Queensland Alliance for Agriculture and Food Innovation, The University of Queensland, St Lucia, QLD 4072, Australia.
Gigascience. 2017 Nov 1;6(11):1-13. doi: 10.1093/gigascience/gix086.
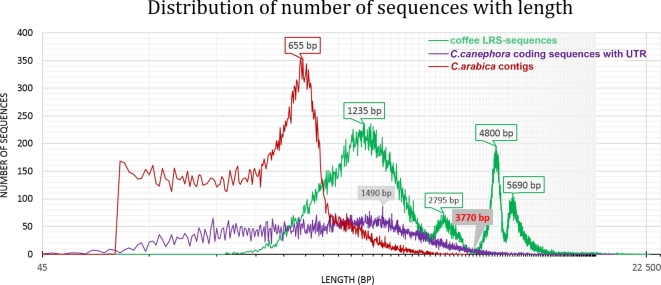
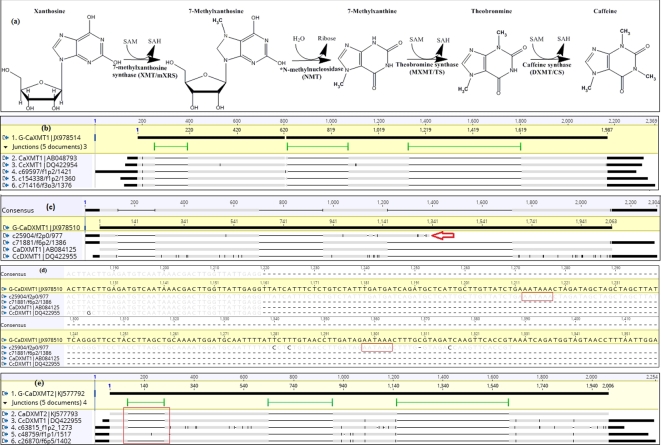
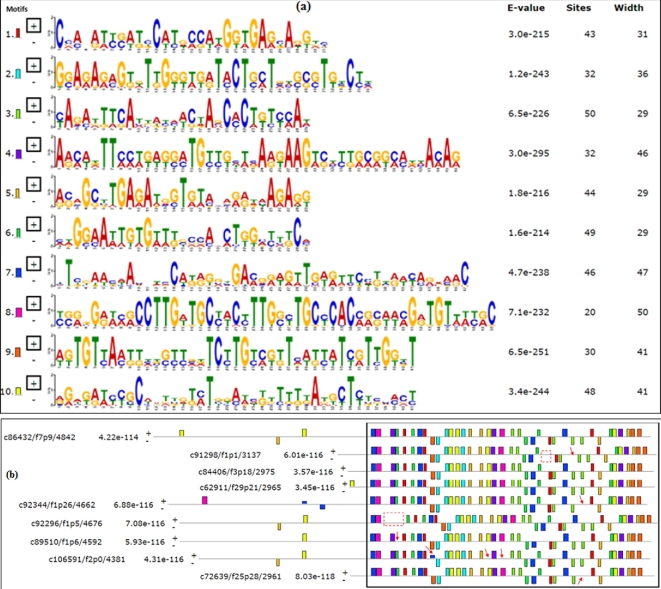
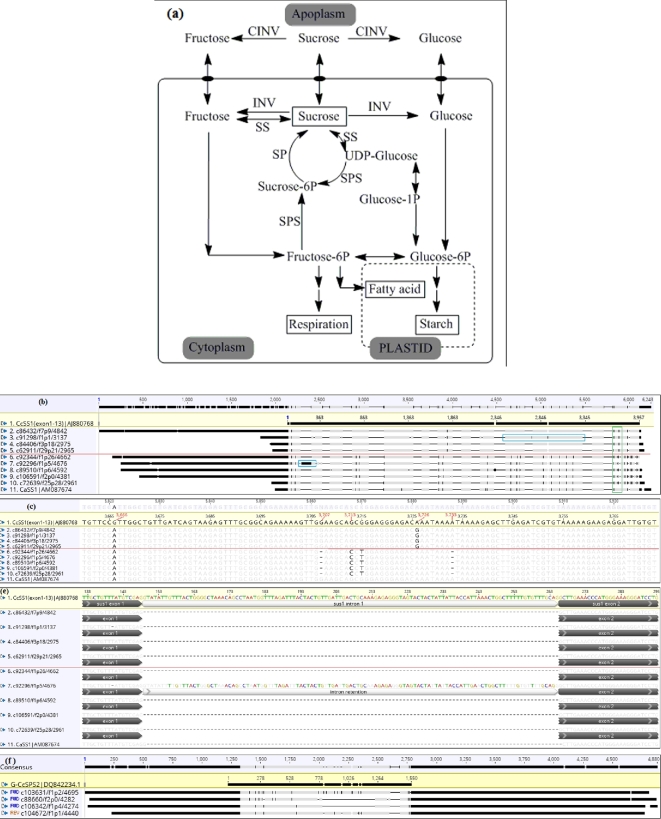
Polyploidization contributes to the complexity of gene expression, resulting in numerous related but different transcripts. This study explored the transcriptome diversity and complexity of the tetraploid Arabica coffee (Coffea arabica) bean. Long-read sequencing (LRS) by Pacbio Isoform sequencing (Iso-seq) was used to obtain full-length transcripts without the difficulty and uncertainty of assembly required for reads from short-read technologies. The tetraploid transcriptome was annotated and compared with data from the sub-genome progenitors. Caffeine and sucrose genes were targeted for case analysis. An isoform-level tetraploid coffee bean reference transcriptome with 95 995 distinct transcripts (average 3236 bp) was obtained. A total of 88 715 sequences (92.42%) were annotated with BLASTx against NCBI non-redundant plant proteins, including 34 719 high-quality annotations. Further BLASTn analysis against NCBI non-redundant nucleotide sequences, Coffea canephora coding sequences with UTR, C. arabica ESTs, and Rfam resulted in 1213 sequences without hits, were potential novel genes in coffee. Longer UTRs were captured, especially in the 5΄UTRs, facilitating the identification of upstream open reading frames. The LRS also revealed more and longer transcript variants in key caffeine and sucrose metabolism genes from this polyploid genome. Long sequences (>10 kilo base) were poorly annotated. LRS technology shows the limitation of previous studies. It provides an important tool to produce a reference transcriptome including more of the diversity of full-length transcripts to help understand the biology and support the genetic improvement of polyploid species such as coffee.
多倍化导致基因表达的复杂性增加,产生了许多相关但不同的转录本。本研究探讨了四倍体阿拉比卡咖啡豆(Coffea arabica)的转录组多样性和复杂性。通过 Pacbio Isoform sequencing(Iso-seq)进行长读测序(LRS),无需进行短读技术所需的组装困难和不确定性,即可获得全长转录本。对四倍体转录组进行注释,并与亚基因组祖先的数据进行比较。针对咖啡因和蔗糖基因进行了案例分析。获得了一个具有 95995 个独特转录本(平均长度 3236bp)的四倍体咖啡豆异质本参考转录组。共有 88715 个序列(92.42%)通过 BLASTx 与 NCBI 非冗余植物蛋白进行注释,其中包括 34719 个高质量注释。进一步通过 BLASTn 与 NCBI 非冗余核苷酸序列、Coffea canephora 编码序列的 UTR、C. arabica ESTs 和 Rfam 进行分析,有 1213 个序列没有匹配,可能是咖啡中的新基因。捕获了更长的 UTR,特别是在 5'UTR 中,有助于识别上游开放阅读框。LRS 还揭示了这个多倍体基因组中关键咖啡因和蔗糖代谢基因的更多和更长的转录变体。长序列(>10 千碱基)的注释较差。LRS 技术显示了先前研究的局限性。它提供了一个重要的工具来生成一个参考转录组,包括更多全长转录本的多样性,以帮助理解生物学,并支持咖啡等多倍体物种的遗传改良。