European Bioinformatics Institute (EMBL-EBI), Wellcome Genome Campus, Hinxton, Cambridge CB10 1SD, United Kingdom.
Sci Data. 2018 Oct 23;5:180230. doi: 10.1038/sdata.2018.230.
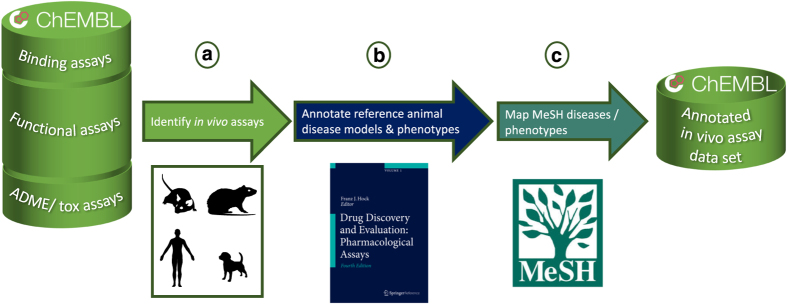
ChEMBL is a large-scale, open-access drug discovery resource containing bioactivity information primarily extracted from scientific literature. A substantial dataset of more than 135,000 in vivo assays has been collated as a key resource of animal models for translational medicine within drug discovery. To improve the utility of the in vivo data, an extensive data curation task has been undertaken that allows the assays to be grouped by animal disease model or phenotypic endpoint. The dataset contains previously unavailable information about compounds or drugs tested in animal models and, in conjunction with assay data on protein targets or cell- or tissue- based systems, allows the investigation of the effects of compounds at differing levels of biological complexity. Equally, it enables researchers to identify compounds that have been investigated for a group of disease-, pharmacology- or toxicity-relevant assays.
ChEMBL 是一个大型的、开放获取的药物发现资源,主要包含从科学文献中提取的生物活性信息。一个包含超过 135000 个体内检测的大型数据集已经被整理为药物发现中转化医学的动物模型的关键资源。为了提高体内数据的实用性,已经进行了广泛的数据整理工作,允许根据动物疾病模型或表型终点对检测进行分组。该数据集包含了以前在动物模型中测试的化合物或药物的未公开信息,并且与针对蛋白质靶标或基于细胞或组织的系统的检测数据相结合,允许在不同水平的生物复杂性下研究化合物的作用。同样,它使研究人员能够识别出针对一组与疾病、药理学或毒性相关的检测进行研究的化合物。