Queensland Alliance for Agriculture and Food Innovation (QAAFI), The University of Queensland, St Lucia, Qld, Australia.
Western Highlands Agriculture & Forestry Science Institute (WASI), Buon Ma Thuot, Vietnam.
Plant Biotechnol J. 2018 Oct;16(10):1756-1766. doi: 10.1111/pbi.12912. Epub 2018 Apr 13.
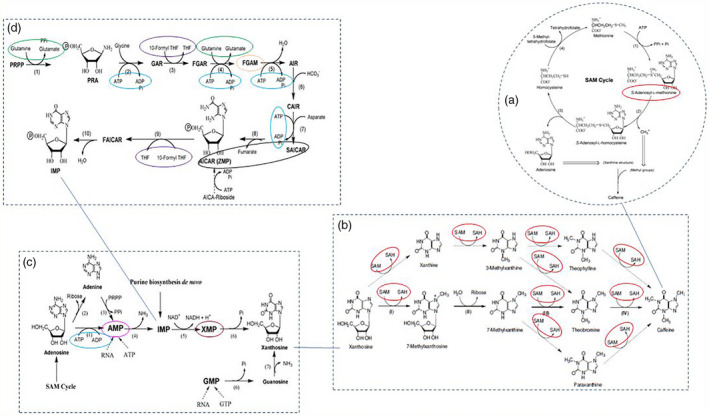
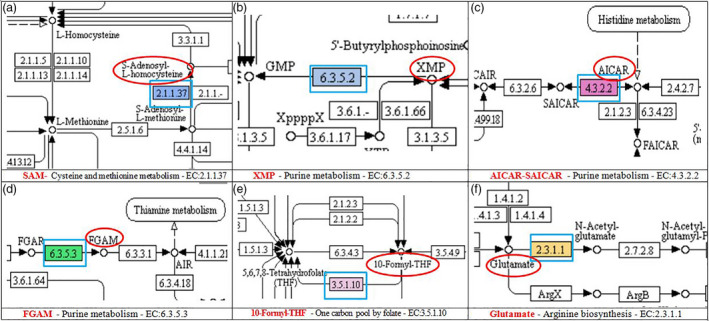
Arabica coffee (Coffea arabica) has a small gene pool limiting genetic improvement. Selection for caffeine content within this gene pool would be assisted by identification of the genes controlling this important trait. Sequencing of DNA bulks from 18 genotypes with extreme high- or low-caffeine content from a population of 232 genotypes was used to identify linked polymorphisms. To obtain a reference genome, a whole genome assembly of arabica coffee (variety K7) was achieved by sequencing using short read (Illumina) and long-read (PacBio) technology. Assembly was performed using a range of assembly tools resulting in 76 409 scaffolds with a scaffold N50 of 54 544 bp and a total scaffold length of 1448 Mb. Validation of the genome assembly using different tools showed high completeness of the genome. More than 99% of transcriptome sequences mapped to the C. arabica draft genome, and 89% of BUSCOs were present. The assembled genome annotated using AUGUSTUS yielded 99 829 gene models. Using the draft arabica genome as reference in mapping and variant calling allowed the detection of 1444 nonsynonymous single nucleotide polymorphisms (SNPs) associated with caffeine content. Based on Kyoto Encyclopaedia of Genes and Genomes pathway-based analysis, 65 caffeine-associated SNPs were discovered, among which 11 SNPs were associated with genes encoding enzymes involved in the conversion of substrates, which participate in the caffeine biosynthesis pathways. This analysis demonstrated the complex genetic control of this key trait in coffee.
阿拉比卡咖啡(Coffea arabica)的基因库较小,限制了其遗传改良。在这个基因库中选择咖啡因含量,可以通过鉴定控制这一重要性状的基因来辅助。从 232 个基因型的群体中,从 18 个具有极高或极低咖啡因含量的基因型中提取 DNA 进行测序,以鉴定连锁的多态性。为了获得参考基因组,使用短读(Illumina)和长读(PacBio)技术对阿拉比卡咖啡(品种 K7)进行了全基因组测序,实现了全基因组组装。使用一系列组装工具进行组装,得到了 76409 个支架,支架 N50 为 54544bp,总支架长度为 1448Mb。使用不同的工具对基因组组装进行验证,表明基因组的完整性很高。超过 99%的转录组序列映射到 C.arabica 草图基因组,并且存在 89%的 BUSCO。使用 AUGUSTUS 对组装的基因组进行注释,生成了 99829 个基因模型。使用阿拉比卡草图基因组作为参考进行映射和变异调用,检测到与咖啡因含量相关的 1444 个非同义单核苷酸多态性(SNP)。基于京都基因和基因组百科全书通路的分析,发现了 65 个与咖啡因含量相关的 SNP,其中 11 个 SNP 与编码参与底物转化的酶的基因有关,这些酶参与了咖啡因生物合成途径。这项分析表明,咖啡中这一关键性状的遗传控制非常复杂。