Russian Research Institute of Farm Animal Genetics and Breeding - Branch of the L. K. Ernst Research Science Center for Animal Husbandry, Pushkin, St. Petersburg, Russia.
Research Institute for Environment Treatment, Zaporozhye, Ukraine.
Sci Rep. 2023 Feb 27;13(1):3319. doi: 10.1038/s41598-023-28651-8.
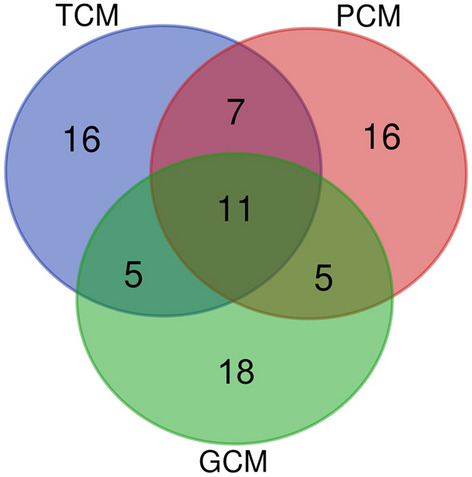
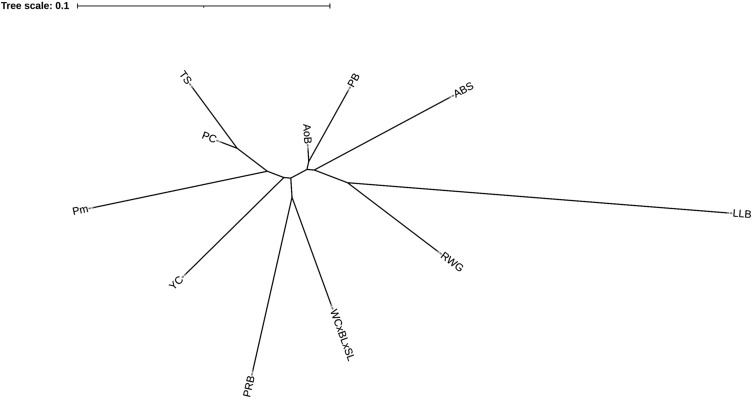
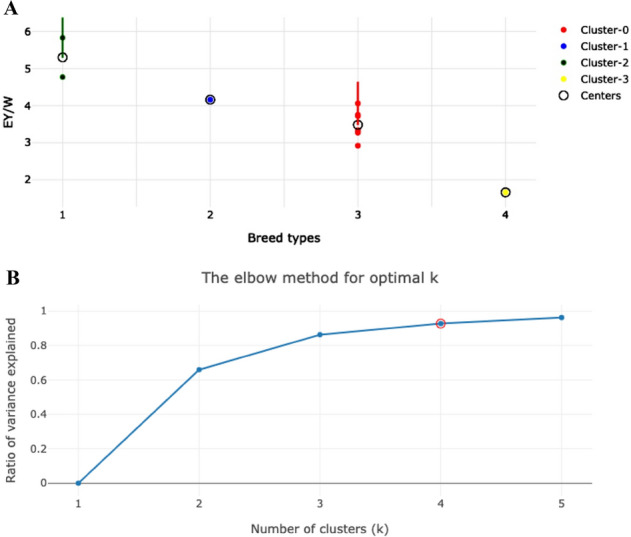
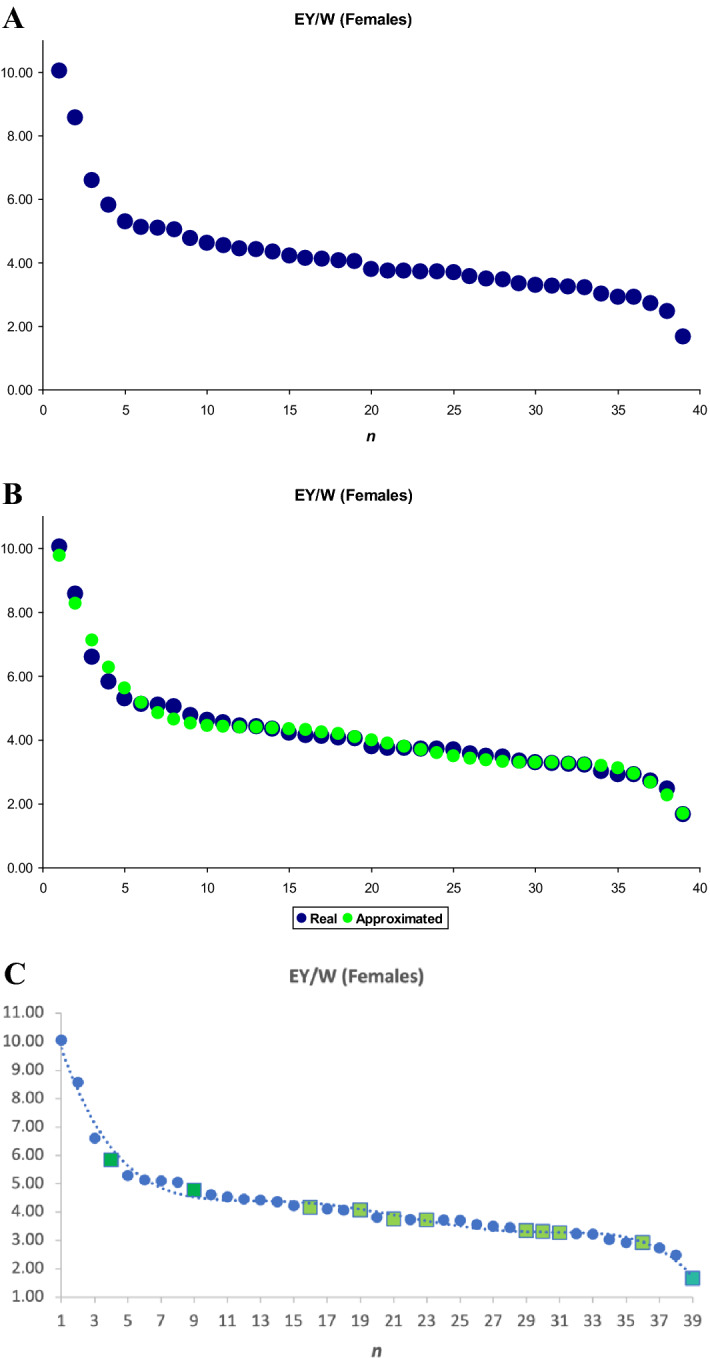
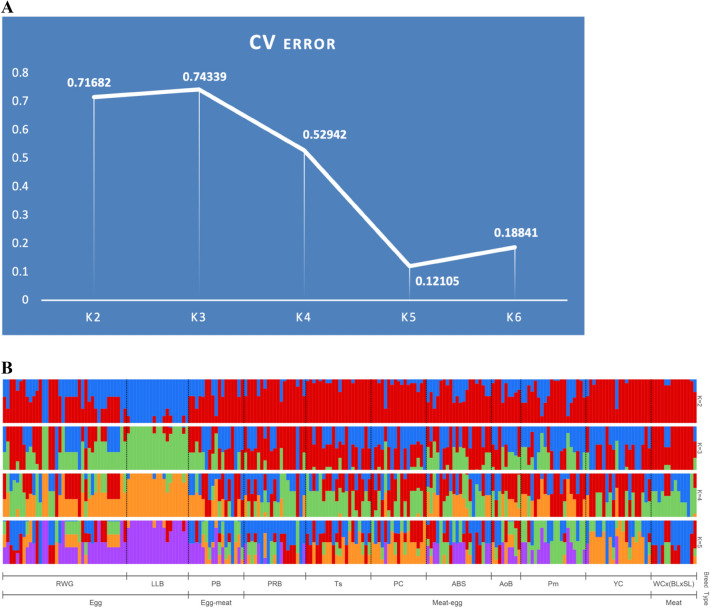
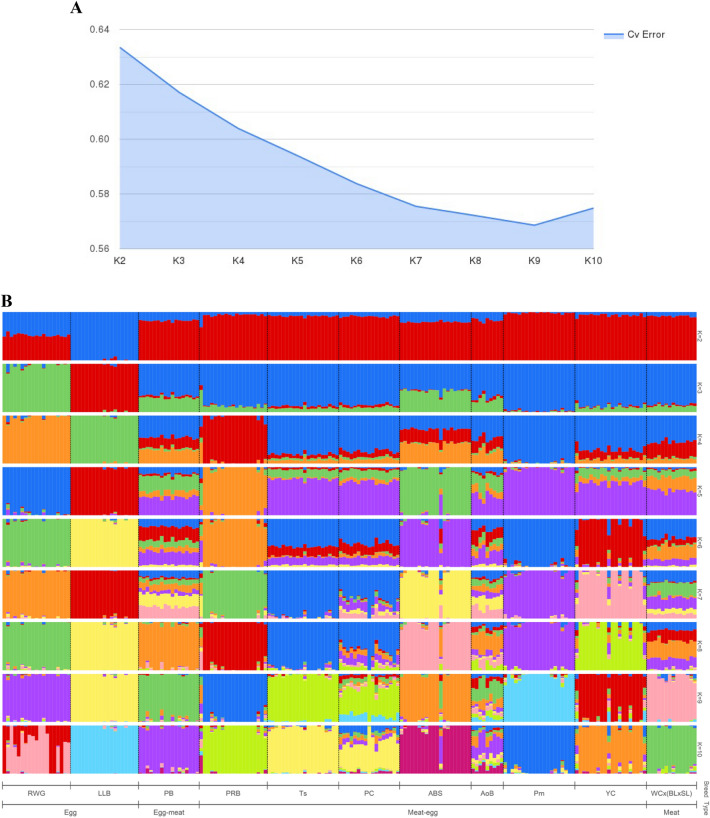
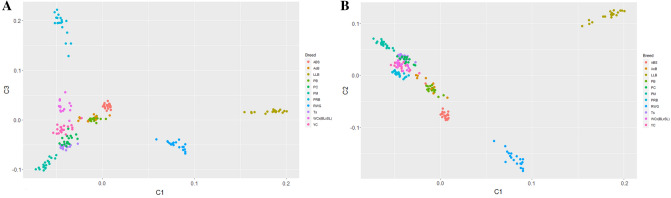
Divergently selected chicken breeds are of great interest not only from an economic point of view, but also in terms of sustaining diversity of the global poultry gene pool. In this regard, it is essential to evaluate the classification (clustering) of varied chicken breeds using methods and models based on phenotypic and genotypic breed differences. It is also important to implement new mathematical indicators and approaches. Accordingly, we set the objectives to test and improve clustering algorithms and models to discriminate between various chicken breeds. A representative portion of the global chicken gene pool including 39 different breeds was examined in terms of an integral performance index, i.e., specific egg mass yield relative to body weight of females. The generated dataset was evaluated within the traditional, phenotypic and genotypic classification/clustering models using the k-means method, inflection points clustering, and admixture analysis. The latter embraced SNP genotype datasets including a specific one focused on the performance-associated NCAPG-LCORL locus. The k-means and inflection points analyses showed certain discrepancies between the tested models/submodels and flaws in the produced cluster configurations. On the other hand, 11 core breeds were identified that were shared between the examined models and demonstrated more adequate clustering and admixture patterns. These findings will lay the foundation for future research to improve methods for clustering as well as genome- and phenome-wide association/mediation analyses.
从经济角度来看,具有不同特性的鸡种不仅受到关注,而且对于维持全球家禽基因库的多样性也具有重要意义。从这方面来说,使用基于表型和基因型品种差异的方法和模型来评估不同鸡种的分类(聚类)是至关重要的。此外,实施新的数学指标和方法也很重要。因此,我们的目标是测试和改进聚类算法和模型,以区分不同的鸡种。我们检查了全球鸡种基因库的代表性部分,包括 39 个不同的品种,根据综合性能指数,即雌性特定蛋质量与体重的相对产量来评估。在传统的、表型和基因型分类/聚类模型中,使用 k-均值方法、拐点聚类和混合分析评估了生成的数据集。后者包括一个特定的 SNP 基因型数据集,重点关注与性能相关的 NCAPG-LCORL 基因座。k-均值和拐点分析表明,测试模型/子模型之间存在某些差异,并且产生的聚类配置存在缺陷。另一方面,确定了 11 个核心品种,这些品种在被检查的模型之间共享,表现出更合适的聚类和混合模式。这些发现将为未来的研究奠定基础,以改进聚类方法以及全基因组和表型关联/中介分析。