Division of Biostatistics, Department of Public Health Sciences, University of Miami, Florida, USA.
Sylvester Comprehensive Cancer Center, University of Miami, Florida, USA.
Sci Rep. 2017 Nov 9;7(1):15169. doi: 10.1038/s41598-017-15590-4.
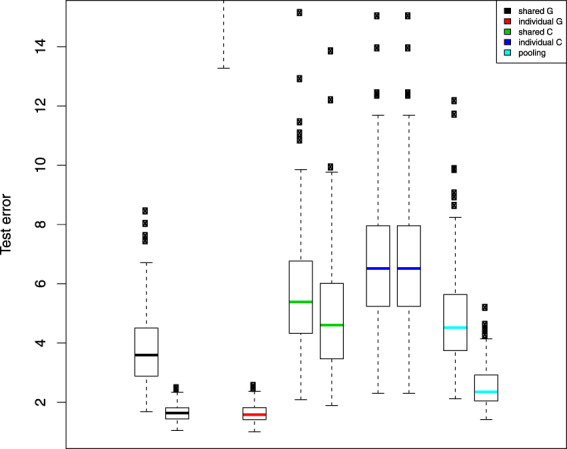
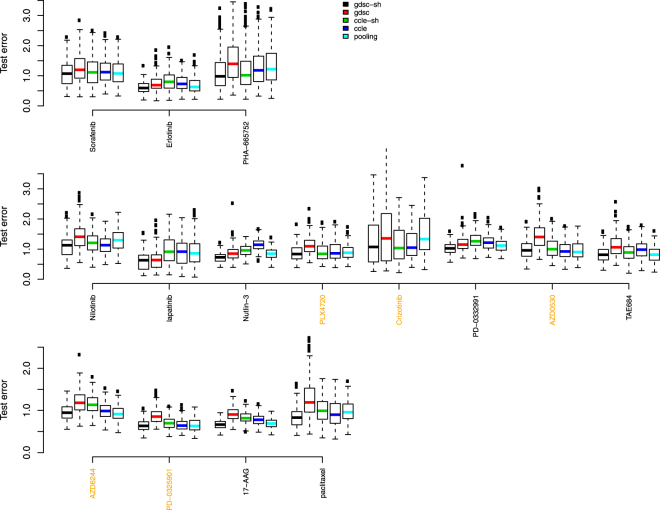
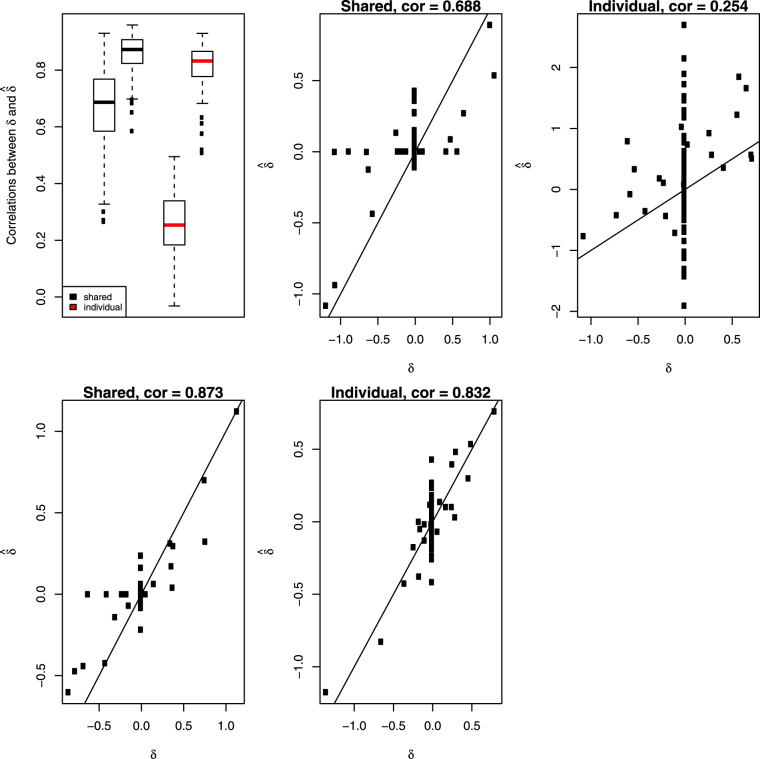
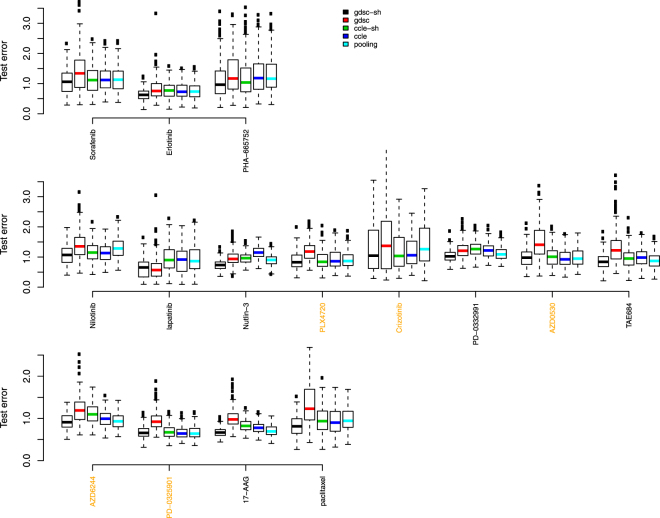
The Genomics of Drug Sensitivity in Cancer (GDSC) and Cancer Cell Line Encyclopedia (CCLE) are two major studies that can be used to mine for therapeutic biomarkers for cancers of a large variety. Model validation using the two datasets however has proved challenging. Both predictions and signatures do not consistently validate well for models built on one dataset and tested on the other. While the genomic profiling seems consistent, the drug response data is not. Some efforts at harmonizing experimental designs has helped but not entirely removed model validation difficulties. In this paper, we present a partitioning strategy based on a data sharing concept which directly acknowledges a potential lack of concordance between datasets and in doing so, also allows for extraction of reproducible novel gene-drug interaction signatures as well as accurate test set predictions. We demonstrate these properties in a re-analysis of the GDSC and CCLE datasets.
癌症药物敏感性基因组学(GDSC)和癌症细胞系百科全书(CCLE)是两项主要的研究,可以用来挖掘多种癌症的治疗生物标志物。然而,使用这两个数据集进行模型验证具有挑战性。在一个数据集上构建的模型在另一个数据集上进行测试时,预测和特征并不总是能很好地验证。虽然基因组分析似乎是一致的,但药物反应数据却不一致。一些协调实验设计的努力有所帮助,但并没有完全消除模型验证的困难。在本文中,我们提出了一种基于数据共享概念的分区策略,该策略直接承认数据集之间可能存在不一致性,并且这样做还允许提取可重复的新基因-药物相互作用特征以及准确的测试集预测。我们在对 GDSC 和 CCLE 数据集的重新分析中证明了这些特性。