Nyambo Devotha G, Luhanga Edith T, Yonah Zaipuna O, Mujibi Fidalis D N
Nelson Mandela African Institution of Science and Technology, P.O. Box 447, Arusha, Tanzania.
USOMI Limited, P.O. Box 105086-00101, Nairobi, Kenya.
ScientificWorldJournal. 2019 Jan 2;2019:1020521. doi: 10.1155/2019/1020521. eCollection 2019.
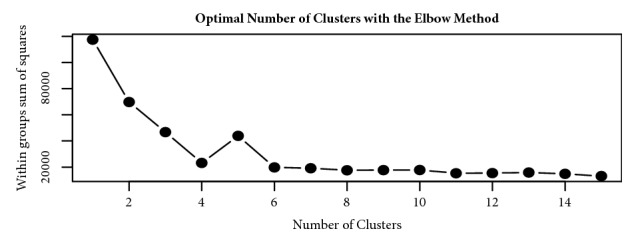
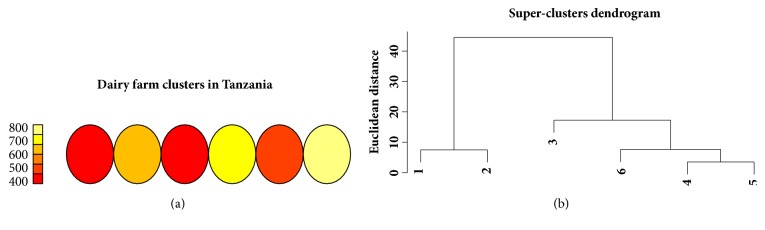
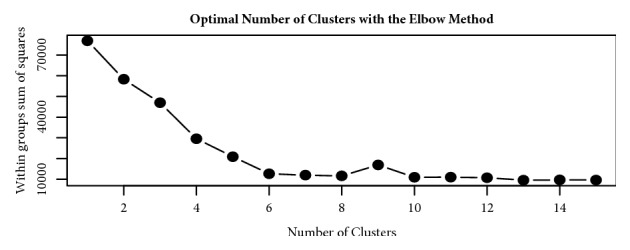
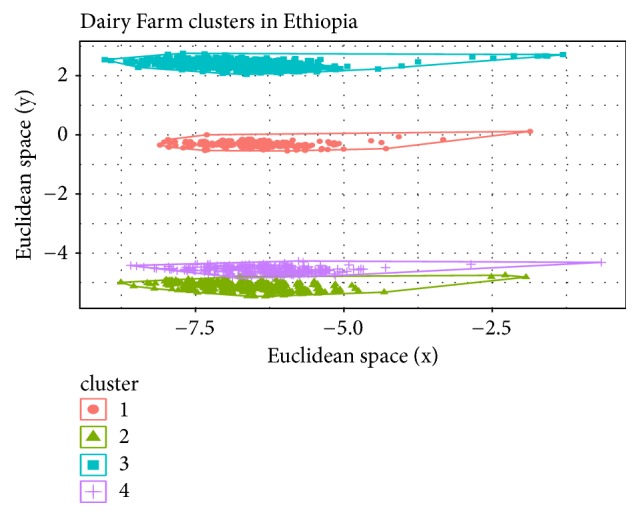
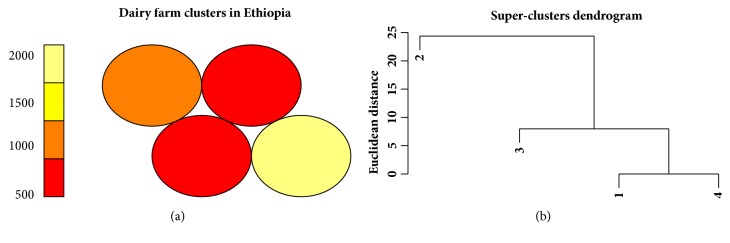
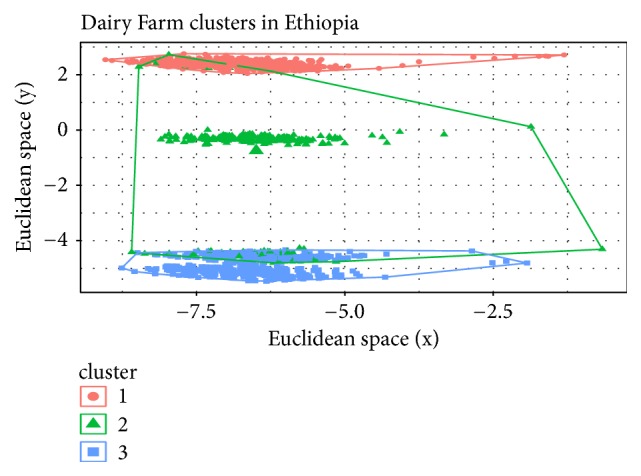
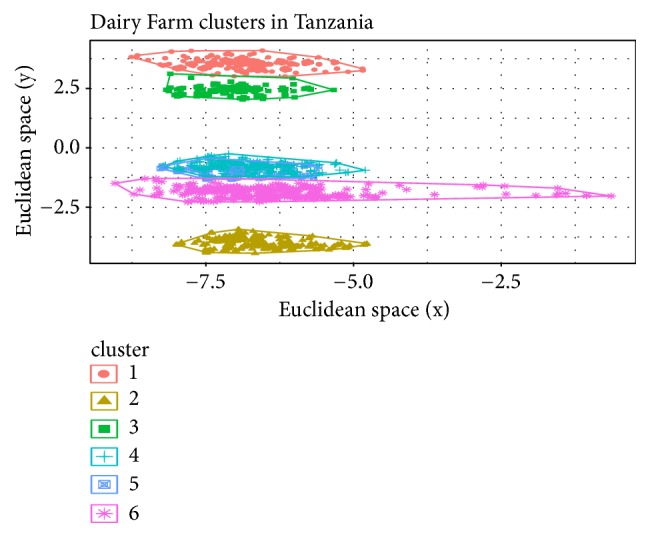
The heterogeneity of smallholder dairy production systems complicates service provision, information sharing, and dissemination of new technologies, especially those needed to maximize productivity and profitability. In order to obtain homogenous groups within which interventions can be made, it is necessary to define clusters of farmers who undertake similar management activities. This paper explores robustness of production cluster definition using various unsupervised learning algorithms to assess the best approach to define clusters. Data were collected from 8179 smallholder dairy farms in Ethiopia and Tanzania. From a total of 500 variables, selection of the 35 variables used in defining production clusters and household membership to these clusters was determined by Principal Component Analysis and domain expert knowledge. Three clustering algorithms, K-means, fuzzy, and Self-Organizing Maps (SOM), were compared in terms of their grouping consistency and prediction accuracy. The model with the least household reallocation between clusters for training and testing data was deemed the most robust. Prediction accuracy was obtained by fitting a model with fixed effects model including production clusters on milk yield, sales, and choice of breeding method. Results indicated that, for the Ethiopian dataset, clusters derived from the fuzzy algorithm had the highest predictive power (77% for milk yield and 48% for milk sales), while for the Tanzania data, clusters derived from Self-Organizing Maps were the best performing. The average cluster membership reallocation was 15%, 12%, and 34% for K-means, SOM, and fuzzy, respectively, for households in Ethiopia. Based on the divergent performance of the various algorithms evaluated, it is evident that, despite similar information being available for the study populations, the uniqueness of the data from each country provided an over-riding influence on cluster robustness and prediction accuracy. The results obtained in this study demonstrate the difficulty of generalizing model application and use across countries and production systems, despite seemingly similar information being collected.
小农户乳制品生产系统的异质性使得服务提供、信息共享和新技术传播变得复杂,尤其是那些为实现生产力和盈利能力最大化所需的技术。为了获得能够进行干预的同质化群体,有必要界定从事相似管理活动的农户集群。本文运用各种无监督学习算法探索生产集群定义的稳健性,以评估定义集群的最佳方法。数据收集自埃塞俄比亚和坦桑尼亚的8179个小农户奶牛场。在总共500个变量中,用于定义生产集群及农户在这些集群中的成员身份的35个变量是通过主成分分析和领域专家知识确定的。比较了三种聚类算法,即K均值算法、模糊算法和自组织映射(SOM)算法在分组一致性和预测准确性方面的表现。在训练和测试数据中,集群间农户重新分配最少的模型被认为是最稳健的。通过使用包含生产集群的固定效应模型拟合牛奶产量、销售额和育种方法选择的模型来获得预测准确性。结果表明,对于埃塞俄比亚数据集,模糊算法得出的集群具有最高的预测能力(牛奶产量预测能力为77%,牛奶销售额预测能力为48%),而对于坦桑尼亚的数据,自组织映射算法得出的集群表现最佳。对于埃塞俄比亚的农户,K均值算法、SOM算法和模糊算法的平均集群成员重新分配率分别为15%、12%和34%。基于所评估的各种算法的不同表现,很明显,尽管研究对象可获得相似的信息,但每个国家数据的独特性对集群稳健性和预测准确性产生了压倒性影响。本研究所得结果表明,尽管收集的信息看似相似,但在不同国家和生产系统中推广模型应用和使用存在困难。