Noh Jiho, Kavuluru Ramakanth
Department of Computer Science, University of Kentucky, Lexington KY.
Div. of Biomedical Informatics (Internal Medicine), University of Kentucky, Lexington KY.
Proc Int Conf Mach Learn Appl. 2018 Dec;2018:194-201. doi: 10.1109/ICMLA.2018.00036. Epub 2019 Jan 17.
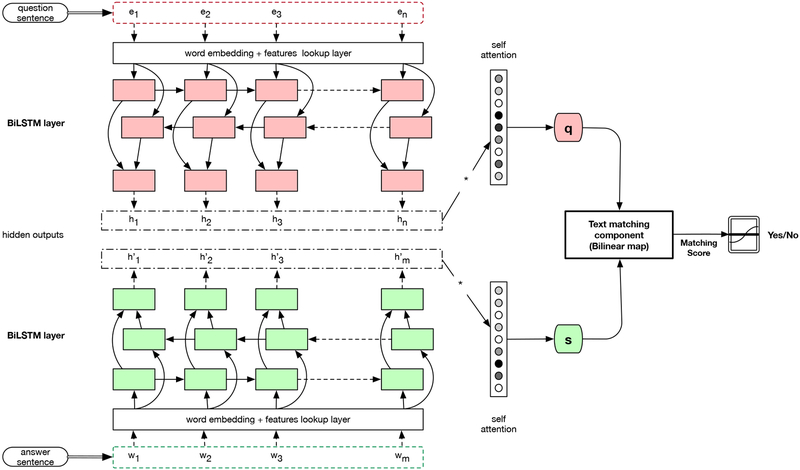
Document retrieval (DR) forms an important component in end-to-end question-answering (QA) systems where particular answers are sought for well-formed questions. DR in the QA scenario is also useful by itself even without a more involved natural language processing component to extract exact answers from the retrieved documents. This latter step may simply be done by humans like in traditional search engines granted the retrieved documents contain the answer. In this paper, we take advantage of datasets made available through the BioASQ end-to-end QA shared task series and build an effective biomedical DR system that relies on relevant answer snippets in the BioASQ training datasets. At the core of our approach is a question-answer sentence matching neural network that learns a measure of relevance of a sentence to an input question in the form of a matching score. In addition to this matching score feature, we also exploit two auxiliary features for scoring document relevance: the name of the journal in which a document is published and the presence/absence of semantic relations (subject-predicate-object triples) in a candidate answer sentence connecting entities mentioned in the question. We rerank our baseline sequential dependence model scores using these three additional features weighted via adaptive random research and other learning-to-rank methods. Our full system placed 2nd in the final batch of Phase A (DR) of task B (QA) in BioASQ 2018. Our ablation experiments highlight the significance of the neural matching network component in the full system.
文档检索(DR)是端到端问答(QA)系统的一个重要组成部分,在该系统中,人们针对格式良好的问题寻求特定答案。即使没有更复杂的自然语言处理组件从检索到的文档中提取确切答案,QA场景中的DR本身也很有用。如果检索到的文档包含答案,后一步骤可以像在传统搜索引擎中那样简单地由人工完成。在本文中,我们利用通过BioASQ端到端QA共享任务系列提供的数据集,构建了一个有效的生物医学DR系统,该系统依赖于BioASQ训练数据集中的相关答案片段。我们方法的核心是一个问答句子匹配神经网络,它以匹配分数的形式学习句子与输入问题的相关性度量。除了这个匹配分数特征外,我们还利用两个辅助特征来对文档相关性进行评分:文档发表所在期刊的名称以及候选答案句子中是否存在连接问题中提到的实体的语义关系(主谓宾三元组)。我们使用通过自适应随机搜索和其他排序学习方法加权的这三个附加特征对我们的基线顺序依赖模型分数进行重新排序。我们的完整系统在2018年BioASQ任务B(QA)的A阶段(DR)的最后一批中排名第二。我们的消融实验突出了完整系统中神经匹配网络组件的重要性。