School of Software, Hallym University, Chuncheon, South Korea.
Bio-IT Research Center, Hallym University, Chuncheon, South Korea.
Biomed Eng Online. 2018 Nov 6;17(Suppl 2):158. doi: 10.1186/s12938-018-0573-6.
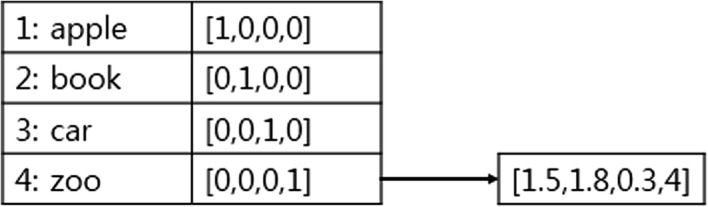
Biomedical named entity recognition (Bio-NER) is a fundamental task in handling biomedical text terms, such as RNA, protein, cell type, cell line, and DNA. Bio-NER is one of the most elementary and core tasks in biomedical knowledge discovery from texts. The system described here is developed by using the BioNLP/NLPBA 2004 shared task. Experiments are conducted on a training and evaluation set provided by the task organizers.
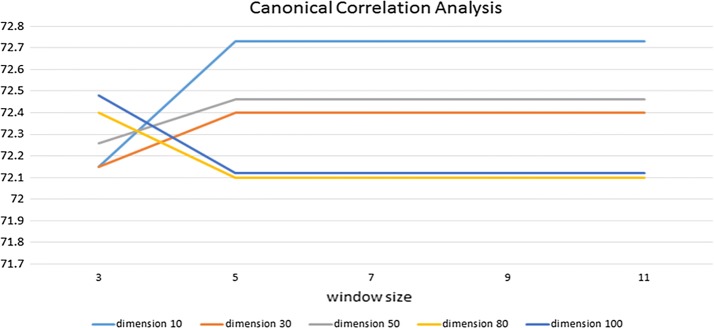
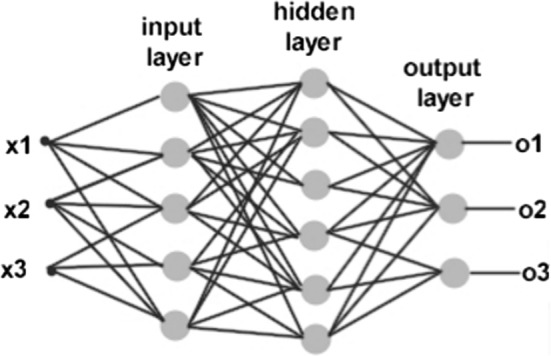
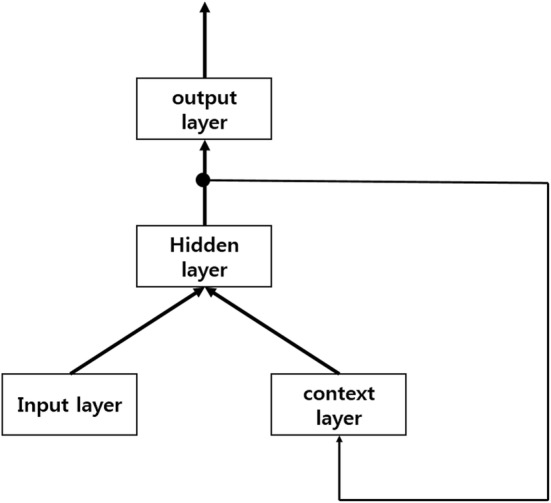
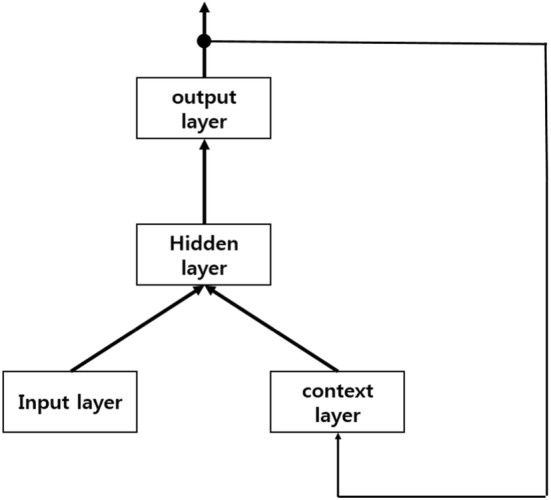
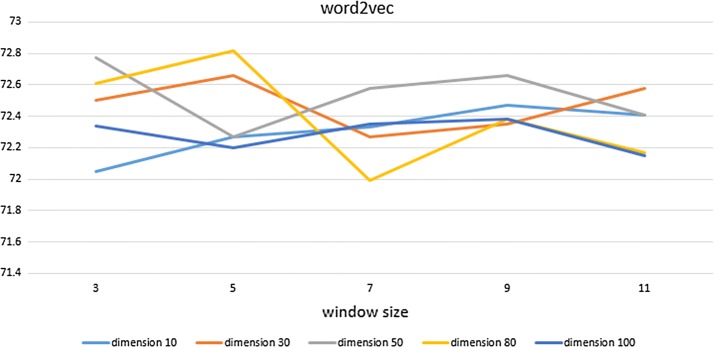
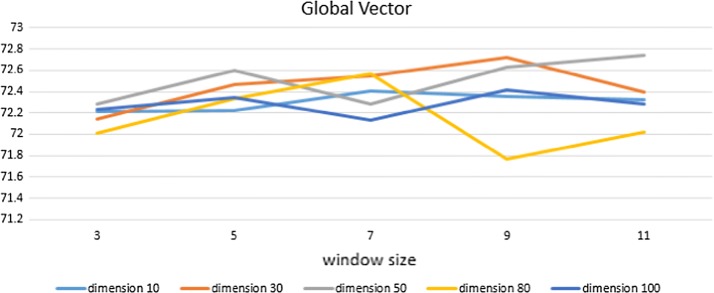
Our results show that, compared with a baseline having a 70.09% F1 score, the RNN Jordan- and Elman-type algorithms have F1 scores of approximately 60.53% and 58.80%, respectively. When we use CRF as a machine learning algorithm, CCA, GloVe, and Word2Vec have F1 scores of 72.73%, 72.74%, and 72.82%, respectively.
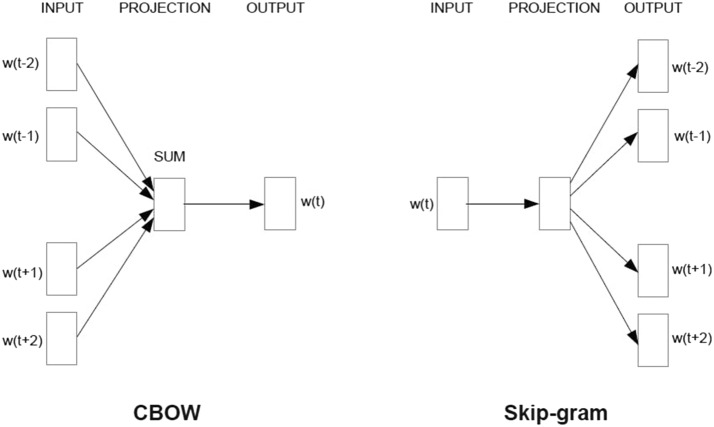
By using the word embedding constructed through the unsupervised learning, the time and cost required to construct the learning data can be saved.
生物医学命名实体识别(Bio-NER)是处理生物医学文本术语的基本任务,例如 RNA、蛋白质、细胞类型、细胞系和 DNA。Bio-NER 是从文本中发现生物医学知识的最基本和核心任务之一。这里描述的系统是使用 BioNLP/NLPBA 2004 共享任务开发的。实验是在任务组织者提供的培训和评估集上进行的。
我们的结果表明,与基线的 F1 分数为 70.09%相比,RNN Jordan 和 Elman 类型算法的 F1 分数分别约为 60.53%和 58.80%。当我们使用 CRF 作为机器学习算法时,CCA、GloVe 和 Word2Vec 的 F1 分数分别为 72.73%、72.74%和 72.82%。
通过使用无监督学习构建的单词嵌入,可以节省构建学习数据所需的时间和成本。