Wang Yubo, Ding Yijie, Guo Fei, Wei Leyi, Tang Jijun
School of Computer Science and Technology, Tianjin University, Tianjin 300350, China.
Tianjin University Institute of Computational Biology, Tianjin 300350, China.
PLoS One. 2017 Sep 29;12(9):e0185587. doi: 10.1371/journal.pone.0185587. eCollection 2017.
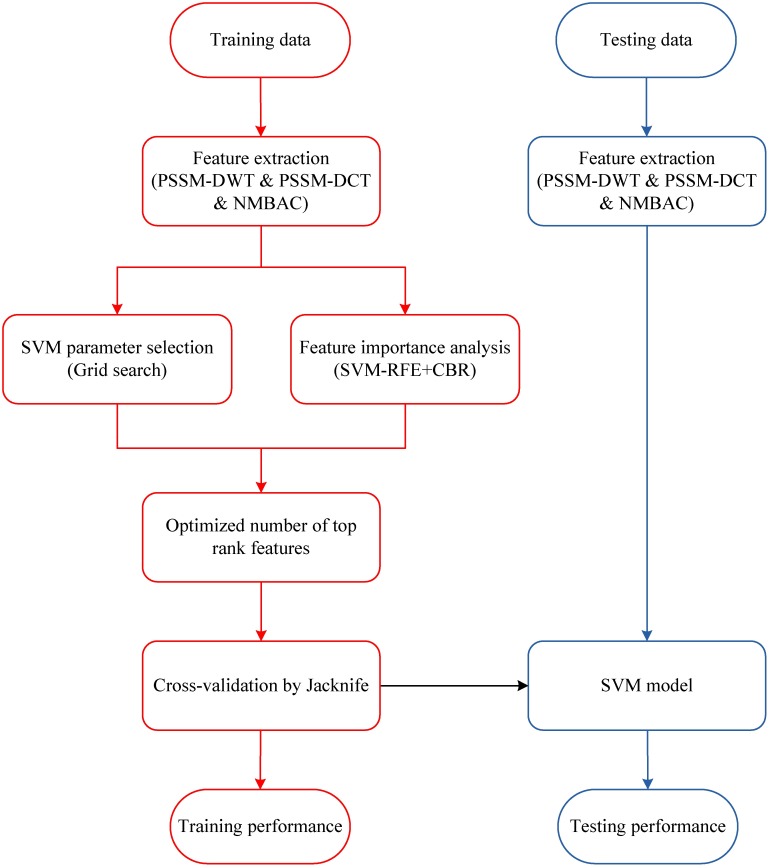
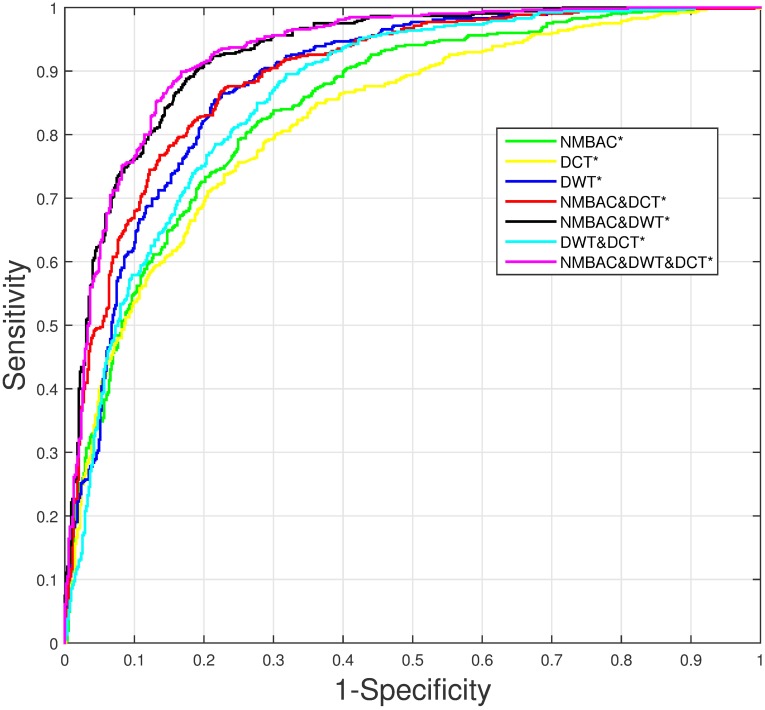
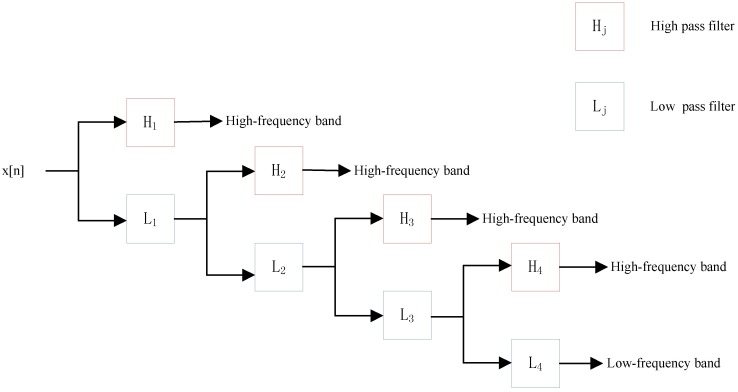
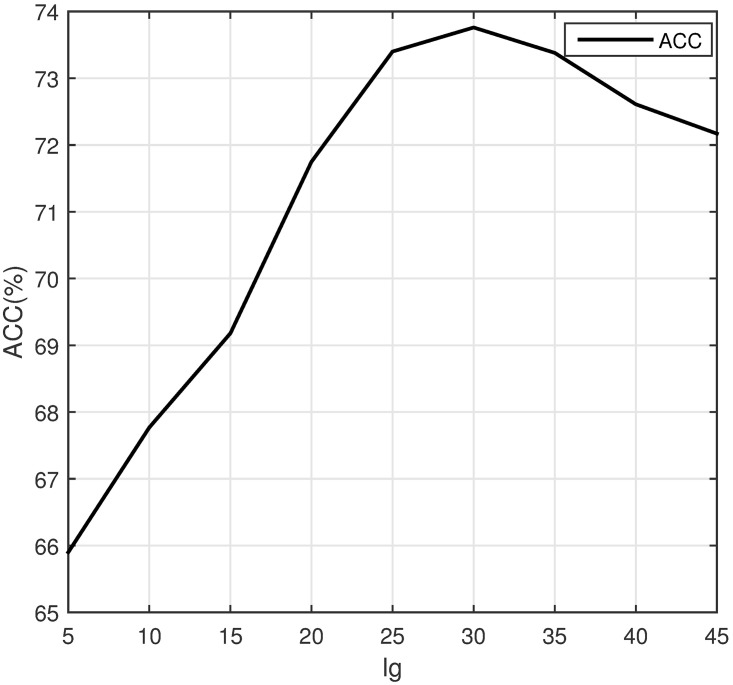
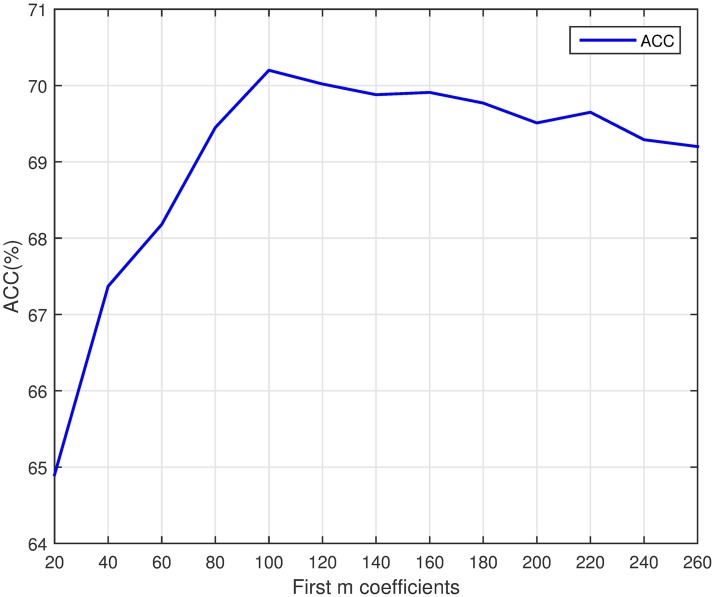
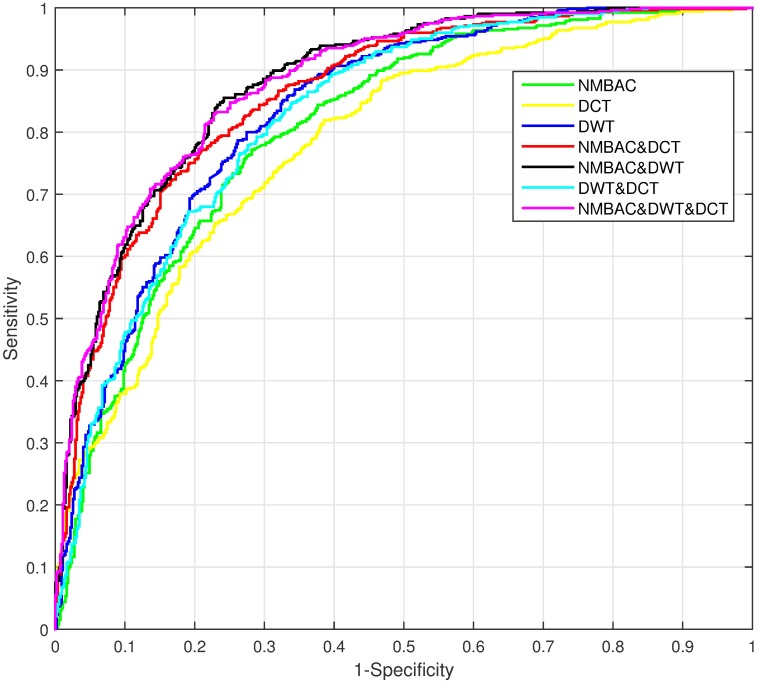
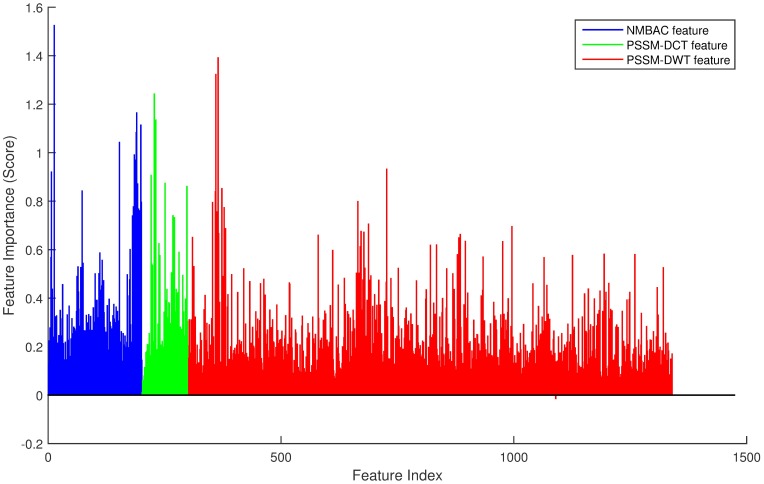
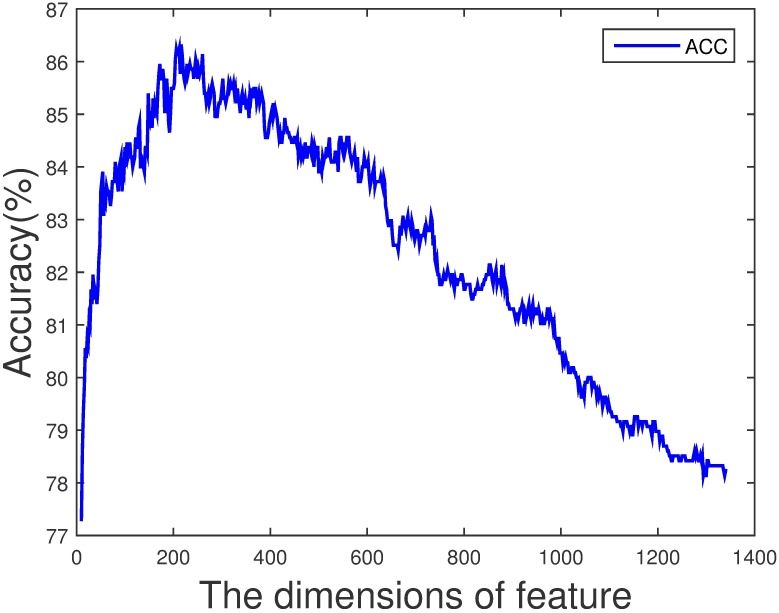
Since the importance of DNA-binding proteins in multiple biomolecular functions has been recognized, an increasing number of researchers are attempting to identify DNA-binding proteins. In recent years, the machine learning methods have become more and more compelling in the case of protein sequence data soaring, because of their favorable speed and accuracy. In this paper, we extract three features from the protein sequence, namely NMBAC (Normalized Moreau-Broto Autocorrelation), PSSM-DWT (Position-specific scoring matrix-Discrete Wavelet Transform), and PSSM-DCT (Position-specific scoring matrix-Discrete Cosine Transform). We also employ feature selection algorithm on these feature vectors. Then, these features are fed into the training SVM (support vector machine) model as classifier to predict DNA-binding proteins. Our method applys three datasets, namely PDB1075, PDB594 and PDB186, to evaluate the performance of our approach. The PDB1075 and PDB594 datasets are employed for Jackknife test and the PDB186 dataset is used for the independent test. Our method achieves the best accuracy in the Jacknife test, from 79.20% to 86.23% and 80.5% to 86.20% on PDB1075 and PDB594 datasets, respectively. In the independent test, the accuracy of our method comes to 76.3%. The performance of independent test also shows that our method has a certain ability to be effectively used for DNA-binding protein prediction. The data and source code are at https://doi.org/10.6084/m9.figshare.5104084.
由于DNA结合蛋白在多种生物分子功能中的重要性已得到认可,越来越多的研究人员试图鉴定DNA结合蛋白。近年来,随着蛋白质序列数据的激增,机器学习方法因其良好的速度和准确性而变得越来越有吸引力。在本文中,我们从蛋白质序列中提取了三个特征,即归一化莫罗-布罗托自相关(NMBAC)、位置特异性评分矩阵-离散小波变换(PSSM-DWT)和位置特异性评分矩阵-离散余弦变换(PSSM-DCT)。我们还对这些特征向量采用了特征选择算法。然后,将这些特征输入到作为分类器的训练支持向量机(SVM)模型中,以预测DNA结合蛋白。我们的方法应用了三个数据集,即PDB1075、PDB594和PDB186,来评估我们方法的性能。PDB1075和PDB594数据集用于留一法检验,PDB186数据集用于独立检验。我们的方法在留一法检验中取得了最佳准确率,在PDB1075和PDB594数据集上分别为79.20%至86.23%和80.5%至86.20%。在独立检验中,我们方法的准确率达到了76.3%。独立检验的性能也表明我们的方法具有一定的有效用于DNA结合蛋白预测的能力。数据和源代码位于https://doi.org/10.6084/m9.figshare.5104084 。