de la Vega de León Antonio, Chen Beining, Gillet Valerie J
Information School, University of Sheffield, Regent Court, 211 Portobello, Sheffield, S1 4DP, UK.
Department of Chemistry, University of Sheffield, Dainton Building, Brook Hill, Sheffield, S3 7HF, UK.
J Cheminform. 2018 May 22;10(1):26. doi: 10.1186/s13321-018-0281-z.
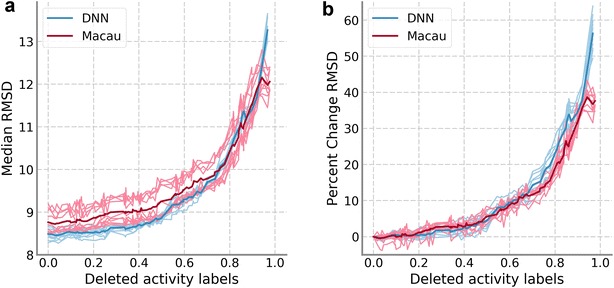
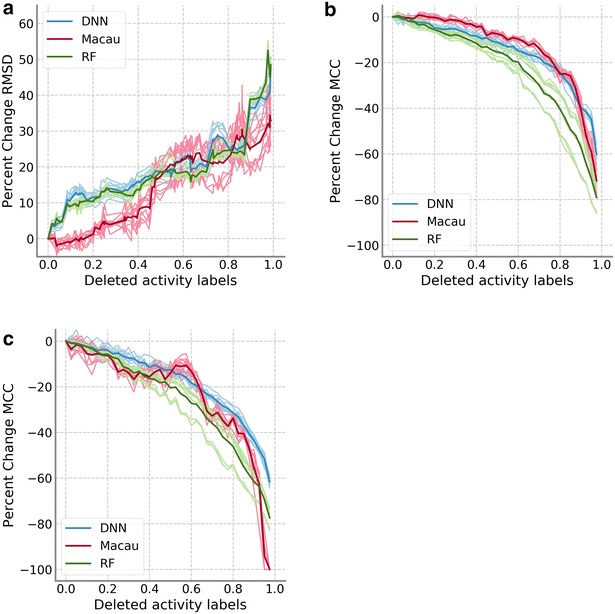
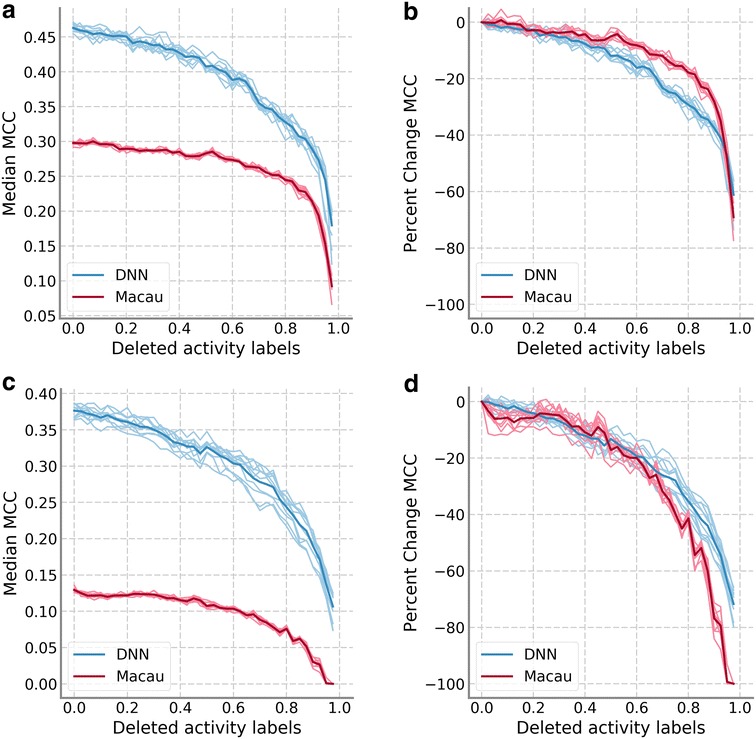
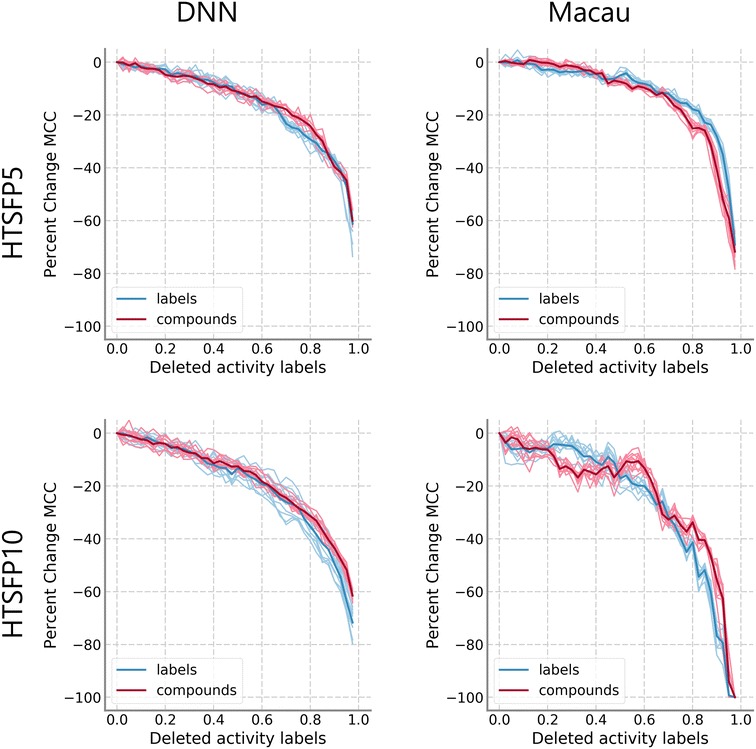
There has been a growing interest in multitask prediction in chemoinformatics, helped by the increasing use of deep neural networks in this field. This technique is applied to multitarget data sets, where compounds have been tested against different targets, with the aim of developing models to predict a profile of biological activities for a given compound. However, multitarget data sets tend to be sparse; i.e., not all compound-target combinations have experimental values. There has been little research on the effect of missing data on the performance of multitask methods. We have used two complete data sets to simulate sparseness by removing data from the training set. Different models to remove the data were compared. These sparse sets were used to train two different multitask methods, deep neural networks and Macau, which is a Bayesian probabilistic matrix factorization technique. Results from both methods were remarkably similar and showed that the performance decrease because of missing data is at first small before accelerating after large amounts of data are removed. This work provides a first approximation to assess how much data is required to produce good performance in multitask prediction exercises.
随着深度学习网络在化学信息学领域的应用日益广泛,多任务预测受到了越来越多的关注。该技术应用于多靶点数据集,其中化合物已针对不同靶点进行测试,目的是开发模型以预测给定化合物的生物活性概况。然而,多靶点数据集往往很稀疏,即并非所有化合物 - 靶点组合都有实验值。关于缺失数据对多任务方法性能的影响,目前研究较少。我们使用了两个完整的数据集,通过从训练集中删除数据来模拟稀疏性。比较了不同的删除数据模型。这些稀疏集用于训练两种不同的多任务方法,即深度神经网络和澳门算法(一种贝叶斯概率矩阵分解技术)。两种方法的结果非常相似,表明由于数据缺失导致的性能下降起初较小,在大量数据被删除后加速。这项工作提供了一个初步近似,以评估在多任务预测练习中需要多少数据才能产生良好的性能。