Rodríguez-Pérez Raquel, Bajorath Jürgen
Department of Life Science Informatics, B-IT, LIMES Program Unit Chemical Biology and Medicinal Chemistry, Rheinische Friedrich-Wilhelms-Universität, Endenicher Allee 19c, D-53115 Bonn, Germany.
Department of Medicinal Chemistry, Boehringer Ingelheim Pharma GmbH & Co. KG, Birkendorfer Str. 65, 88397 Biberach/Riß, Germany.
ACS Omega. 2018 Sep 30;3(9):12033-12040. doi: 10.1021/acsomega.8b01682. Epub 2018 Sep 27.
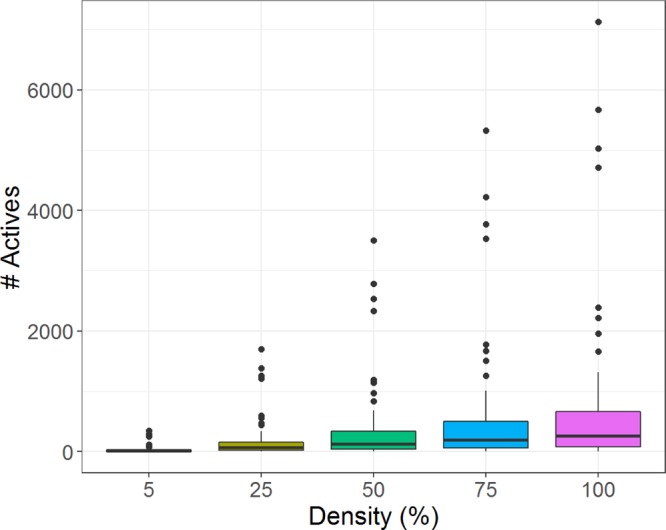
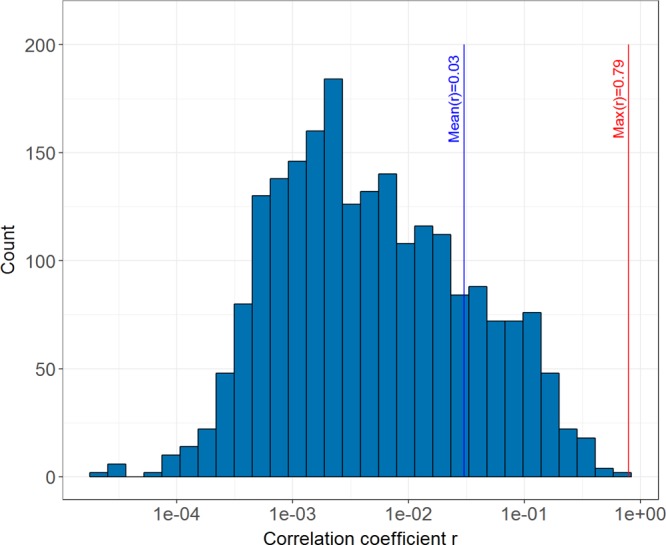
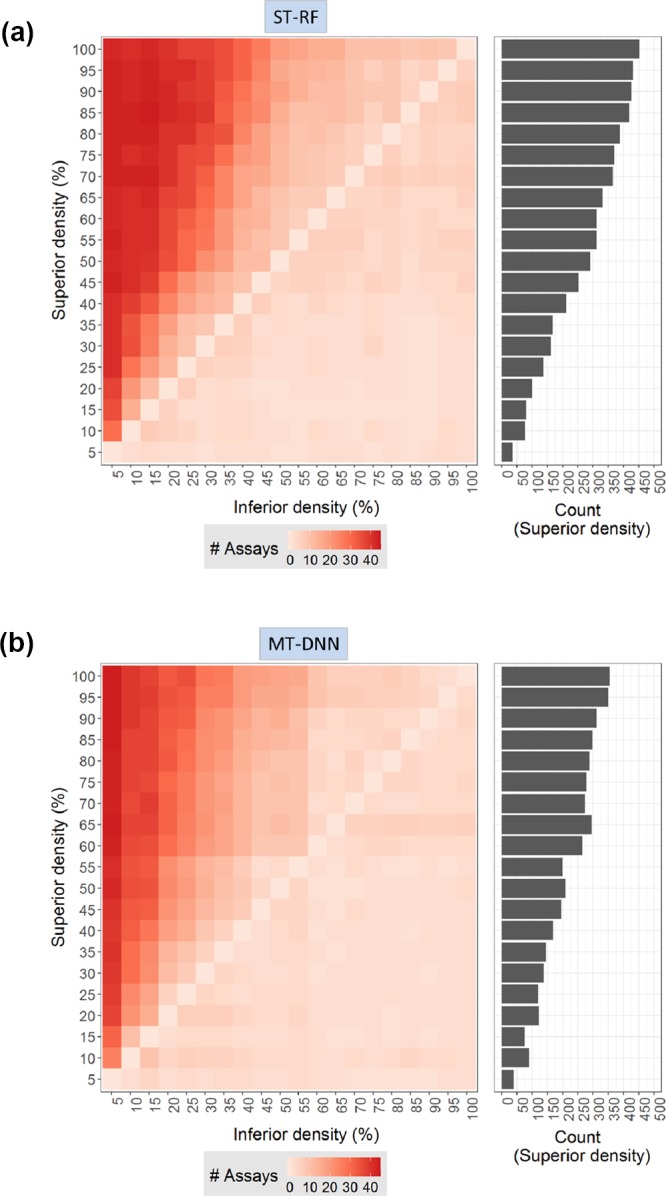
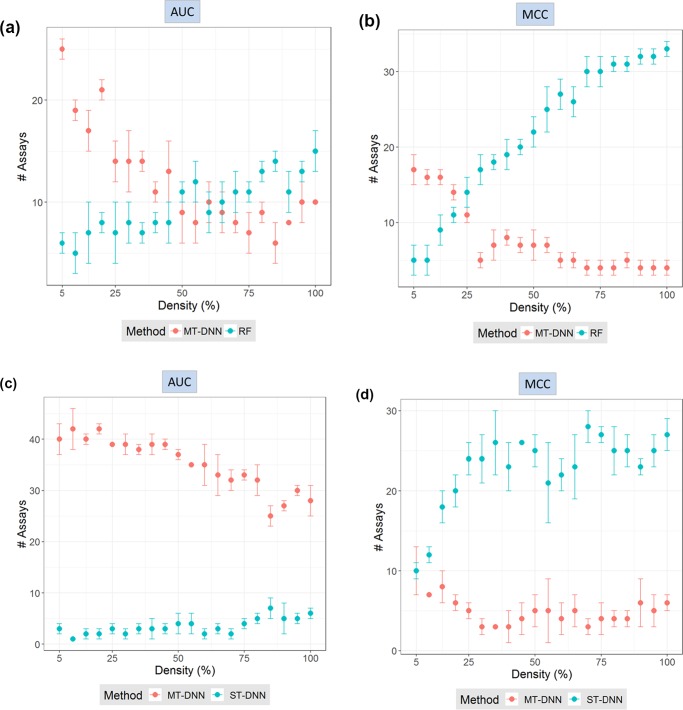
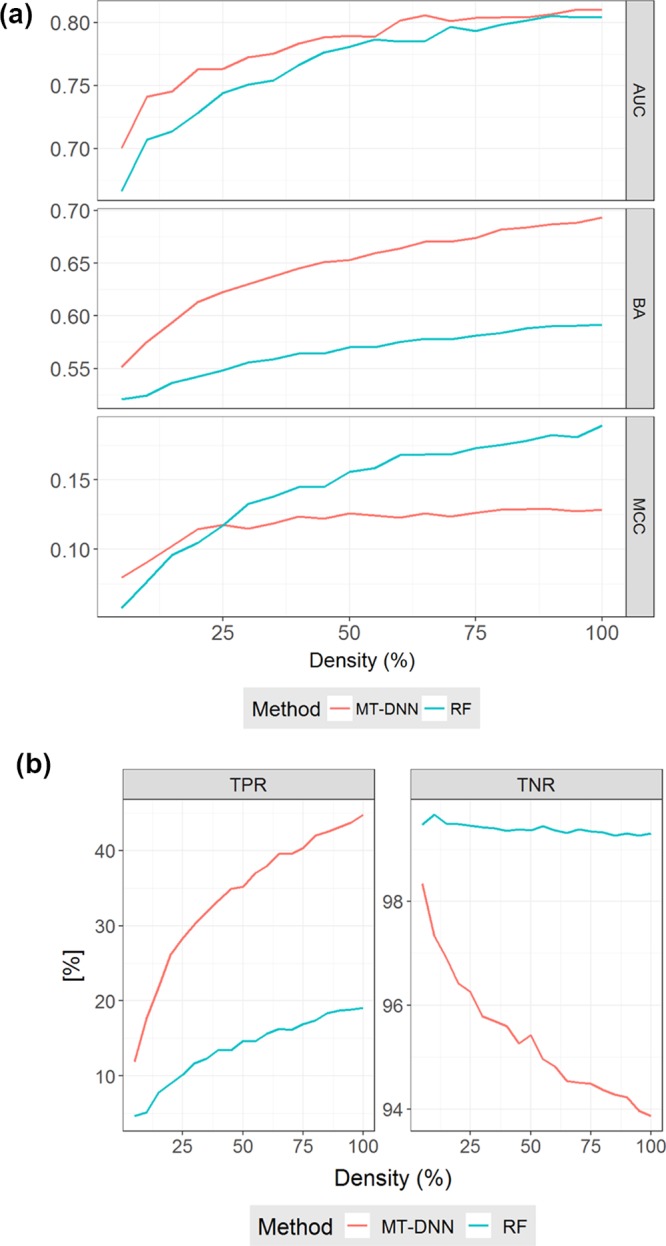
Currently, there is a high level of interest in deep learning and multitask learning in many scientific fields including the life sciences and chemistry. Herein, we investigate the performance of multitask deep neural networks (MT-DNNs) compared to random forest (RF) classification, a standard method in machine learning, in predicting compound profiling experiments. Predictions were carried out on a large profiling matrix extracted from biological screening data. For model building, submatrices with varying data density of 5-100% were generated to investigate the influence of data sparseness on prediction performance. MT-DNN models were directly compared to RF models, and control calculations were also carried out using single-task DNNs (ST-DNNs). On the basis of compound recall, the performance of ST-DNN was consistently lower than that of the other methods. Compared to RF, MT-DNN models only yielded better prediction performance for individual assays in the profiling matrix when training data were very sparse. However, when the matrix density increased to at least 25-45%, per-assay RF models met or partly exceeded the prediction performance of MT-DNN models. When the average performances of RF and MT-DNN over the grid of all targets were compared, MT-DNN was slightly superior to RF, which was a likely consequence of multitask learning. Overall, there was no consistent advantage of MT-DNN over standard RF classification in predicting the results of compound profiling assays under varying conditions. In the presence of very sparse training data, prediction performance was limited. Under these challenging conditions, MT-DNN was the preferred approach. When more training data became available and prediction performance increased, RF performance was not inferior to MT-DNN.
目前,深度学习和多任务学习在包括生命科学和化学在内的许多科学领域都备受关注。在此,我们研究了多任务深度神经网络(MT-DNN)与随机森林(RF)分类(机器学习中的一种标准方法)在预测化合物分析实验方面的性能。预测是在从生物筛选数据中提取的一个大型分析矩阵上进行的。为了构建模型,生成了数据密度在5%至100%之间变化的子矩阵,以研究数据稀疏性对预测性能的影响。将MT-DNN模型与RF模型直接进行比较,并且还使用单任务DNN(ST-DNN)进行了对照计算。基于化合物召回率,ST-DNN的性能始终低于其他方法。与RF相比,只有当训练数据非常稀疏时,MT-DNN模型在分析矩阵中的个别测定中才会产生更好的预测性能。然而,当矩阵密度增加到至少25%至45%时,每个测定的RF模型达到或部分超过了MT-DNN模型的预测性能。当比较RF和MT-DNN在所有目标网格上的平均性能时,MT-DNN略优于RF,这可能是多任务学习的结果。总体而言,在不同条件下预测化合物分析实验结果时,MT-DNN相对于标准RF分类并没有始终如一的优势。在训练数据非常稀疏的情况下,预测性能有限。在这些具有挑战性的条件下,MT-DNN是首选方法。当有更多训练数据可用且预测性能提高时,RF的性能并不逊色于MT-DNN。