Zhao Melissa, Tang Yushi, Kim Hyunkyung, Hasegawa Kohei
Department of Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA, USA.
Department of Emergency Medicine, Massachusetts General Hospital, Harvard Medical School, Boston, MA, USA.
Cancer Inform. 2018 Nov 9;17:1176935118810215. doi: 10.1177/1176935118810215. eCollection 2018.
Despite existing prognostic markers, breast cancer prognosis remains a difficult subject due to the complex relationships between many contributing factors and survival. This study seeks to integrate multiple clinicopathological and genomic factors with dimensional reduction across machine learning algorithms to compare survival predictions.
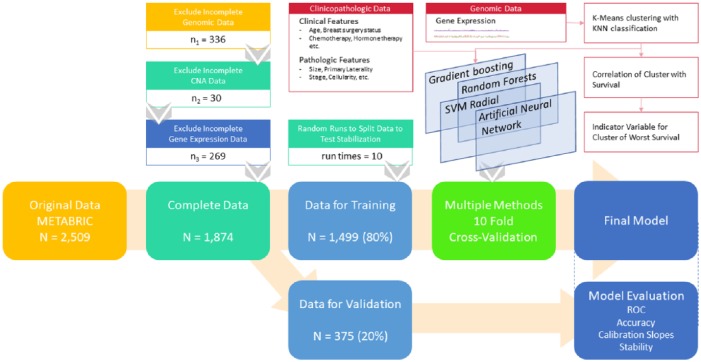
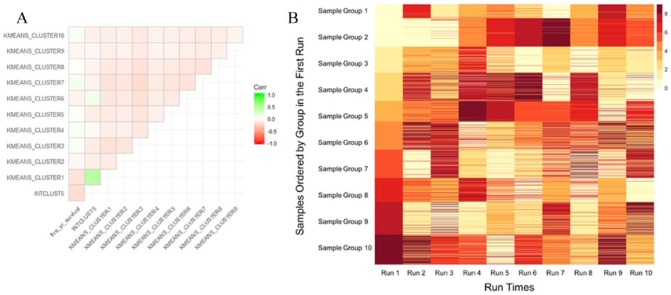
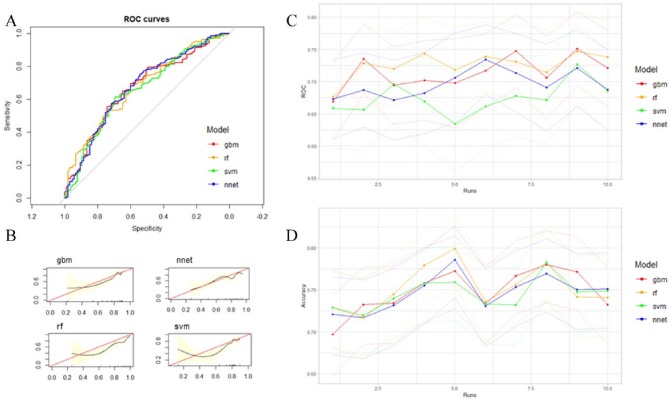
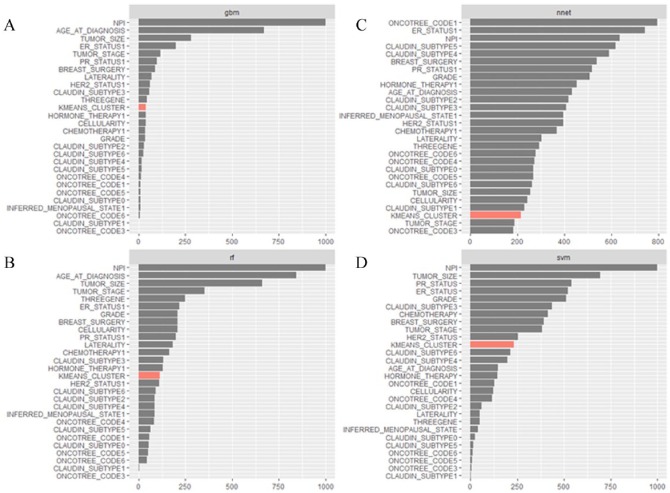
This is a secondary analysis of the data from a prospective cohort study of female patients with breast cancer enrolled in the Molecular Taxonomy of Breast Cancer International Consortium (METABRIC). We constructed a series of predictive models: ensemble models (Gradient Boosting and Random Forest), support vector machine (SVM), and artificial neural networks (ANN) for 5-year survival based on clinicopathological and gene expression data after K-means clustering with K-nearest-neighbor (KNN) classification. Model performance was evaluated by receiver operating characteristic (ROC) curve, accuracy, and calibration slope (CS). Model stability was assessed over 10 random runs in terms of ROC, accuracy, CS, and variable importance.
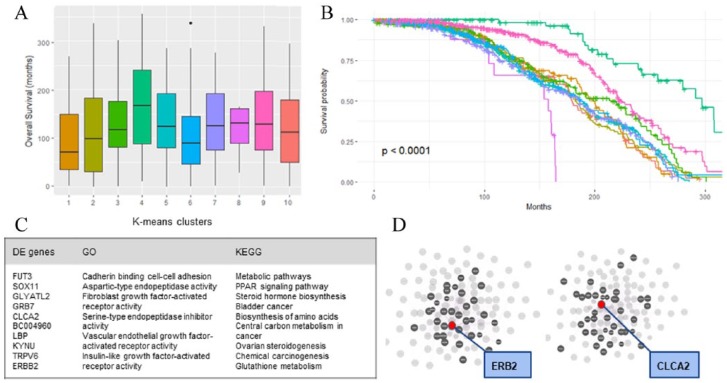
The analytic cohort is composed of 1874 patients with breast cancer. Overall, the median age was 62 years; the 5-year survival rate was 75%. ROC and accuracy were not significantly different between models (ROC and accuracy around 0.67 and 0.72 across models, respectively). However, ensemble methods resulted in better fit (CS) with stable measures of variable importance across 10 random training/validation splits. K-means clustering of gene expression profiles on training data points along with KNN classification of validation data points was a robust method of dimensional reduction. Furthermore, the gene expression cluster with the highest mortality risk was an influential factor in model prediction.
Using machine learning methods to construct predictive models for 5-year survival in patients with breast cancer, we demonstrated discrimination ability across models with new insight into the stability and utility of dimensional reduction on genomic features in breast cancer survival prediction.
尽管存在现有的预后标志物,但由于许多促成因素与生存率之间的复杂关系,乳腺癌的预后仍然是一个难题。本研究旨在将多个临床病理和基因组因素与跨机器学习算法的降维方法相结合,以比较生存预测结果。
这是对参加国际乳腺癌分子分类联盟(METABRIC)的女性乳腺癌患者前瞻性队列研究数据的二次分析。我们构建了一系列预测模型:基于临床病理和基因表达数据,在使用K近邻(KNN)分类进行K均值聚类后,建立用于预测5年生存率的集成模型(梯度提升和随机森林)、支持向量机(SVM)和人工神经网络(ANN)。通过受试者工作特征(ROC)曲线、准确性和校准斜率(CS)评估模型性能。在10次随机运行中,根据ROC、准确性、CS和变量重要性评估模型稳定性。
分析队列由1874例乳腺癌患者组成。总体而言,中位年龄为62岁;5年生存率为75%。各模型之间的ROC和准确性无显著差异(各模型的ROC和准确性分别约为0.67和0.72)。然而,集成方法在10次随机训练/验证分割中具有更好的拟合度(CS)以及稳定的变量重要性度量。对训练数据点的基因表达谱进行K均值聚类以及对验证数据点进行KNN分类是一种稳健的降维方法。此外,具有最高死亡风险的基因表达簇是模型预测中的一个影响因素。
使用机器学习方法构建乳腺癌患者5年生存预测模型,我们展示了各模型的判别能力,并对乳腺癌生存预测中基因组特征降维的稳定性和实用性有了新的认识。