Marcou Quentin, Mora Thierry, Walczak Aleksandra M
Laboratoire de Physique Théorique, CNRS, Sorbonne Université and École Normale Supérieure (PSL), 24, Rue Lhomond, 75005, Paris, France.
Laboratoire de Physique Statistique, CNRS, Sorbonne Université, Université Paris-Diderot, and École normale supérieure (PSL), 24, Rue Lhomond, 75005, Paris, France.
Nat Commun. 2018 Feb 8;9(1):561. doi: 10.1038/s41467-018-02832-w.
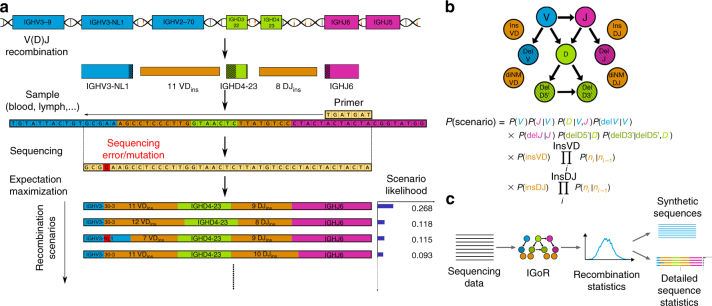
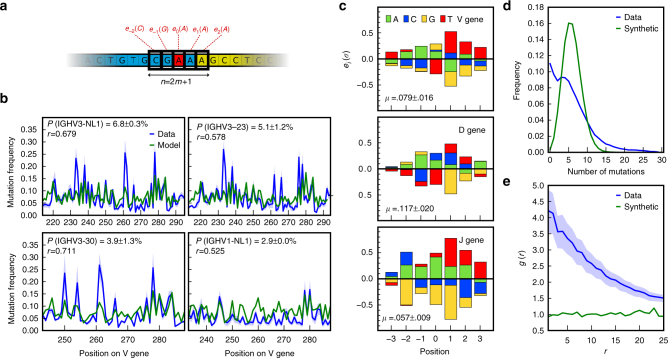
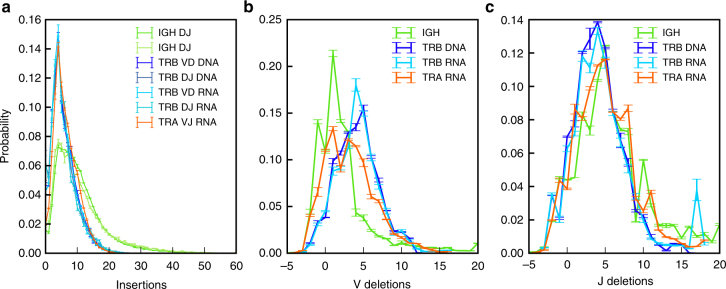
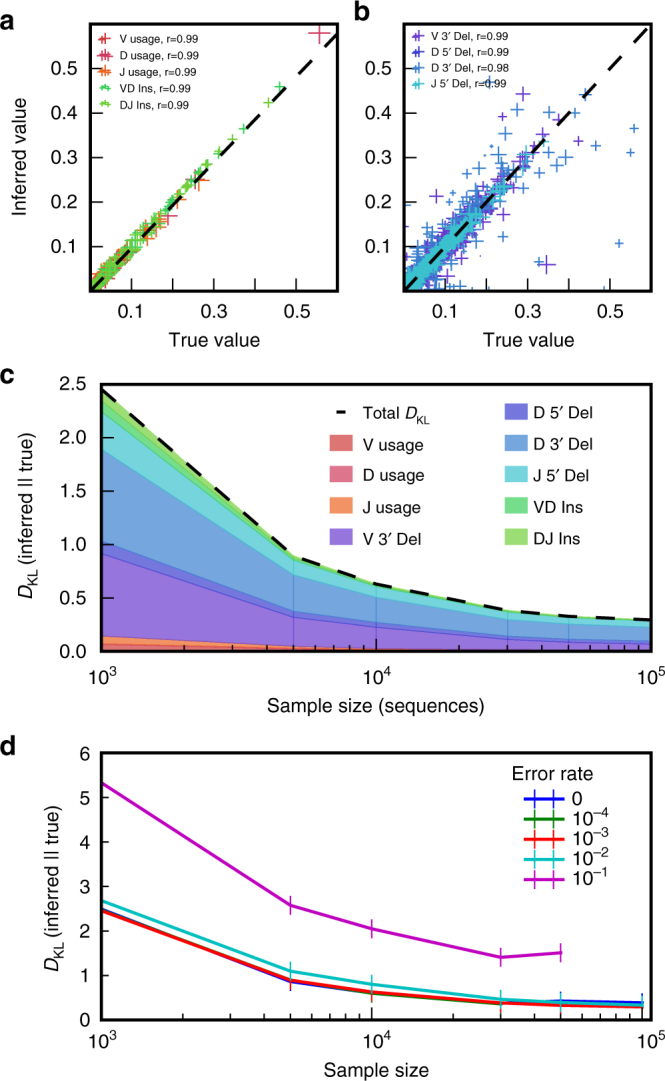
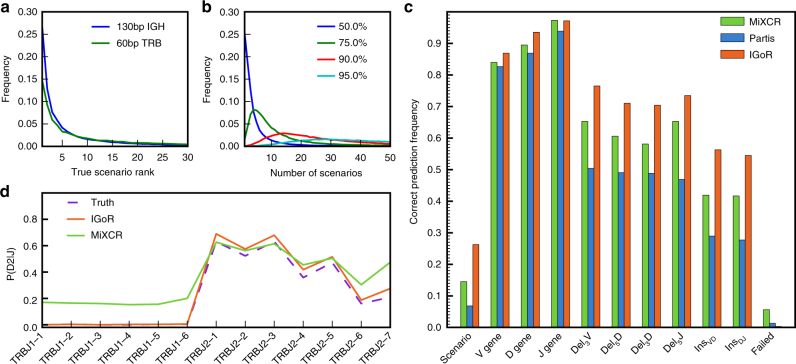
High-throughput immune repertoire sequencing is promising to lead to new statistical diagnostic tools for medicine and biology. Successful implementations of these methods require a correct characterization, analysis, and interpretation of these data sets. We present IGoR (Inference and Generation Of Repertoires)-a comprehensive tool that takes B or T cell receptor sequence reads and quantitatively characterizes the statistics of receptor generation from both cDNA and gDNA. It probabilistically annotates sequences and its modular structure can be used to investigate models of increasing biological complexity for different organisms. For B cells, IGoR returns the hypermutation statistics, which we use to reveal co-localization of hypermutations along the sequence. We demonstrate that IGoR outperforms existing tools in accuracy and estimate the sample sizes needed for reliable repertoire characterization.
高通量免疫组库测序有望催生医学和生物学领域新的统计诊断工具。这些方法的成功实施需要对这些数据集进行正确的表征、分析和解读。我们展示了IGoR(免疫组库的推断与生成)——一种综合工具,它能获取B细胞或T细胞受体序列读数,并从cDNA和gDNA定量表征受体生成的统计学特征。它能对序列进行概率注释,其模块化结构可用于研究不同生物体中生物复杂性不断增加的模型。对于B细胞,IGoR会返回超突变统计数据,我们用其揭示超突变沿序列的共定位情况。我们证明IGoR在准确性方面优于现有工具,并估计了可靠表征免疫组库所需的样本量。