Altschul Stephen F, Neuwald Andrew F
1 National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health , Bethesda, Maryland.
2 Department of Biochemistry and Molecular Biology, Institute for Genome Sciences, University of Maryland School of Medicine , Baltimore, Maryland.
J Comput Biol. 2018 Feb;25(2):121-129. doi: 10.1089/cmb.2017.0050. Epub 2017 Aug 3.
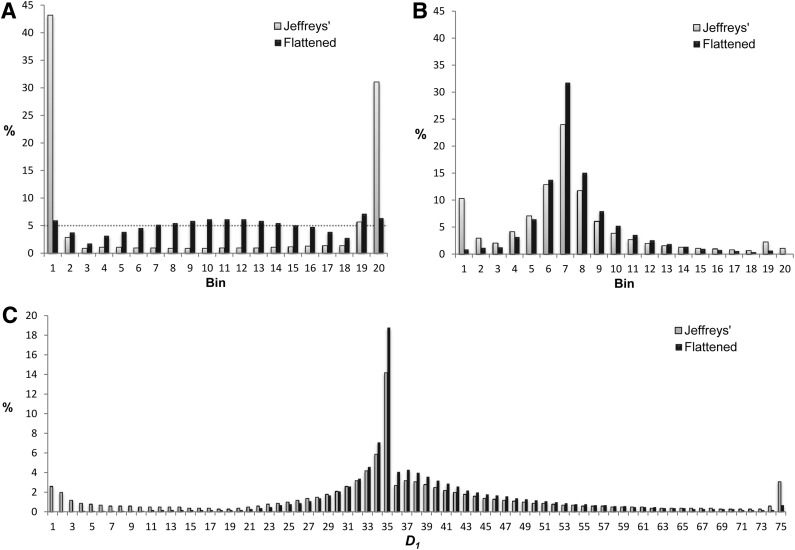
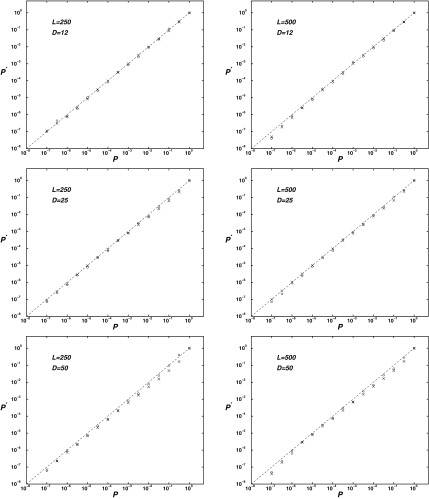
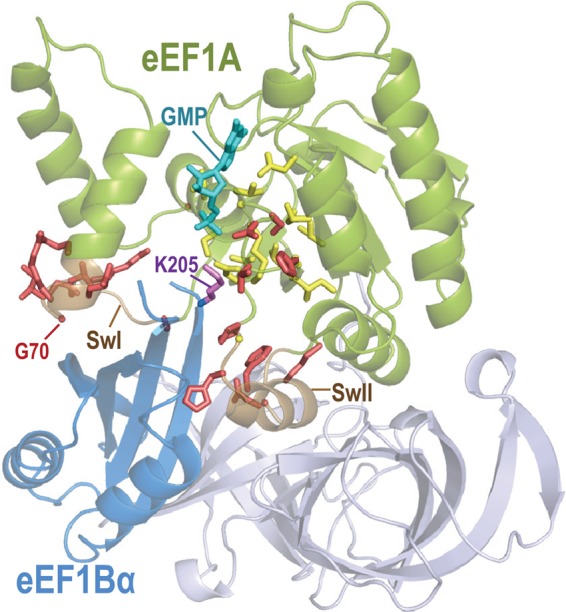
We study a simple abstract problem motivated by a variety of applications in protein sequence analysis. Consider a string of 0s and 1s of length L, and containing D 1s. If we believe that some or all of the 1s may be clustered near the start of the sequence, which subset is the most significantly so clustered, and how significant is this clustering? We approach this question using the minimum description length principle and illustrate its application by analyzing residues that distinguish translational initiation and elongation factor guanosine triphosphatases (GTPases) from other P-loop GTPases. Within a structure of yeast elongation factor 1[Formula: see text], these residues form a significant cluster centered on a region implicated in guanine nucleotide exchange. Various biomedical questions may be cast as the abstract problem considered here.
我们研究了一个由蛋白质序列分析中的各种应用所引发的简单抽象问题。考虑一个长度为L且包含D个1的0和1组成的字符串。如果我们认为部分或所有的1可能聚集在序列开头附近,那么哪个子集的聚集最为显著,以及这种聚集的显著程度如何?我们使用最小描述长度原理来处理这个问题,并通过分析区分翻译起始因子和延伸因子鸟苷三磷酸酶(GTPases)与其他P环GTPases的残基来说明其应用。在酵母延伸因子1的结构中,这些残基形成了一个以与鸟嘌呤核苷酸交换相关的区域为中心的显著簇。各种生物医学问题都可以归结为此处考虑的抽象问题。