Department of Biochemistry and Biomedical Sciences, McMaster University, 1280 Main St. W, Hamilton, Canada.
Department of Medicine, McMaster University, 1280 Main St. W, Hamilton, Canada.
Microbiome. 2017 Aug 14;5(1):100. doi: 10.1186/s40168-017-0314-2.
Advances in next-generation sequencing technologies have allowed for detailed, molecular-based studies of microbial communities such as the human gut, soil, and ocean waters. Sequencing of the 16S rRNA gene, specific to prokaryotes, using universal PCR primers has become a common approach to studying the composition of these microbiota. However, the bioinformatic processing of the resulting millions of DNA sequences can be challenging, and a standardized protocol would aid in reproducible analyses.
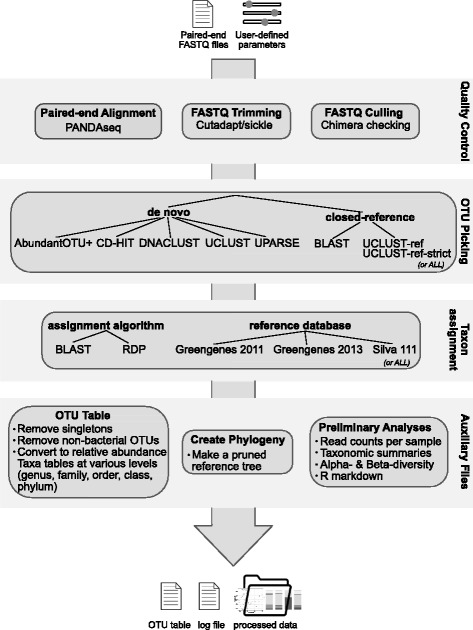
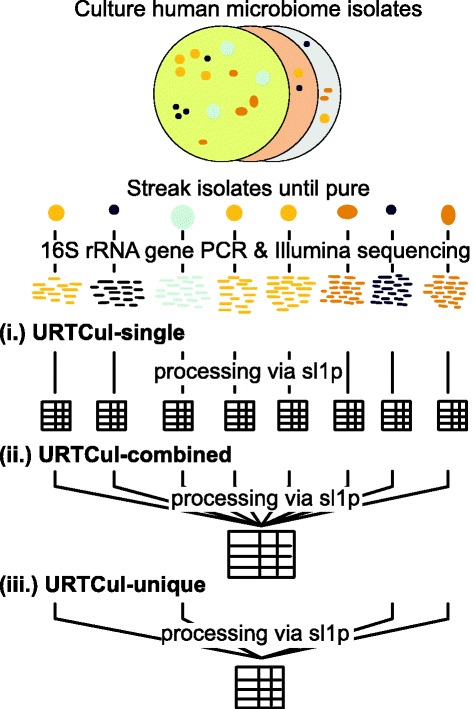
The short-read library 16S rRNA gene sequencing pipeline (sl1p, pronounced "slip") was designed with the purpose of mitigating this lack of reproducibility by combining pre-existing tools into a computational pipeline. This pipeline automates the processing of raw 16S rRNA gene sequencing data to create human-readable tables, graphs, and figures to make the collected data more readily accessible.
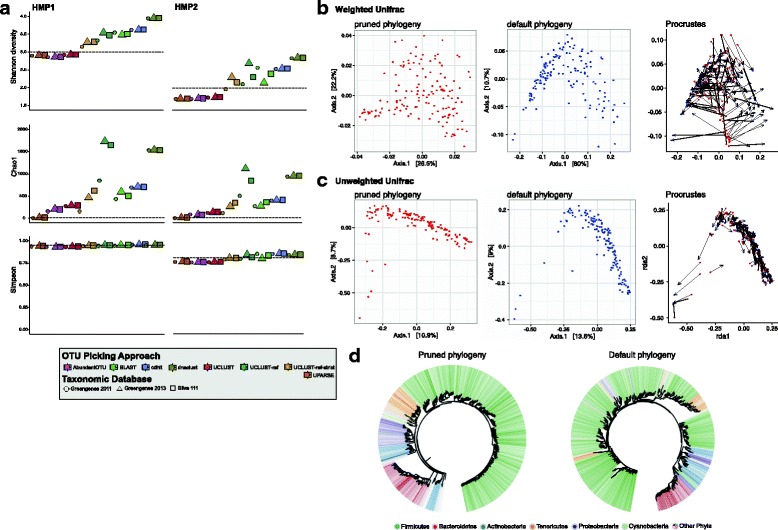
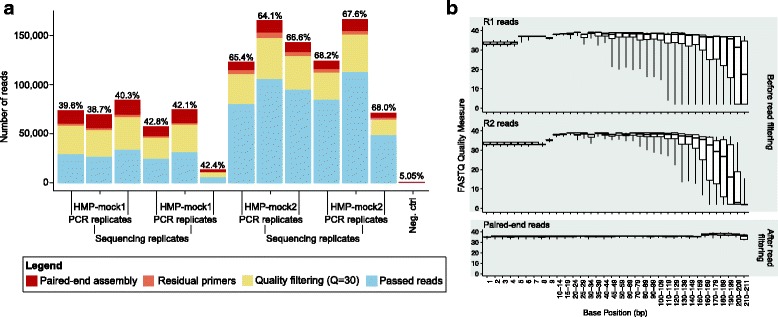
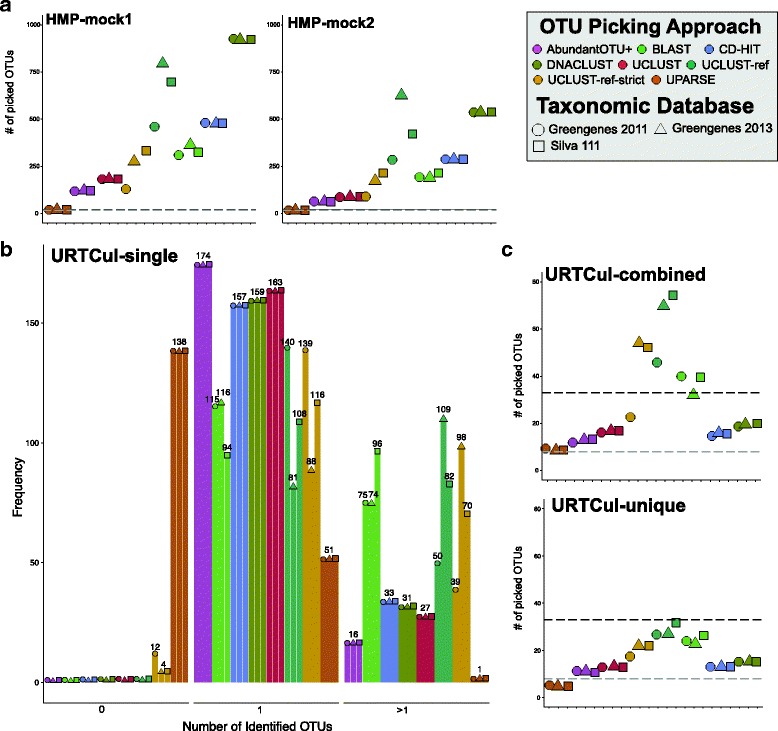
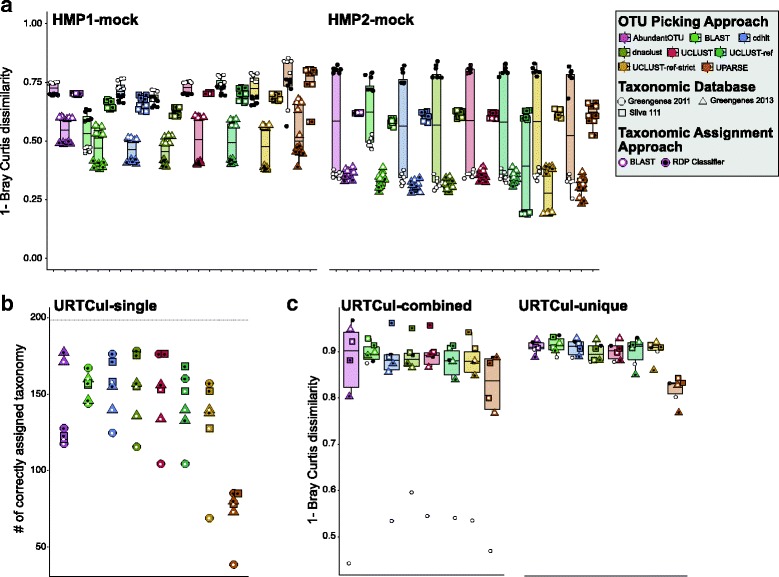
Data generated from mock communities were compared using eight OTU clustering algorithms, two taxon assignment approaches, and three 16S rRNA gene reference databases. While all of these algorithms and options are available to sl1p users, through testing with human-associated mock communities, AbundantOTU+, the RDP Classifier, and the Greengenes 2011 reference database were chosen as sl1p's defaults based on their ability to best represent the known input communities.
sl1p promotes reproducible research by providing a comprehensive log file, and reduces the computational knowledge needed by the user to process next-generation sequencing data. sl1p is freely available at https://bitbucket.org/fwhelan/sl1p .
下一代测序技术的进步使得对微生物群落(如人类肠道、土壤和海水)进行详细的基于分子的研究成为可能。使用通用 PCR 引物对 16S rRNA 基因(原核生物特有的)进行测序已成为研究这些微生物群落组成的常用方法。然而,处理由此产生的数百万个 DNA 序列的生物信息学可能具有挑战性,并且标准化协议将有助于可重复的分析。
短读文库 16S rRNA 基因测序管道(sl1p,发音为“slip”)旨在通过将现有工具组合到计算管道中,减轻这种缺乏可重复性的问题。该管道自动处理原始 16S rRNA 基因测序数据,以创建人类可读的表格、图表和图形,使收集的数据更容易访问。
使用八种 OTU 聚类算法、两种分类群分配方法和三种 16S rRNA 基因参考数据库对模拟群落生成的数据进行了比较。虽然所有这些算法和选项都可供 sl1p 用户使用,但通过与人类相关的模拟群落进行测试,AbundantOTU+、RDP 分类器和 Greengenes 2011 参考数据库被选为 sl1p 的默认选项,因为它们能够最好地代表已知的输入群落。
sl1p 通过提供全面的日志文件促进可重复的研究,并减少用户处理下一代测序数据所需的计算知识。sl1p 可在 https://bitbucket.org/fwhelan/sl1p 免费获得。