School of Biological Sciences, The University of Adelaide, Adelaide, SA 5005, Australia.
Evolutionary Biology Unit, South Australian Museum, Adelaide, SA 5005, Australia.
PLoS One. 2018 Mar 14;13(3):e0193588. doi: 10.1371/journal.pone.0193588. eCollection 2018.
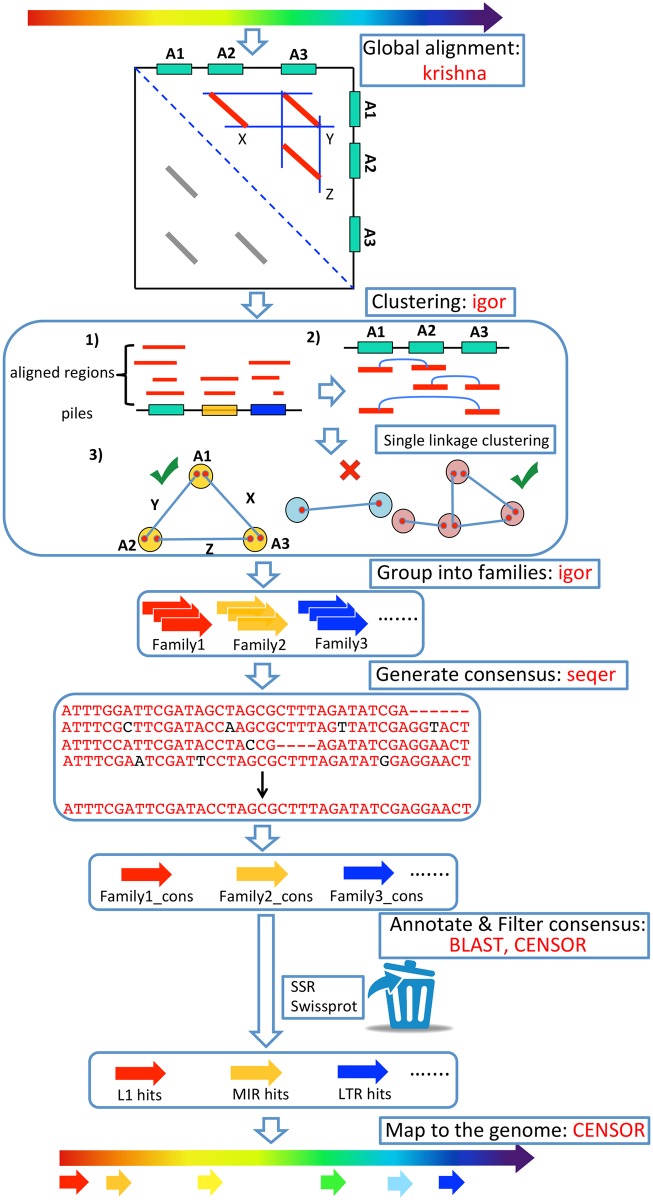
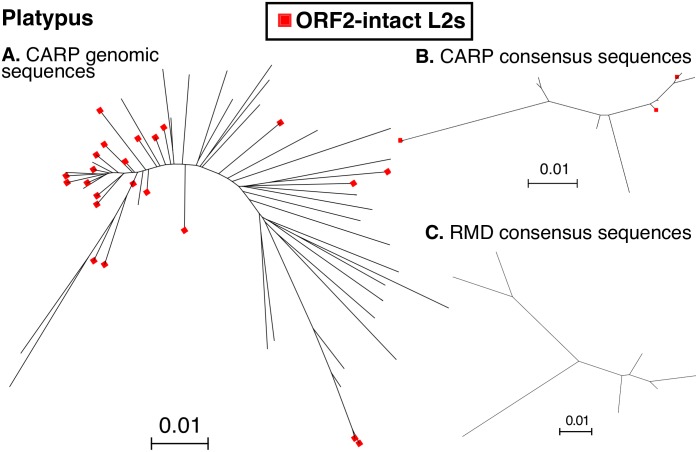
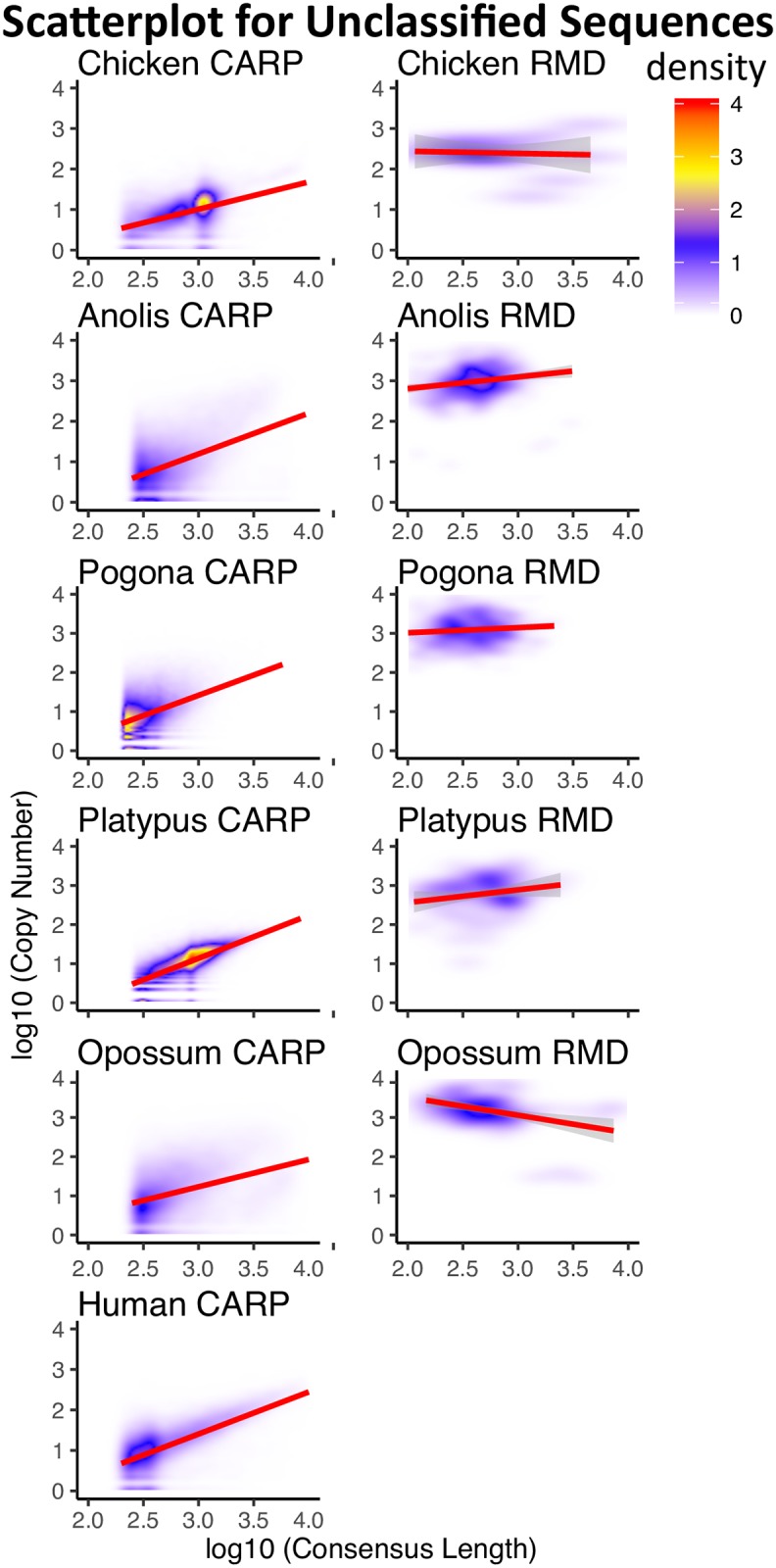
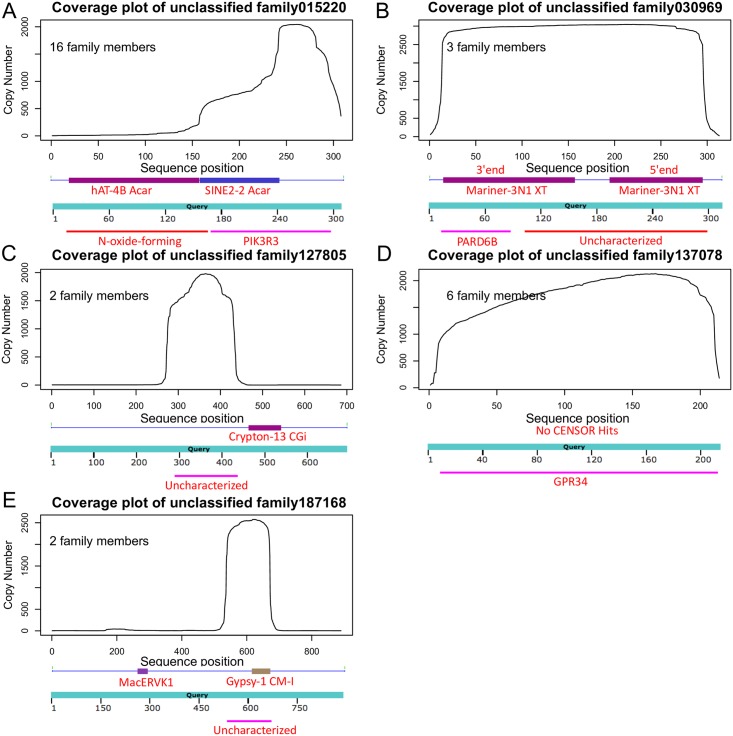
Transposable Elements (TEs) are mobile DNA sequences that make up significant fractions of amniote genomes. However, they are difficult to detect and annotate ab initio because of their variable features, lengths and clade-specific variants. We have addressed this problem by refining and developing a Comprehensive ab initio Repeat Pipeline (CARP) to identify and cluster TEs and other repetitive sequences in genome assemblies. The pipeline begins with a pairwise alignment using krishna, a custom aligner. Single linkage clustering is then carried out to produce families of repetitive elements. Consensus sequences are then filtered for protein coding genes and then annotated using Repbase and a custom library of retrovirus and reverse transcriptase sequences. This process yields three types of family: fully annotated, partially annotated and unannotated. Fully annotated families reflect recently diverged/young known TEs present in Repbase. The remaining two types of families contain a mixture of novel TEs and segmental duplications. These can be resolved by aligning these consensus sequences back to the genome to assess copy number vs. length distribution. Our pipeline has three significant advantages compared to other methods for ab initio repeat identification: 1) we generate not only consensus sequences, but keep the genomic intervals for the original aligned sequences, allowing straightforward analysis of evolutionary dynamics, 2) consensus sequences represent low-divergence, recently/currently active TE families, 3) segmental duplications are annotated as a useful by-product. We have compared our ab initio repeat annotations for 7 genome assemblies to other methods and demonstrate that CARP compares favourably with RepeatModeler, the most widely used repeat annotation package.
转座元件 (TEs) 是可移动的 DNA 序列,它们构成了羊膜动物基因组的重要部分。然而,由于它们的可变特征、长度和特定分支的变体,它们很难从头开始检测和注释。我们通过改进和开发一个全面的从头开始重复管道 (CARP) 来解决这个问题,以识别和聚类基因组组装中的 TEs 和其他重复序列。该管道首先使用自定义比对器 krishna 进行两两比对。然后进行单链接聚类,以产生重复元件家族。然后对保守序列进行筛选,去除蛋白质编码基因,然后使用 Repbase 和逆转录酶序列的自定义库进行注释。这个过程产生了三种类型的家族:完全注释、部分注释和未注释。完全注释的家族反映了 Repbase 中最近分化/年轻的已知 TEs。其余两种类型的家族包含新的 TEs 和片段重复。通过将这些共识序列回Align 到基因组,评估拷贝数与长度分布,可以解决这些问题。与其他从头开始重复识别方法相比,我们的管道有三个显著的优势:1)我们不仅生成共识序列,而且保留原始对齐序列的基因组间隔,允许对进化动态进行直接分析,2)共识序列代表低分化、最近/当前活跃的 TE 家族,3)片段重复被注释为有用的副产品。我们比较了 7 个基因组组装的从头开始重复注释与其他方法,并证明 CARP 与 RepeatModeler 相比具有优势,RepeatModeler 是最广泛使用的重复注释包。