Olson Randal S, La Cava William, Orzechowski Patryk, Urbanowicz Ryan J, Moore Jason H
Institute for Biomedical Informatics, University of Pennsylvania, 3700 Hamilton Walk, Philadelphia, 19104 PA USA.
Department of Automatics and Biomedical Engineering, AGH University of Science and Technology, Kraków, Poland.
BioData Min. 2017 Dec 11;10:36. doi: 10.1186/s13040-017-0154-4. eCollection 2017.
The selection, development, or comparison of machine learning methods in data mining can be a difficult task based on the target problem and goals of a particular study. Numerous publicly available real-world and simulated benchmark datasets have emerged from different sources, but their organization and adoption as standards have been inconsistent. As such, selecting and curating specific benchmarks remains an unnecessary burden on machine learning practitioners and data scientists.
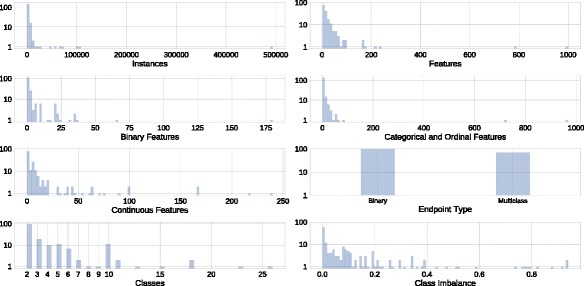
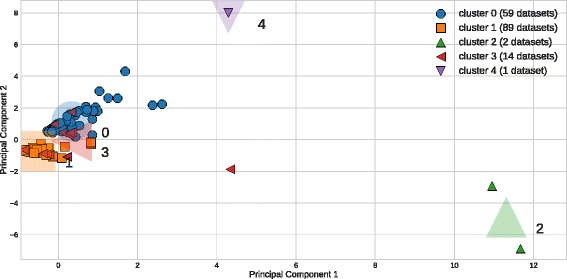
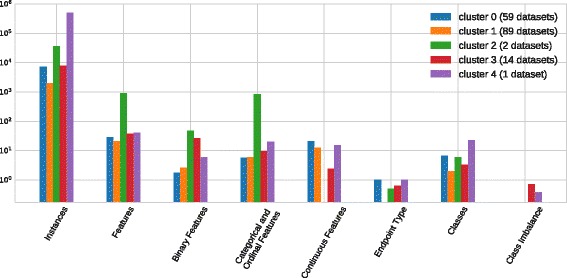
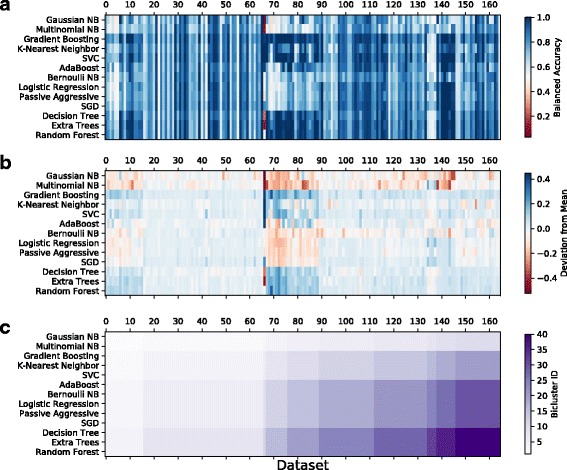
The present study introduces an accessible, curated, and developing public benchmark resource to facilitate identification of the strengths and weaknesses of different machine learning methodologies. We compare meta-features among the current set of benchmark datasets in this resource to characterize the diversity of available data. Finally, we apply a number of established machine learning methods to the entire benchmark suite and analyze how datasets and algorithms cluster in terms of performance. From this study, we find that existing benchmarks lack the diversity to properly benchmark machine learning algorithms, and there are several gaps in benchmarking problems that still need to be considered.
This work represents another important step towards understanding the limitations of popular benchmarking suites and developing a resource that connects existing benchmarking standards to more diverse and efficient standards in the future.
基于特定研究的目标问题和目标,在数据挖掘中选择、开发或比较机器学习方法可能是一项艰巨的任务。众多来自不同来源的公开可用的真实世界和模拟基准数据集已经出现,但其组织和作为标准的采用一直不一致。因此,选择和策划特定的基准对机器学习从业者和数据科学家来说仍然是不必要的负担。
本研究引入了一个可访问、经过策划且不断发展的公共基准资源,以促进对不同机器学习方法优缺点的识别。我们比较了该资源中当前基准数据集的元特征,以描述可用数据的多样性。最后,我们将一些已建立的机器学习方法应用于整个基准套件,并分析数据集和算法在性能方面是如何聚类的。从这项研究中,我们发现现有基准缺乏适当基准化机器学习算法的多样性,并且在基准问题方面仍有几个差距需要考虑。
这项工作是朝着理解流行基准套件的局限性以及开发一种资源迈出的又一重要一步,该资源将在未来把现有的基准标准与更多样化和高效的标准联系起来。