Bürckert Jean-Philippe, Faison William J, Mustin Danielle E, Dubois Axel R S X, Sinner Regina, Hunewald Oliver, Wienecke-Baldacchino Anke, Brieger Anne, Muller Claude P
Department of Infection and Immunity, Luxembourg Institute of Health, Esch-sur-Alzette, Luxembourg.
Oncotarget. 2018 Jul 13;9(54):30225-30239. doi: 10.18632/oncotarget.25493.
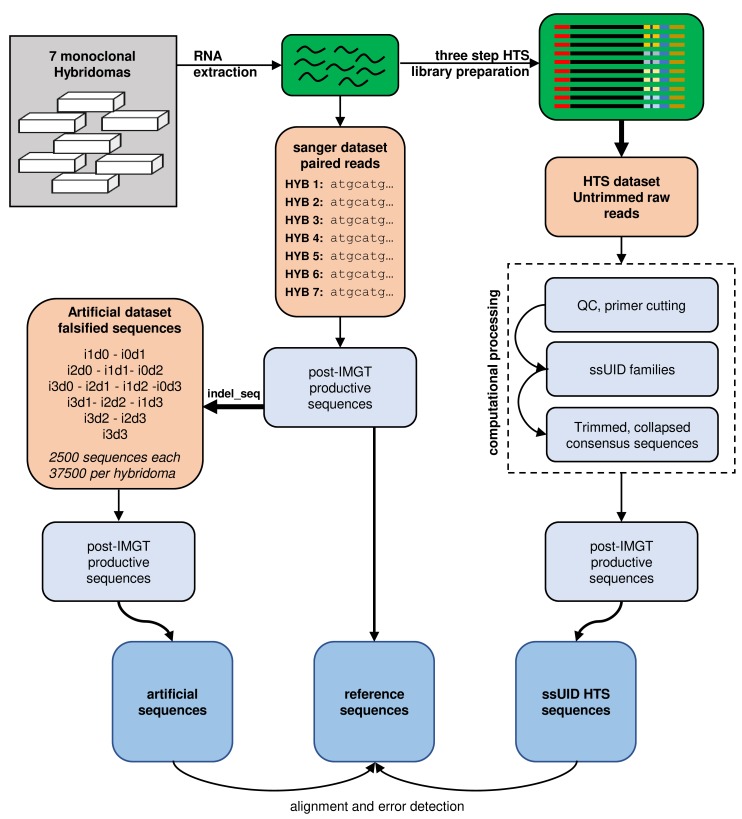
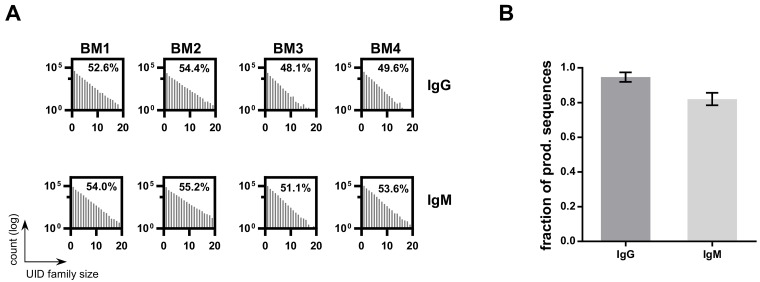
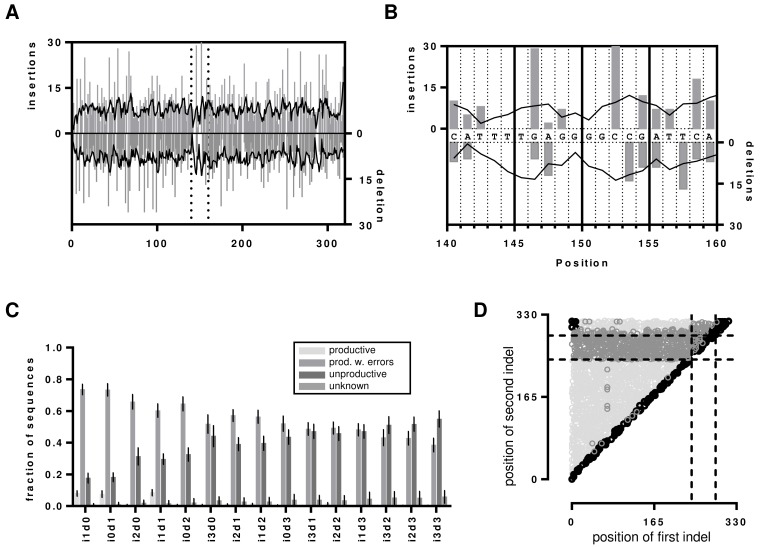
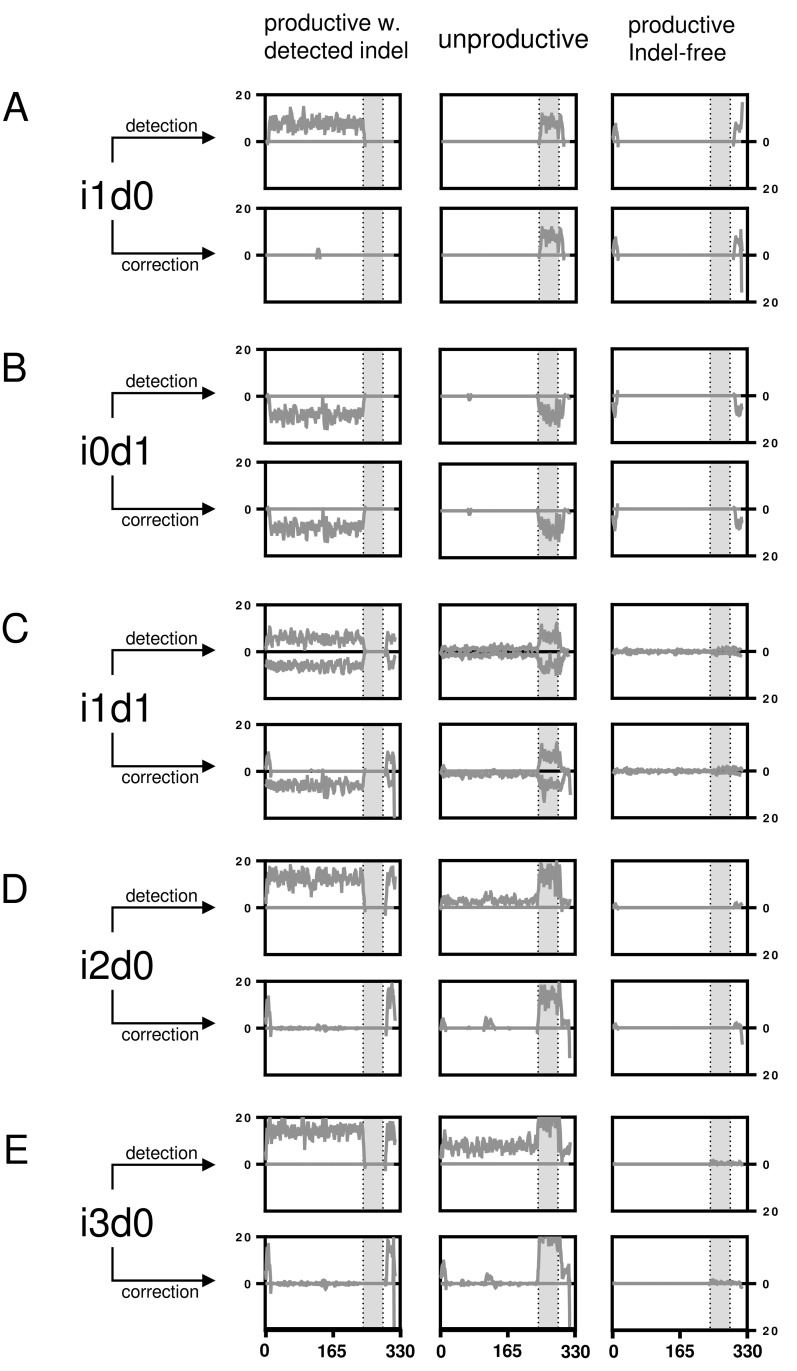
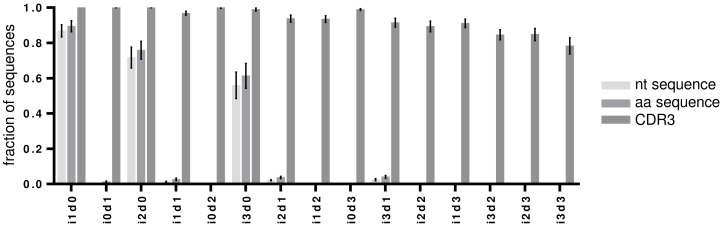
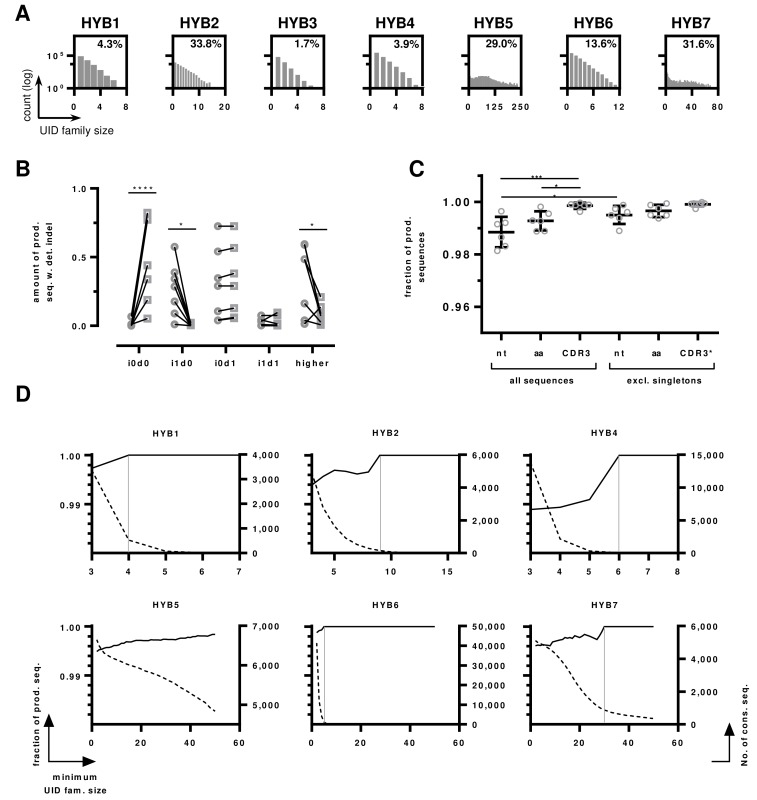
With the advent of high-throughput sequencing (HTS), profiling immunoglobulin (IG) repertoires has become an essential part of immunological research. Advances in sequencing technology enable the IonTorrent Personal Genome Machine (PGM) to cover the full-length of IG mRNA transcripts. Nucleotide insertions and deletions (indels) are the dominant errors of the PGM sequencing platform and can critically influence IG repertoire assessments. Here, we present a PGM-tailored IG repertoire sequencing approach combining error correction through unique molecular identifier (UID) barcoding and indel detection through ImMunoGeneTics (IMGT), the most commonly used sequence alignment database for IG sequences. Using artificially falsified sequences for benchmarking, we found that IMGT's underlying algorithms efficiently detect 98% of the introduced indels. Undetected indels are either located at the end of the sequences or produce masked frameshifts with an insertion and deletion in close proximity. The complementary determining regions 3 (CDR3s) are returned correct for up to 3 insertions or 3 deletions through conservative culling. We further show, that our PGM-tailored unique molecular identifiers result in highly accurate HTS data if combined with the presented processing strategy. In this regard, considering sequences with at least two copies from datasets with UID families of minimum 3 reads result in correct sequences with over 99% confidence. Finally, we show that the protocol can readily be used to generate homogenous datasets for bulk sequencing of murine bone marrow samples. Taken together, this approach will help to establish benchtop-scale sequencing of IG heavy chain transcripts in the field of IG repertoire research.
随着高通量测序(HTS)的出现,分析免疫球蛋白(IG)库已成为免疫学研究的重要组成部分。测序技术的进步使IonTorrent个人基因组测序仪(PGM)能够覆盖IG mRNA转录本的全长。核苷酸插入和缺失(indels)是PGM测序平台的主要错误,会严重影响IG库评估。在此,我们提出一种针对PGM的IG库测序方法,该方法结合了通过独特分子标识符(UID)条形码进行纠错以及通过免疫遗传学(IMGT)进行indel检测,IMGT是IG序列最常用的序列比对数据库。使用人工伪造的序列进行基准测试,我们发现IMGT的基础算法能有效检测出98%的引入indels。未检测到的indels要么位于序列末端,要么产生掩盖的移码突变,且插入和缺失紧邻。通过保守筛选,互补决定区3(CDR3s)对于多达3个插入或3个缺失能返回正确结果。我们进一步表明,如果与所提出的处理策略相结合,我们针对PGM的独特分子标识符会产生高度准确的HTS数据。在这方面,考虑来自UID家族且至少有两个拷贝、最小读长为3的数据集序列,能以超过99%的置信度得到正确序列。最后,我们表明该方案可轻松用于生成用于小鼠骨髓样本批量测序的同质数据集。综上所述,这种方法将有助于在IG库研究领域建立IG重链转录本的台式规模测序。