Department of Earth Sciences, University of Toronto, Toronto, Canada.
PLoS One. 2018 Aug 23;13(8):e0202214. doi: 10.1371/journal.pone.0202214. eCollection 2018.
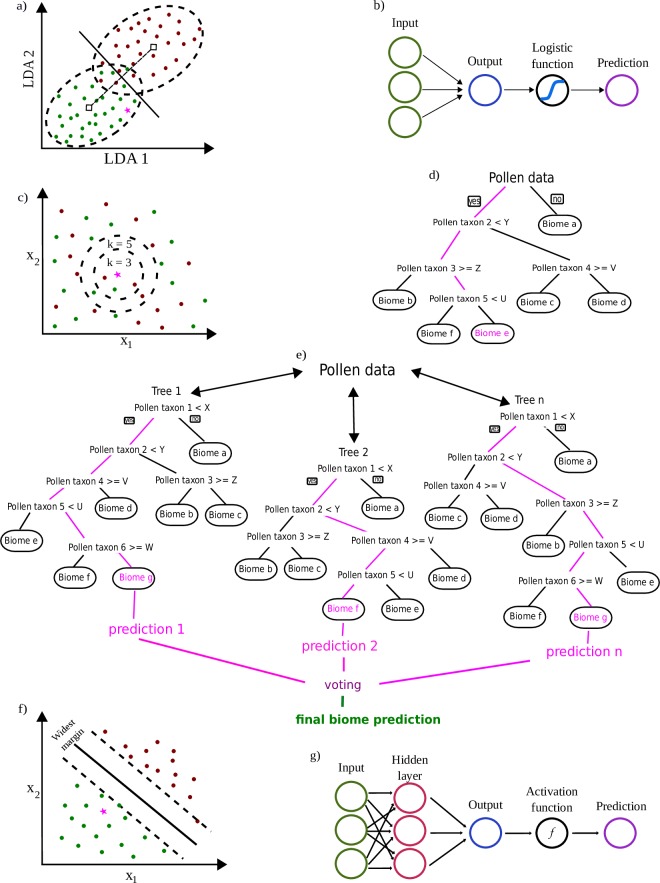
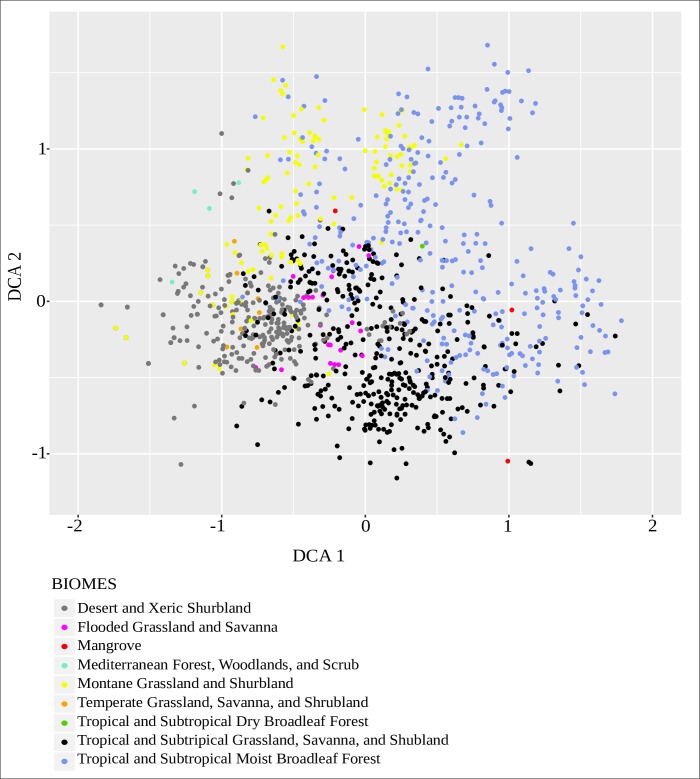
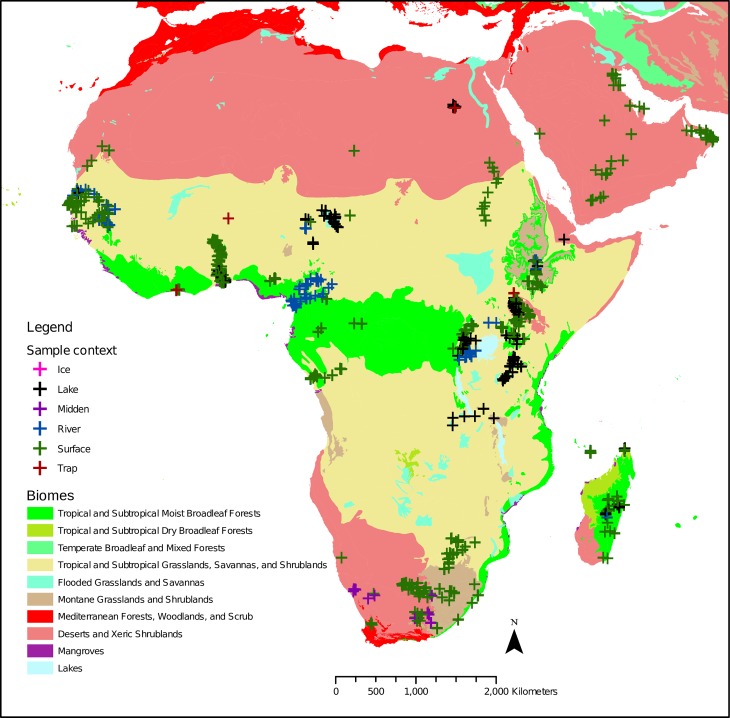
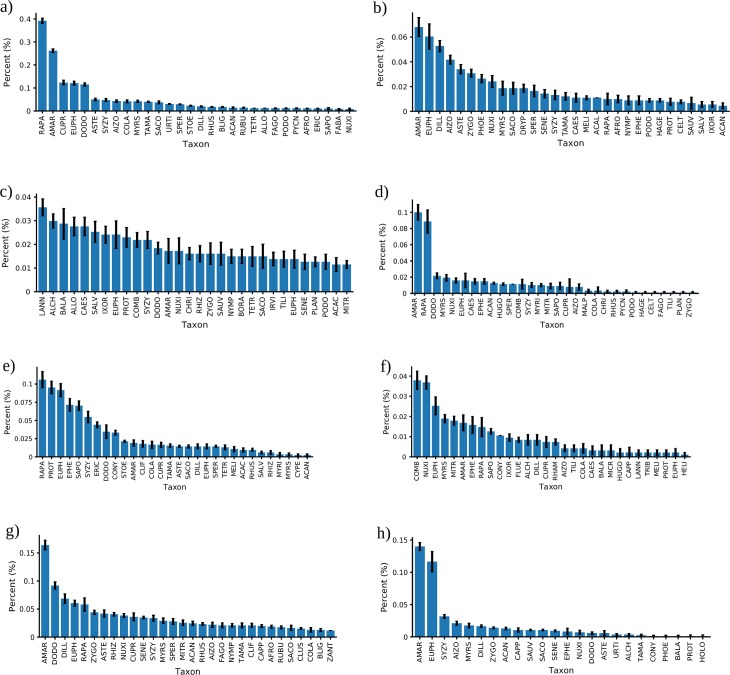
This paper investigates suitability of supervised machine learning classification methods for classification of biomes using pollen datasets. We assign modern pollen samples from Africa and Arabia to five biome classes using a previously published African pollen dataset and a global ecosystem classification scheme. To test the applicability of traditional and machine-learning based classification models for the task of biome prediction from high dimensional modern pollen data, we train a total of eight classification models, including Linear Discriminant Analysis, Logistic Regression, Naïve Bayes, K-Nearest Neighbors, Classification Decision Tree, Random Forest, Neural Network, and Support Vector Machine. The ability of each model to predict biomes from pollen data is statistically tested on an independent test set. The Random Forest classifier outperforms other models in its ability correctly classify biomes given pollen data. Out of the eight models, the Random Forest classifier scores highest on all of the metrics used for model evaluations and is able to predict four out of five biome classes to high degree of accuracy, including arid, montane, tropical and subtropical closed and open systems, e.g. forests and savanna/grassland. The model has the potential for accurate reconstructions of past biomes and awaits application to fossil pollen sequences. The Random Forest model may be used to investigate vegetation changes on both long and short time scales, e.g. during glacial and interglacial cycles, or more recent and abrupt climatic anomalies like the African Humid Period. Such applications may contribute to a better understanding of past shifts in vegetation cover and ultimately provide valuable information on drivers of climate change.
本文研究了监督机器学习分类方法在使用花粉数据集进行生物群落分类中的适用性。我们使用先前发表的非洲花粉数据集和全球生态系统分类方案,将来自非洲和阿拉伯的现代花粉样本分配到五个生物群落类别中。为了测试传统和基于机器学习的分类模型在从高维现代花粉数据预测生物群落任务中的适用性,我们总共训练了 8 个分类模型,包括线性判别分析、逻辑回归、朴素贝叶斯、K-最近邻、分类决策树、随机森林、神经网络和支持向量机。我们在独立测试集上对每个模型从花粉数据预测生物群落的能力进行了统计测试。随机森林分类器在根据花粉数据正确分类生物群落的能力方面优于其他模型。在这 8 个模型中,随机森林分类器在用于模型评估的所有指标上得分最高,并且能够高度准确地预测五个生物群落类别中的四个,包括干旱、山地、热带和亚热带封闭和开放系统,例如森林和热带稀树草原/草原。该模型具有准确重建过去生物群落的潜力,有待于应用于化石花粉序列。随机森林模型可用于研究长时间和短时间尺度上的植被变化,例如在冰期和间冰期循环期间,或更近期和突然的气候异常,如非洲湿润期。这些应用可能有助于更好地了解过去植被覆盖的变化,并最终提供有关气候变化驱动因素的有价值信息。