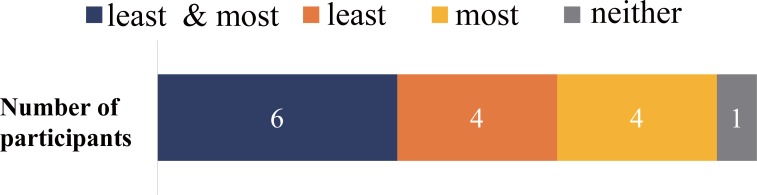Department of Life Sciences, The University of Tokyo, Tokyo, Japan.
PLoS One. 2018 Jun 26;13(6):e0199443. doi: 10.1371/journal.pone.0199443. eCollection 2018.
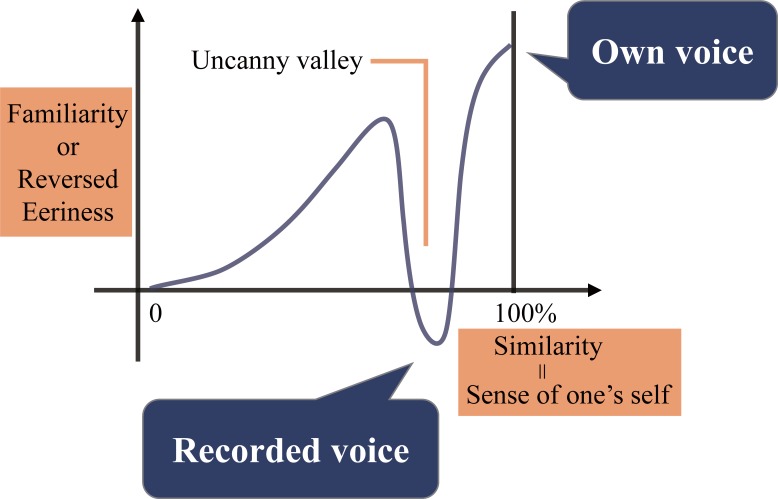
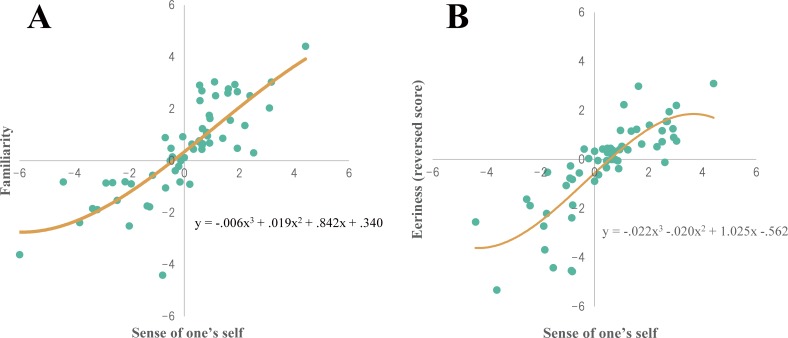
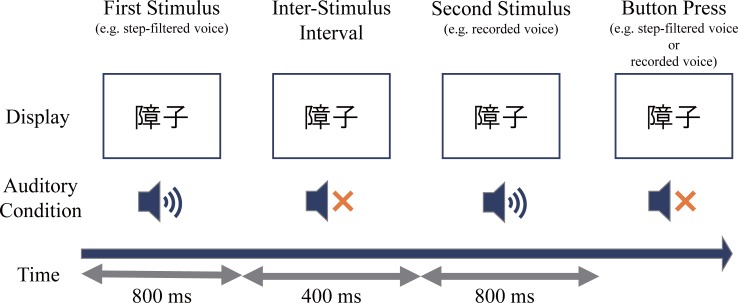
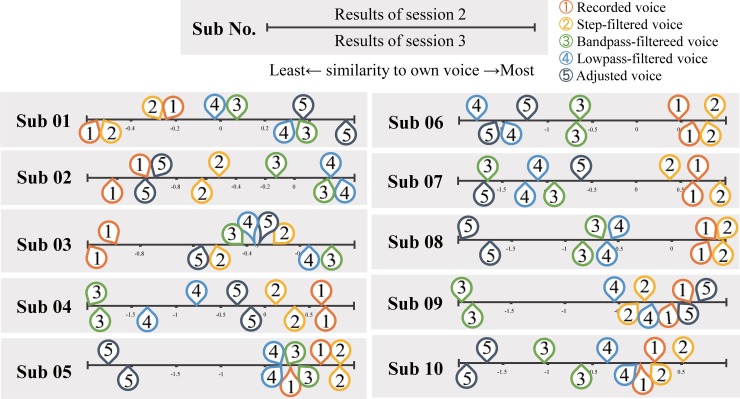
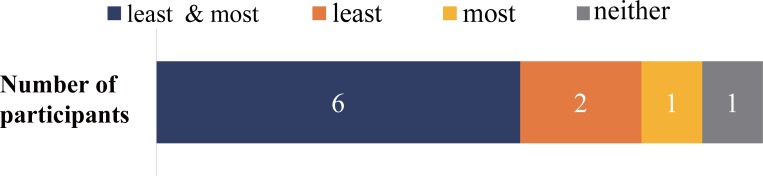
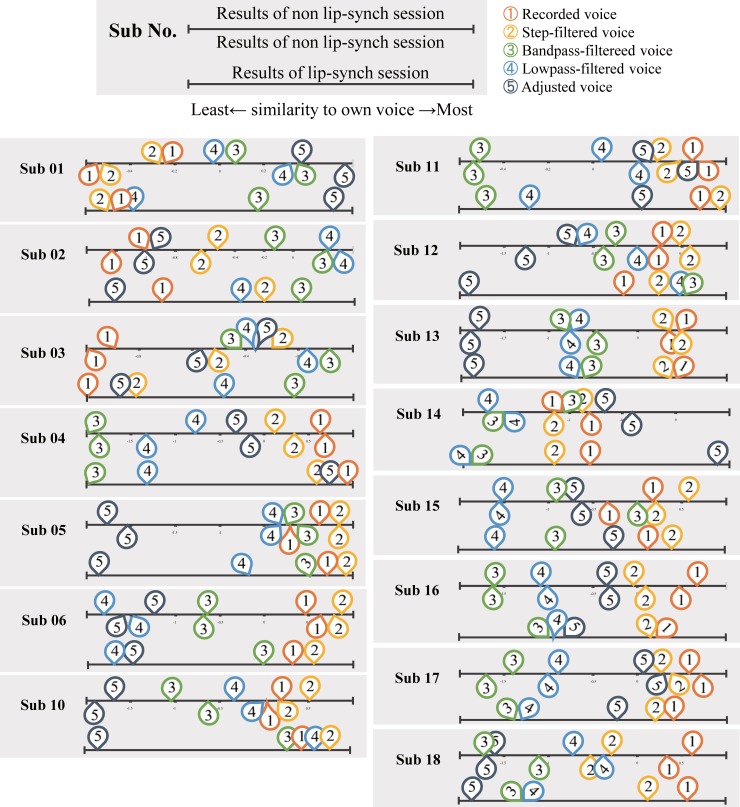
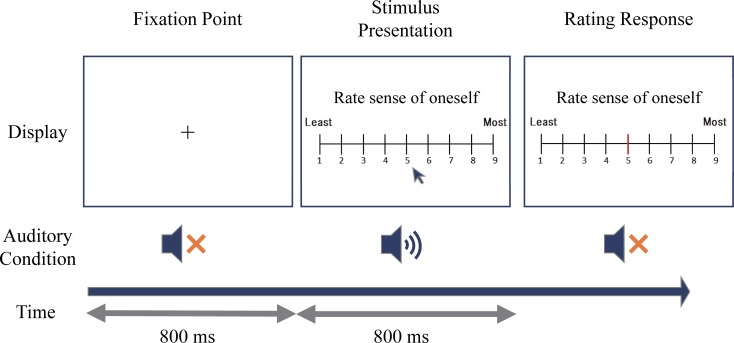
People perceive their recorded voice differently from their actively spoken voice. The uncanny valley theory proposes that as an object approaches humanlike characteristics, there is an increase in the sense of familiarity; however, eventually a point is reached where the object becomes strangely similar and makes us feel uneasy. The feeling of discomfort experienced when people hear their recorded voice may correspond to the floor of the proposed uncanny valley. To overcome the feeling of eeriness of own-voice recordings, previous studies have suggested equalization of the recorded voice with various types of filters, such as step, bandpass, and low-pass, yet the effectiveness of these filters has not been evaluated. To address this, the aim of experiment 1 was to identify what type of voice recording was the most representative of one's own voice. The voice recordings were presented in five different conditions: unadjusted recorded voice, step filtered voice, bandpass filtered voice, low-pass filtered voice, and a voice for which the participants freely adjusted the parameters. We found large individual differences in the most representative own-voice filter. In order to consider roles of sense of agency, experiment 2 investigated if lip-synching would influence the rating of own voice. The result suggested lip-synching did not affect own voice ratings. In experiment 3, based on the assumption that the voices used in previous experiments corresponded to continuous representations of non-own voice to own voice, the existence of an uncanny valley was examined. Familiarity, eeriness, and the sense of own voice were rated. The result did not support the existence of an uncanny valley. Taken together, the experiments led us to the following conclusions: there is no general filter that can represent own voice for everyone, sense of agency has no effect on own voice rating, and the uncanny valley does not exist for own voice, specifically.
人们对自己录制的声音和主动说出的声音有不同的感知。“恐怖谷理论”提出,随着一个物体越来越接近人类的特征,熟悉感会增加;然而,最终会达到一个点,这个物体变得非常相似,让我们感到不安。人们听到自己录制的声音时感到的不适可能与恐怖谷的谷底相对应。为了克服对自己录音的怪异感,之前的研究提出了用各种类型的滤波器(如阶跃、带通和低通滤波器)对录音进行均衡,然而这些滤波器的效果尚未得到评估。为了解决这个问题,实验 1 的目的是确定哪种录音最能代表自己的声音。录音以五种不同的条件呈现:未经调整的录音、阶跃滤波的录音、带通滤波的录音、低通滤波的录音以及参与者自由调整参数的录音。我们发现,最能代表自己声音的录音滤波器存在很大的个体差异。为了考虑主体感的作用,实验 2 调查了口型同步是否会影响对自己声音的评价。结果表明,口型同步不会影响对自己声音的评价。在实验 3 中,基于之前的实验中使用的声音对应于非自己声音到自己声音的连续表示的假设,检验了恐怖谷的存在。对熟悉度、怪异感和自我声音的感知进行了评价。结果不支持恐怖谷的存在。总的来说,这些实验得出了以下结论:对于每个人来说,没有一个通用的滤波器可以代表自己的声音,主体感对自己声音的评价没有影响,而且特定的恐怖谷并不存在于自己的声音中。