From the Department of Epidemiology and Biostatistics, Milken Institute School of Public Health, George Washington University, Washington, DC.
Institute of Social Science Survey, Peking University, Beijing.
Epidemiology. 2019 Mar;30(2):291-302. doi: 10.1097/EDE.0000000000000945.
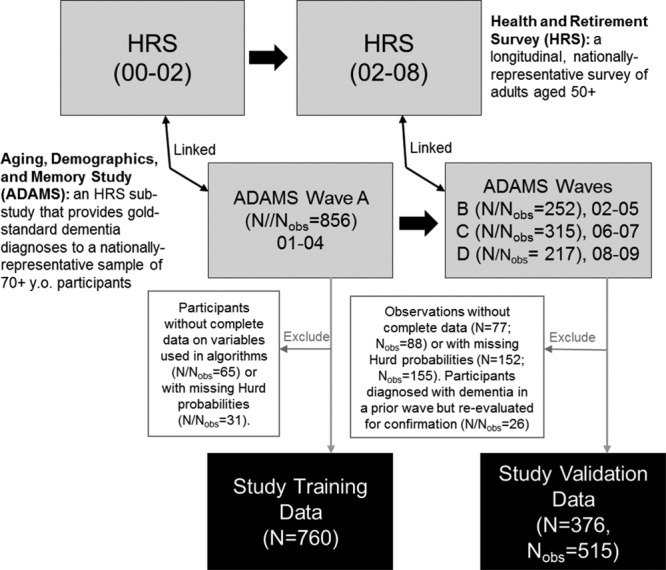
Dementia ascertainment is time-consuming and costly. Several algorithms use existing data from the US-representative Health and Retirement Study (HRS) to algorithmically identify dementia. However, relative performance of these algorithms remains unknown.
We compared performance across five algorithms (Herzog-Wallace, Langa-Kabeto-Weir, Crimmins, Hurd, Wu) overall and within sociodemographic subgroups in participants in HRS and Wave A of the Aging, Demographics, and Memory Study (ADAMS, 2000-2002), an HRS substudy including in-person dementia ascertainment. We then compared algorithmic performance in an internal (time-split) validation dataset including participants of HRS and ADAMS Waves B, C, and/or D (2002-2009).
In the unweighted training data, sensitivity ranged from 53% to 90%, specificity ranged from 79% to 97%, and overall accuracy ranged from 81% to 87%. Though sensitivity was lower in the unweighted validation data (range: 18%-62%), overall accuracy was similar (range: 79%-88%) due to higher specificities (range: 82%-98%). In analyses weighted to represent the age-eligible US population, accuracy ranged from 91% to 94% in the training data and 87% to 94% in the validation data. Using a 0.5 probability cutoff, Crimmins maximized sensitivity, Herzog-Wallace maximized specificity, and Wu and Hurd maximized accuracy. Accuracy was higher among younger, highly-educated, and non-Hispanic white participants versus their complements in both weighted and unweighted analyses.
Algorithmic diagnoses provide a cost-effective way to conduct dementia research. However, naïve use of existing algorithms in disparities or risk factor research may induce nonconservative bias. Algorithms with more comparable performance across relevant subgroups are needed.
痴呆症的确定既费时又费钱。有几种算法使用来自具有美国代表性的健康与退休研究(HRS)中的现有数据,通过算法来识别痴呆症。然而,这些算法的相对性能仍不清楚。
我们在 HRS 参与者和老龄化、人口统计学和记忆研究(ADAMS,2000-2002 年)的 A 波中比较了五种算法(Herzog-Wallace、Langa-Kabeto-Weir、Crimmins、Hurd、Wu)的总体表现和在社会人口统计学亚组中的表现,ADAMS 是 HRS 的一个子研究,包括现场痴呆症的确定。然后,我们在包括 HRS 和 ADAMS 波 B、C 和/或 D(2002-2009 年)的参与者的内部(时间分割)验证数据集上比较了算法性能。
在未加权的训练数据中,敏感性范围为 53%至 90%,特异性范围为 79%至 97%,总准确性范围为 81%至 87%。虽然未加权验证数据中的敏感性较低(范围为 18%-62%),但由于特异性较高(范围为 82%-98%),总准确性相似(范围为 79%-88%)。在加权以代表符合年龄要求的美国人群的分析中,训练数据中的准确性范围为 91%至 94%,验证数据中的准确性范围为 87%至 94%。使用 0.5 概率截止值,Crimmins 最大化了敏感性,Herzog-Wallace 最大化了特异性,Wu 和 Hurd 最大化了准确性。在加权和未加权分析中,与年龄较大、受教育程度较高和非西班牙裔白人的对照组相比,年轻、受教育程度较高和非西班牙裔白人参与者的准确性更高。
算法诊断为进行痴呆症研究提供了一种具有成本效益的方法。然而,在差异或风险因素研究中盲目使用现有的算法可能会引起非保守偏见。需要具有更可比性能的算法,以适应相关亚组。