School of Computer Science, University of Manchester, Manchester, M13 9PL, UK.
School of Biological Sciences, University of Manchester, Manchester, M13 9PT, UK.
BMC Bioinformatics. 2018 Oct 19;19(1):386. doi: 10.1186/s12859-018-2355-3.
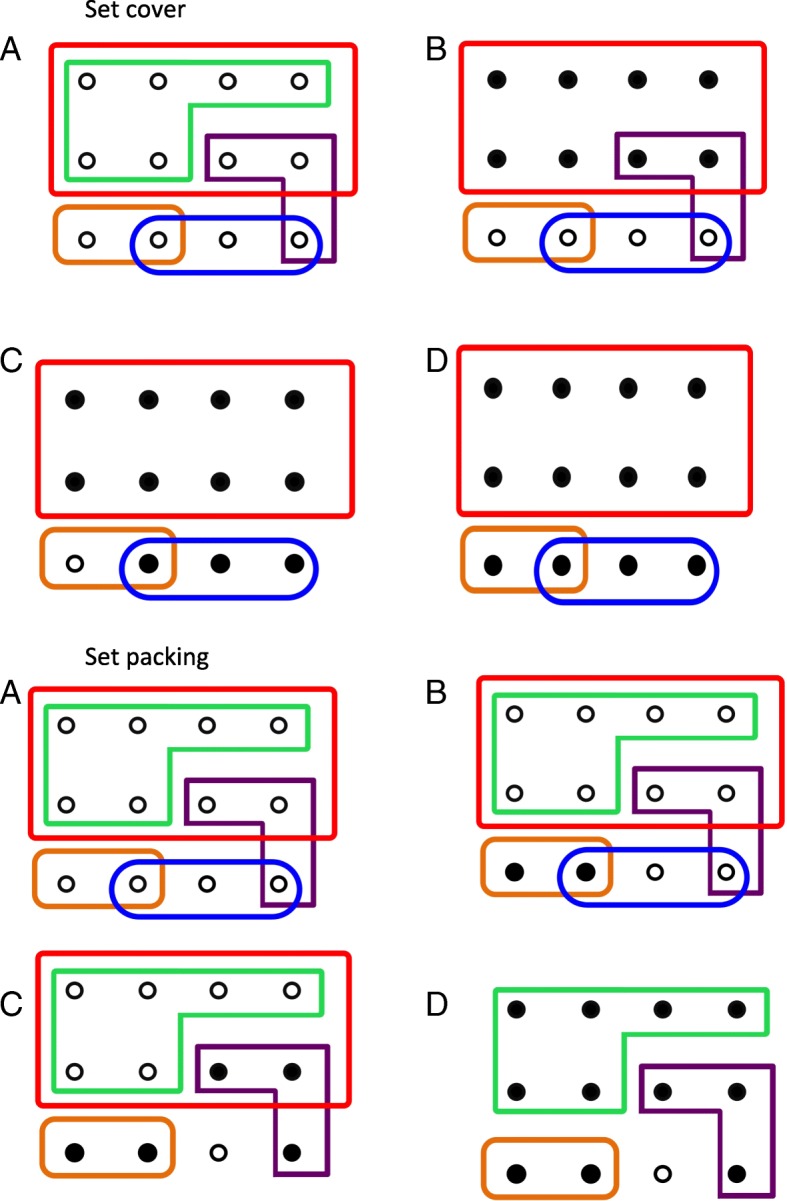
The consolidation of pathway databases, such as KEGG, Reactome and ConsensusPathDB, has generated widespread biological interest, however the issue of pathway redundancy impedes the use of these consolidated datasets. Attempts to reduce this redundancy have focused on visualizing pathway overlap or merging pathways, but the resulting pathways may be of heterogeneous sizes and cover multiple biological functions. Efforts have also been made to deal with redundancy in pathway data by consolidating enriched pathways into a number of clusters or concepts. We present an alternative approach, which generates pathway subsets capable of covering all of genes presented within either pathway databases or enrichment results, generating substantial reductions in redundancy.
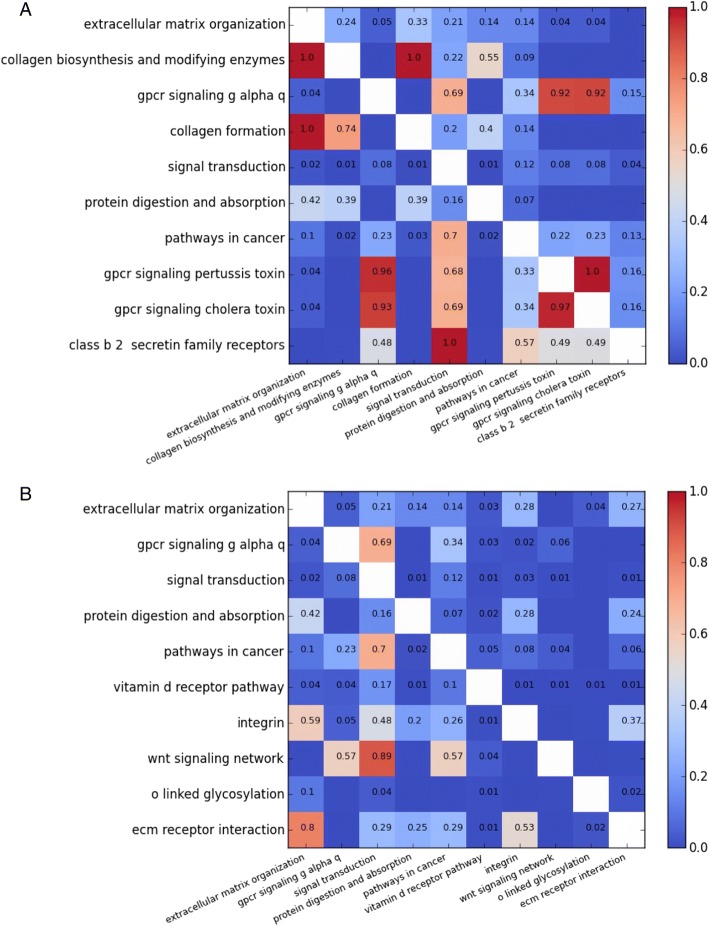
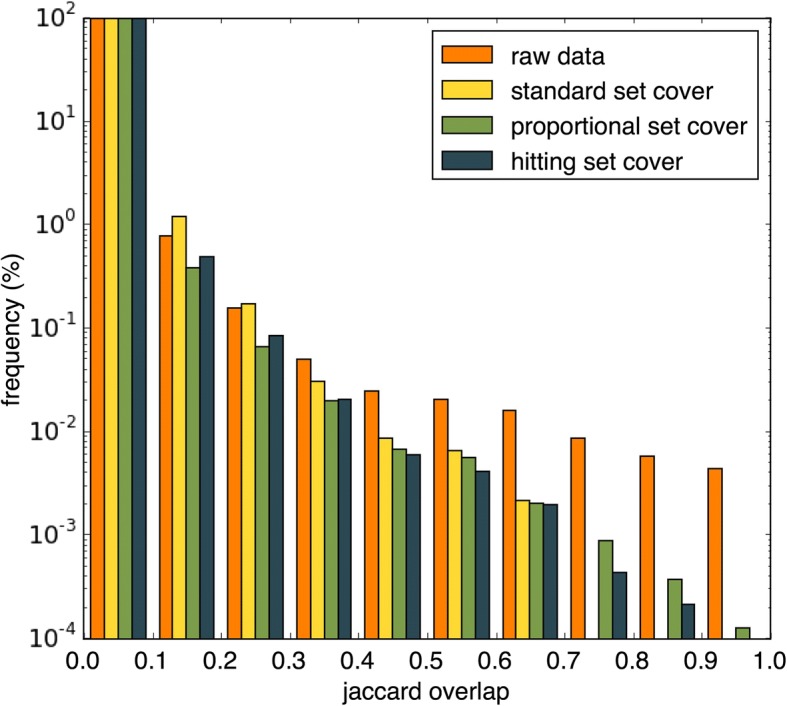
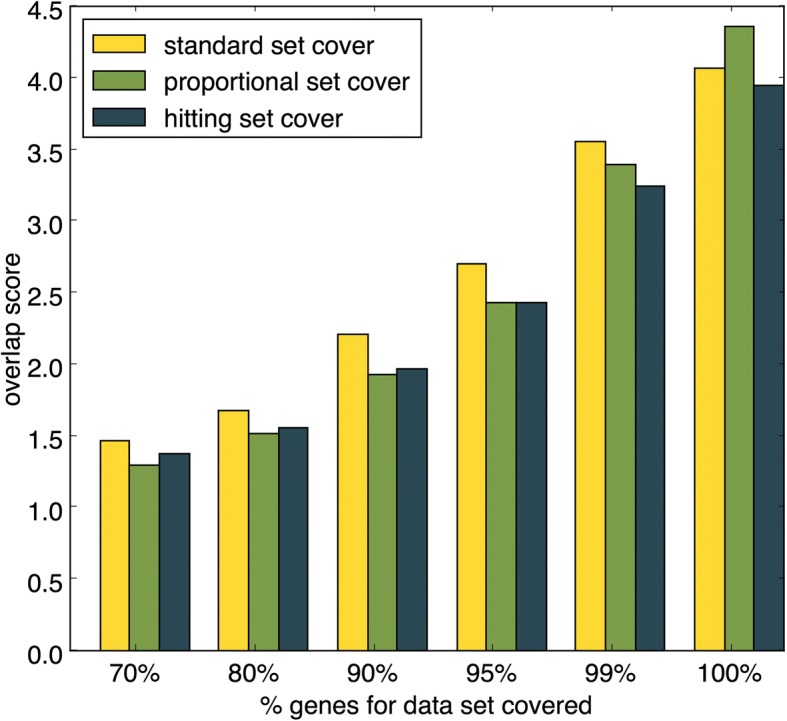
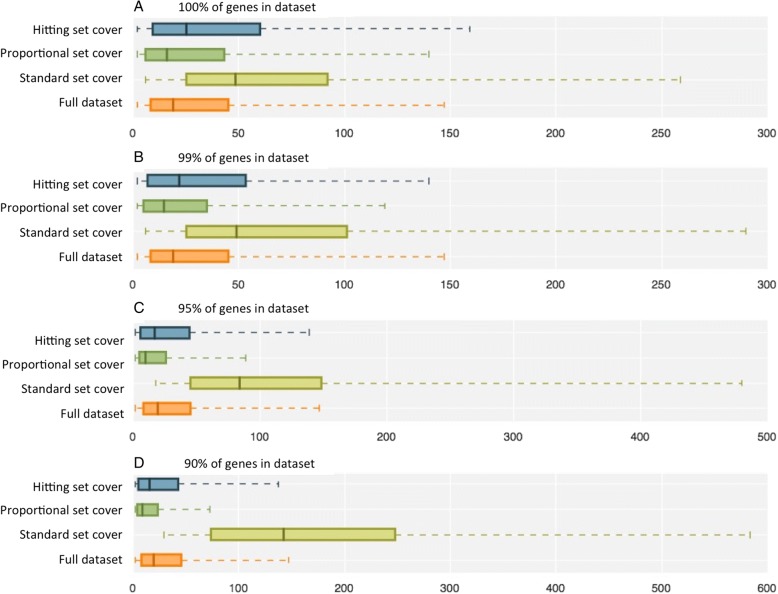
We propose a method that uses set cover to reduce pathway redundancy, without merging pathways. The proposed approach considers three objectives: removal of pathway redundancy, controlling pathway size and coverage of the gene set. By applying set cover to the ConsensusPathDB dataset we were able to produce a reduced set of pathways, representing 100% of the genes in the original data set with 74% less redundancy, or 95% of the genes with 88% less redundancy. We also developed an algorithm to simplify enrichment data and applied it to a set of enriched osteoarthritis pathways, revealing that within the top ten pathways, five were redundant subsets of more enriched pathways. Applying set cover to the enrichment results removed these redundant pathways allowing more informative pathways to take their place.
Our method provides an alternative approach for handling pathway redundancy, while ensuring that the pathways are of homogeneous size and gene coverage is maximised. Pathways are not altered from their original form, allowing biological knowledge regarding the data set to be directly applicable. We demonstrate the ability of the algorithms to prioritise redundancy reduction, pathway size control or gene set coverage. The application of set cover to pathway enrichment results produces an optimised summary of the pathways that best represent the differentially regulated gene set.
KEGG、Reactome 和 ConsensusPathDB 等途径数据库的整合引起了广泛的生物学兴趣,然而途径冗余问题阻碍了这些整合数据集的使用。减少这种冗余的尝试集中在可视化途径重叠或合并途径上,但是得到的途径可能大小不同,涵盖多种生物学功能。还努力通过将富集途径整合到若干个簇或概念中,来处理途径数据中的冗余。我们提出了一种替代方法,该方法生成能够覆盖途径数据库或富集结果中呈现的所有基因的途径子集,从而大大减少冗余。
我们提出了一种使用集合覆盖来减少途径冗余的方法,而无需合并途径。所提出的方法考虑了三个目标:去除途径冗余,控制途径大小和基因集的覆盖。通过将集合覆盖应用于 ConsensusPathDB 数据集,我们能够生成一个减少的途径集,代表原始数据集的 100%的基因,具有 74%的冗余减少,或者 95%的基因具有 88%的冗余减少。我们还开发了一种简化富集数据的算法,并将其应用于一组富集的骨关节炎途径,结果表明在前十条途径中,有五条是更富集途径的冗余子集。将集合覆盖应用于富集结果可以消除这些冗余途径,从而让更具信息量的途径取代它们。
我们的方法为处理途径冗余提供了一种替代方法,同时确保途径具有均匀的大小和最大的基因覆盖。途径不会从其原始形式改变,允许直接应用有关数据集的生物学知识。我们展示了算法优先考虑减少冗余、控制途径大小或基因集覆盖的能力。将集合覆盖应用于途径富集结果会产生最佳代表差异调节基因集的途径的优化摘要。