样表现更好。
我们发现,主动选择的句子的信息量增加被注释所需的时间增加所抵消。此外,查询算法中没有考虑注释时间。我们未来的工作包括开发更好的 AL 算法,同时考虑注释时间,并使用更多的用户来评估该系统。