Zhou Jiyun, Lu Qin, Xu Ruifeng, He Yulan, Wang Hongpeng
School of Computer Science and Technology, Harbin Institute of Technology Shenzhen Graduate School, HIT Campus Shenzhen University Town, Xili, Shenzhen, Guangdong, 518055, China.
Department of Computing, the Hong Kong Polytechnic University, Kowloon, Hong Kong.
BMC Bioinformatics. 2017 Aug 29;18(1):379. doi: 10.1186/s12859-017-1792-8.
Prediction of DNA-binding residue is important for understanding the protein-DNA recognition mechanism. Many computational methods have been proposed for the prediction, but most of them do not consider the relationships of evolutionary information between residues.
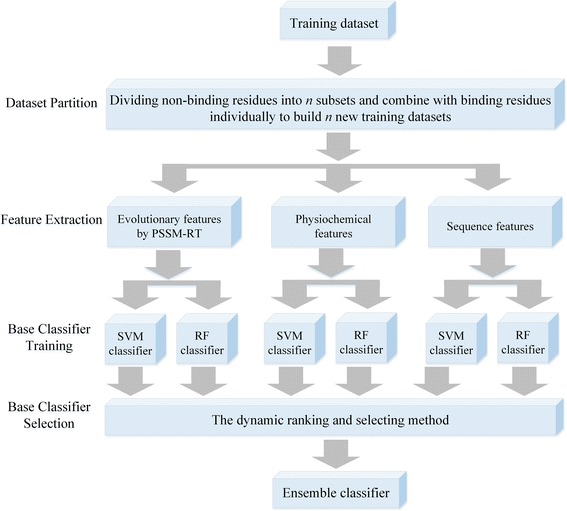
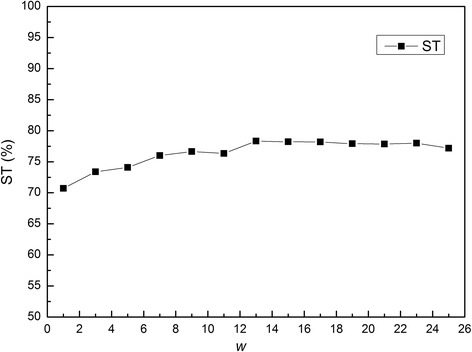
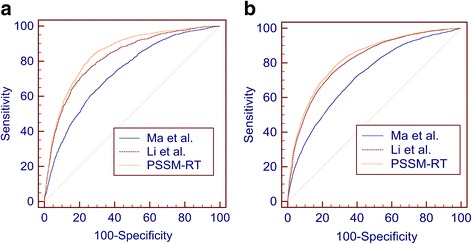
In this paper, we first propose a novel residue encoding method, referred to as the Position Specific Score Matrix (PSSM) Relation Transformation (PSSM-RT), to encode residues by utilizing the relationships of evolutionary information between residues. PDNA-62 and PDNA-224 are used to evaluate PSSM-RT and two existing PSSM encoding methods by five-fold cross-validation. Performance evaluations indicate that PSSM-RT is more effective than previous methods. This validates the point that the relationship of evolutionary information between residues is indeed useful in DNA-binding residue prediction. An ensemble learning classifier (EL_PSSM-RT) is also proposed by combining ensemble learning model and PSSM-RT to better handle the imbalance between binding and non-binding residues in datasets. EL_PSSM-RT is evaluated by five-fold cross-validation using PDNA-62 and PDNA-224 as well as two independent datasets TS-72 and TS-61. Performance comparisons with existing predictors on the four datasets demonstrate that EL_PSSM-RT is the best-performing method among all the predicting methods with improvement between 0.02-0.07 for MCC, 4.18-21.47% for ST and 0.013-0.131 for AUC. Furthermore, we analyze the importance of the pair-relationships extracted by PSSM-RT and the results validates the usefulness of PSSM-RT for encoding DNA-binding residues.
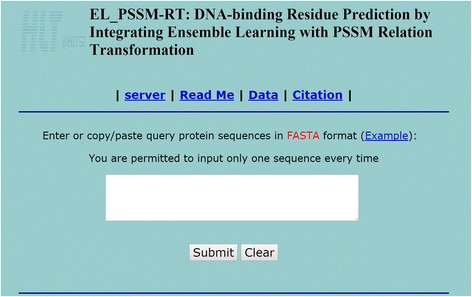
We propose a novel prediction method for the prediction of DNA-binding residue with the inclusion of relationship of evolutionary information and ensemble learning. Performance evaluation shows that the relationship of evolutionary information between residues is indeed useful in DNA-binding residue prediction and ensemble learning can be used to address the data imbalance issue between binding and non-binding residues. A web service of EL_PSSM-RT ( http://hlt.hitsz.edu.cn:8080/PSSM-RT_SVM/ ) is provided for free access to the biological research community.
预测DNA结合残基对于理解蛋白质-DNA识别机制很重要。已经提出了许多用于预测的计算方法,但其中大多数没有考虑残基之间进化信息的关系。
在本文中,我们首先提出了一种新颖的残基编码方法,称为位置特异性得分矩阵(PSSM)关系变换(PSSM-RT),通过利用残基之间进化信息的关系来编码残基。使用PDNA-62和PDNA-224通过五折交叉验证来评估PSSM-RT和两种现有的PSSM编码方法。性能评估表明,PSSM-RT比以前的方法更有效。这证实了残基之间进化信息的关系在DNA结合残基预测中确实有用这一观点。还通过结合集成学习模型和PSSM-RT提出了一种集成学习分类器(EL_PSSM-RT),以更好地处理数据集中结合和非结合残基之间的不平衡。使用PDNA-62和PDNA-224以及两个独立数据集TS-72和TS-61通过五折交叉验证对EL_PSSM-RT进行评估。在这四个数据集上与现有预测器的性能比较表明,EL_PSSM-RT是所有预测方法中性能最佳的方法,马修斯相关系数(MCC)提高了0.02 - 0.07,敏感度(ST)提高了4.18 - 21.47%,曲线下面积(AUC)提高了0.013 - 0.131。此外,我们分析了PSSM-RT提取的配对关系的重要性,结果证实了PSSM-RT对编码DNA结合残基的有用性。
我们提出了一种新颖的预测方法,用于预测包含进化信息关系和集成学习的DNA结合残基。性能评估表明,残基之间的进化信息关系在DNA结合残基预测中确实有用,并且集成学习可用于解决结合和非结合残基之间的数据不平衡问题。提供了EL_PSSM-RT的网络服务(http://hlt.hitsz.edu.cn:8080/PSSM-RT_SVM/),供生物研究界免费使用。