Matthé Maximilian, Sannolo Marco, Winiarski Kristopher, Spitzen-van der Sluijs Annemarieke, Goedbloed Daniel, Steinfartz Sebastian, Stachow Ulrich
Vodafone Chair Mobile Communication Systems Technical University Dresden Dresden Germany.
CIBIO, Research Centre in Biodiversity and Genetic Resources InBIO Universidade do Porto Campus de Vairão Vila do Conde Portugal.
Ecol Evol. 2017 Jul 10;7(15):5861-5872. doi: 10.1002/ece3.3140. eCollection 2017 Aug.
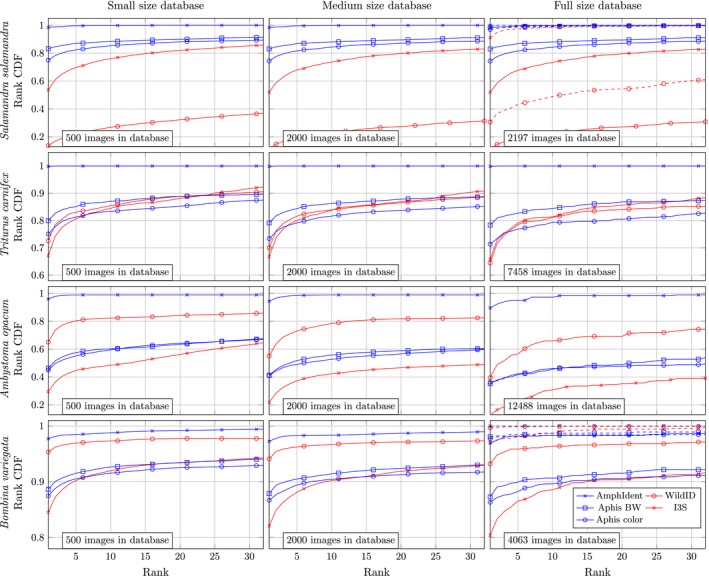
Photographic capture-recapture is a valuable tool for obtaining demographic information on wildlife populations due to its noninvasive nature and cost-effectiveness. Recently, several computer-aided photo-matching algorithms have been developed to more efficiently match images of unique individuals in databases with thousands of images. However, the identification accuracy of these algorithms can severely bias estimates of vital rates and population size. Therefore, it is important to understand the performance and limitations of state-of-the-art photo-matching algorithms prior to implementation in capture-recapture studies involving possibly thousands of images. Here, we compared the performance of four photo-matching algorithms; Wild-ID, I3S Pattern+, APHIS, and AmphIdent using multiple amphibian databases of varying image quality. We measured the performance of each algorithm and evaluated the performance in relation to database size and the number of matching images in the database. We found that algorithm performance differed greatly by algorithm and image database, with recognition rates ranging from 100% to 22.6% when limiting the review to the 10 highest ranking images. We found that recognition rate degraded marginally with increased database size and could be improved considerably with a higher number of matching images in the database. In our study, the pixel-based algorithm of AmphIdent exhibited superior recognition rates compared to the other approaches. We recommend carefully evaluating algorithm performance prior to using it to match a complete database. By choosing a suitable matching algorithm, databases of sizes that are unfeasible to match "by eye" can be easily translated to accurate individual capture histories necessary for robust demographic estimates.
由于其非侵入性和成本效益,摄影捕获-再捕获是获取野生动物种群人口统计信息的一种有价值的工具。最近,已经开发了几种计算机辅助的照片匹配算法,以便更有效地将数据库中独特个体的图像与数千张图像进行匹配。然而,这些算法的识别准确性可能会严重偏差对生命率和种群规模的估计。因此,在涉及可能数千张图像的捕获-再捕获研究中实施之前,了解最先进的照片匹配算法的性能和局限性非常重要。在这里,我们使用多个不同图像质量的两栖动物数据库比较了四种照片匹配算法(Wild-ID、I3S Pattern+、APHIS和AmphIdent)的性能。我们测量了每种算法的性能,并评估了其与数据库大小和数据库中匹配图像数量相关的性能。我们发现,算法性能因算法和图像数据库的不同而有很大差异,当将审查限制在排名最高的10张图像时,识别率从100%到22.6%不等。我们发现,识别率随着数据库大小的增加而略有下降,并且随着数据库中匹配图像数量的增加可以得到显著提高。在我们的研究中,与其他方法相比,基于像素的AmphIdent算法表现出更高的识别率。我们建议在使用算法匹配完整数据库之前仔细评估算法性能。通过选择合适的匹配算法,可以轻松地将“凭肉眼”无法匹配的大小的数据库转化为进行可靠的人口统计估计所需的准确个体捕获历史记录。