a Department of Psychology , University of California , Los Angeles.
b Division of General Internal Medicine & Health Services Research , University of California , Los Angeles.
J Pers Assess. 2018 Jul-Aug;100(4):363-374. doi: 10.1080/00223891.2017.1381969. Epub 2017 Oct 31.
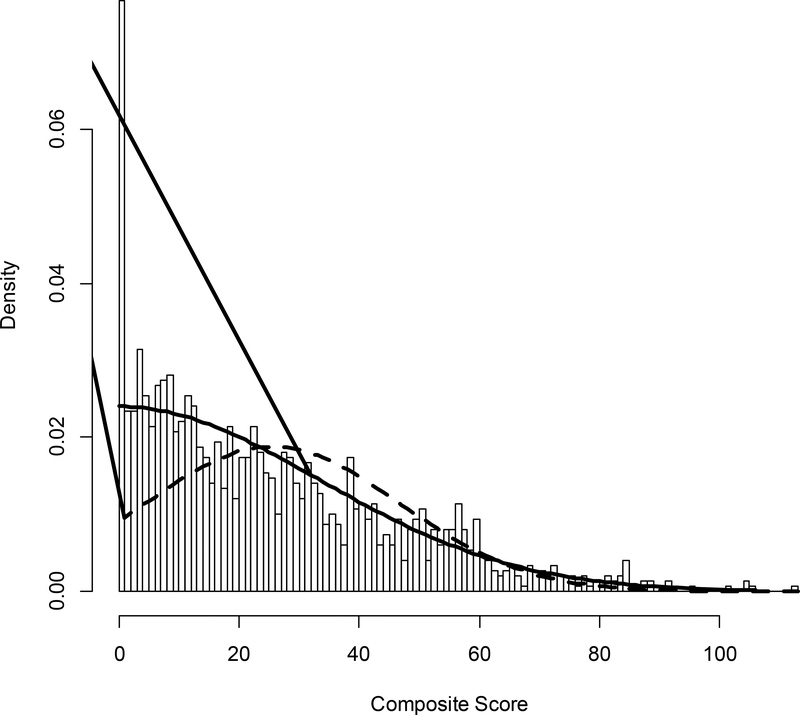
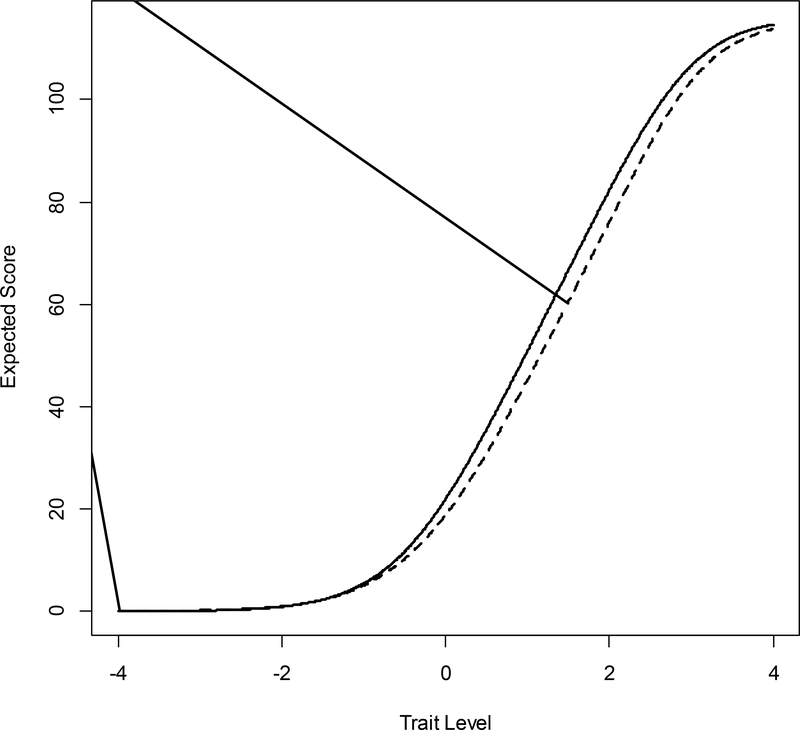
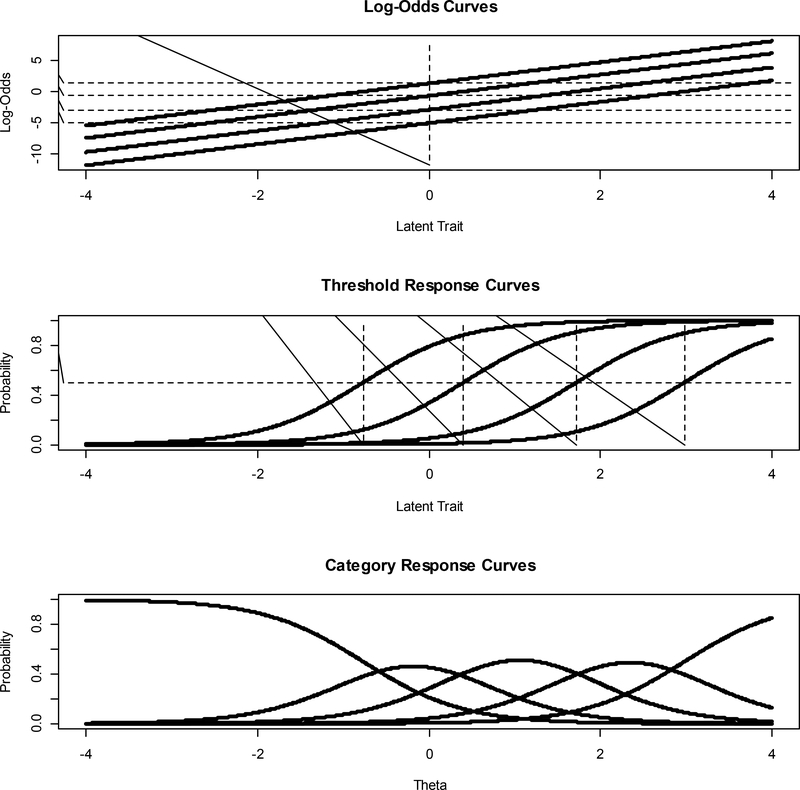
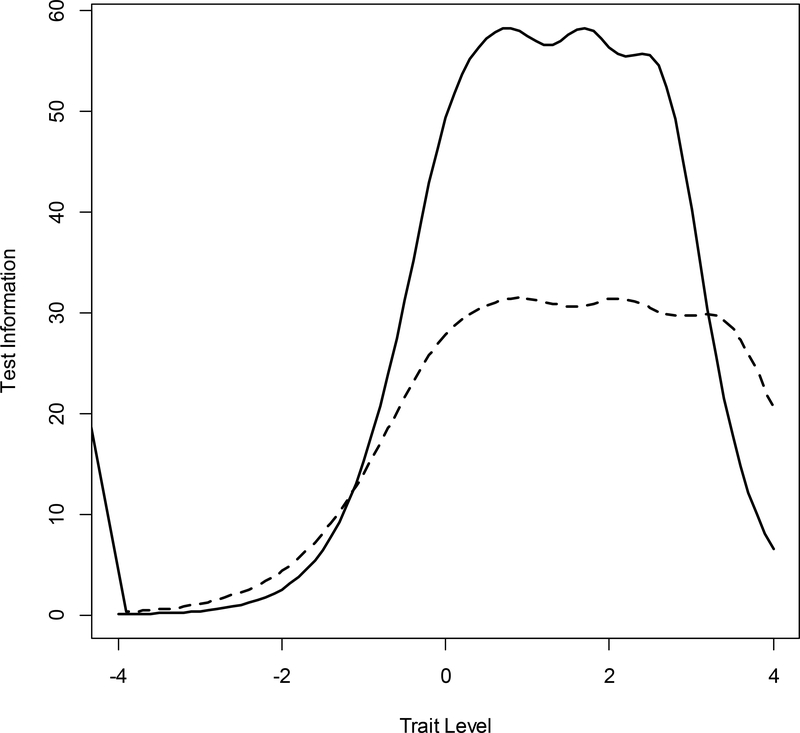
It is generally assumed that the latent trait is normally distributed in the population when estimating logistic item response theory (IRT) model parameters. This assumption requires that the latent trait be fully continuous and the population homogenous (i.e., not a mixture). When this normality assumption is violated, models are misspecified, and item and person parameter estimates are inaccurate. When normality cannot be assumed, it might be appropriate to consider alternative modeling approaches: (a) a zero-inflated mixture, (b) a log-logistic, (c) a Ramsay curve, or (d) a heteroskedastic-skew model. The first 2 models were developed to address modeling problems associated with so-called quasi-continuous or unipolar constructs, which apply only to a subset of the population, or are meaningful at one end of the continuum only. The second 2 models were developed to address non-normal latent trait distributions and violations of homogeneity of error variance, respectively. To introduce these alternative IRT models and illustrate their strengths and weaknesses, we performed real data application comparing results to those from a graded response model. We review both statistical and theoretical challenges in applying these models and choosing among them. Future applications of these and other alternative models (e.g., unfolding, diffusion) are needed to advance understanding about model choice in particular situations.
通常假设在估计逻辑斯蒂项目反应理论 (IRT) 模型参数时,潜特质在总体中呈正态分布。该假设要求潜特质是完全连续的,且总体是同质的(即不是混合的)。当这种正态性假设被违反时,模型就会被错误指定,项目和个体参数估计也会不准确。当不能假设正态性时,考虑替代建模方法可能是合适的:(a) 零膨胀混合模型,(b) 对数逻辑模型,(c) Ramsay 曲线模型,或 (d) 异方差偏态模型。前 2 个模型是为了解决与所谓的准连续或单极结构相关的建模问题而开发的,这些问题仅适用于总体的一部分,或者仅在连续体的一端才有意义。后 2 个模型是为了解决非正态潜特质分布和误差方差同质性的违反问题而开发的。为了介绍这些替代 IRT 模型并说明它们的优缺点,我们进行了真实数据应用,将结果与等级反应模型的结果进行了比较。我们回顾了在应用这些模型和选择这些模型时遇到的统计和理论挑战。需要进一步应用这些和其他替代模型(例如,展开模型、扩散模型),以提高对特定情况下模型选择的理解。