Department of Physics, Chuo University, 1-13-27 Kasuga, Bunkyo-ku, Tokyo, 112-8551, Japan.
BMC Bioinformatics. 2019 Feb 4;19(Suppl 13):388. doi: 10.1186/s12859-018-2395-8.
Although in silico drug discovery is necessary for drug development, two major strategies, a structure-based and ligand-based approach, have not been completely successful. Currently, the third approach, inference of drug candidates from gene expression profiles obtained from the cells treated with the compounds under study requires the use of a training dataset. Here, the purpose was to develop a new approach that does not require any pre-existing knowledge about the drug-protein interactions, but these interactions can be inferred by means of an integrated approach using gene expression profiles obtained from the cells treated with the analysed compounds and the existing data describing gene-gene interactions.
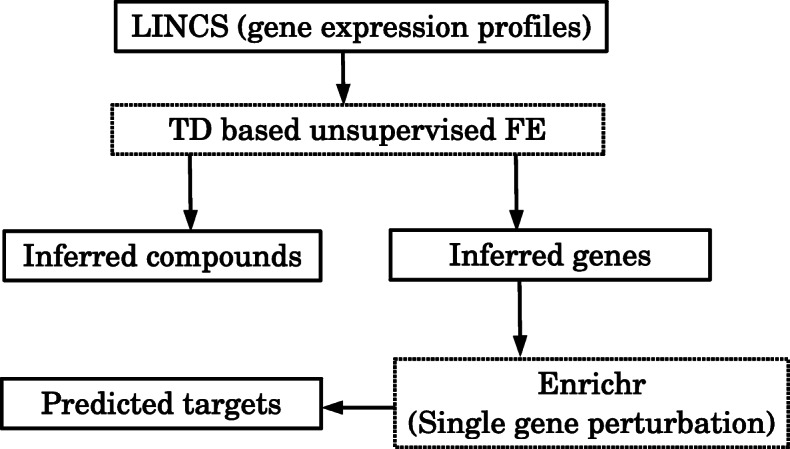
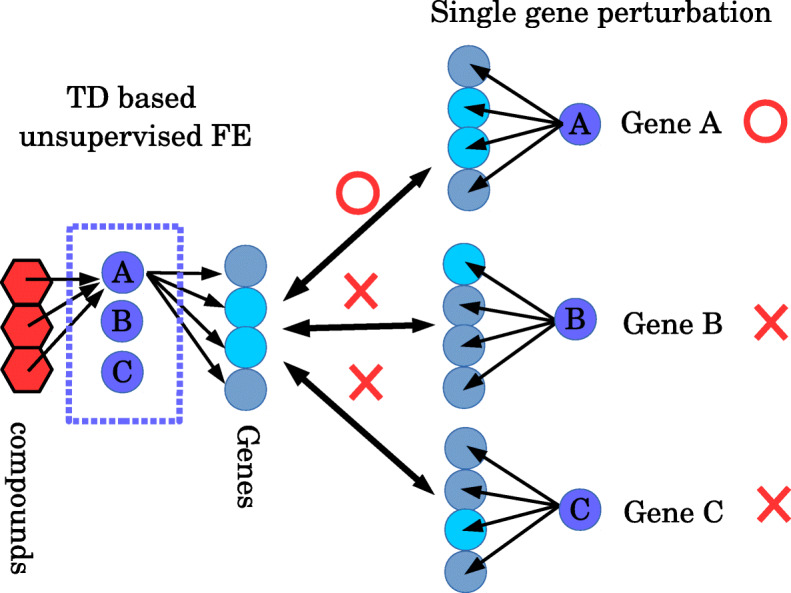
In the present study, using tensor decomposition-based unsupervised feature extraction, which represents an extension of the recently proposed principal-component analysis-based feature extraction, gene sets and compounds with a significant dose-dependent activity were screened without any training datasets. Next, after these results were combined with the data showing perturbations in single-gene expression profiles, genes targeted by the analysed compounds were inferred. The set of target genes thus identified was shown to significantly overlap with known target genes of the compounds under study.
The method is specifically designed for large-scale datasets (including hundreds of treatments with compounds), not for conventional small-scale datasets. The obtained results indicate that two compounds that have not been extensively studied, WZ-3105 and CGP-60474, represent promising drug candidates targeting multiple cancers, including melanoma, adenocarcinoma, liver carcinoma, and breast, colon, and prostate cancers, which were analysed in this in silico study.
虽然基于计算机的药物发现对于药物开发是必要的,但两种主要策略,基于结构和基于配体的方法,并没有完全成功。目前,第三种方法,即从用研究化合物处理的细胞获得的基因表达谱推断候选药物,需要使用训练数据集。在这里,目的是开发一种不需要任何关于药物-蛋白质相互作用的先验知识的新方法,但这些相互作用可以通过使用从用分析化合物处理的细胞获得的基因表达谱和描述基因-基因相互作用的现有数据进行综合方法推断出来。
在本研究中,使用基于张量分解的无监督特征提取(这是最近提出的基于主成分分析的特征提取的扩展),在没有任何训练数据集的情况下筛选出具有显著剂量依赖性活性的基因集和化合物。然后,将这些结果与显示单个基因表达谱扰动的数据结合起来,推断出分析化合物靶向的基因。由此确定的靶基因集与研究中化合物的已知靶基因显著重叠。
该方法是专门为大规模数据集(包括数百种化合物的处理)设计的,而不是为传统的小规模数据集设计的。所获得的结果表明,两种尚未广泛研究的化合物,WZ-3105 和 CGP-60474,是针对多种癌症(包括黑色素瘤、腺癌、肝癌和乳腺癌、结肠癌和前列腺癌)的有前途的候选药物,这在本次计算机研究中进行了分析。