Department of Computer Science and Center for Bioinformatics and Computational Biology, University of Maryland, College Park, USA.
Department of Biology, University of Washington, USA.
Nucleic Acids Res. 2019 May 21;47(9):e51. doi: 10.1093/nar/gkz132.
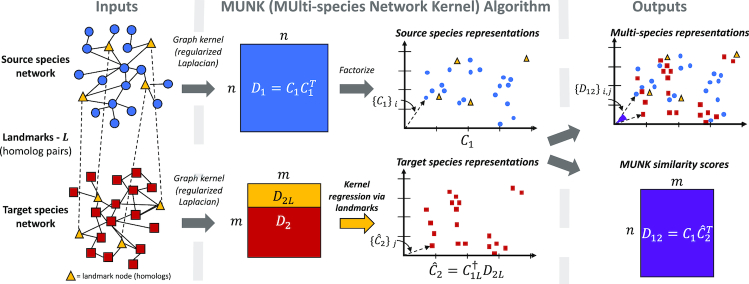
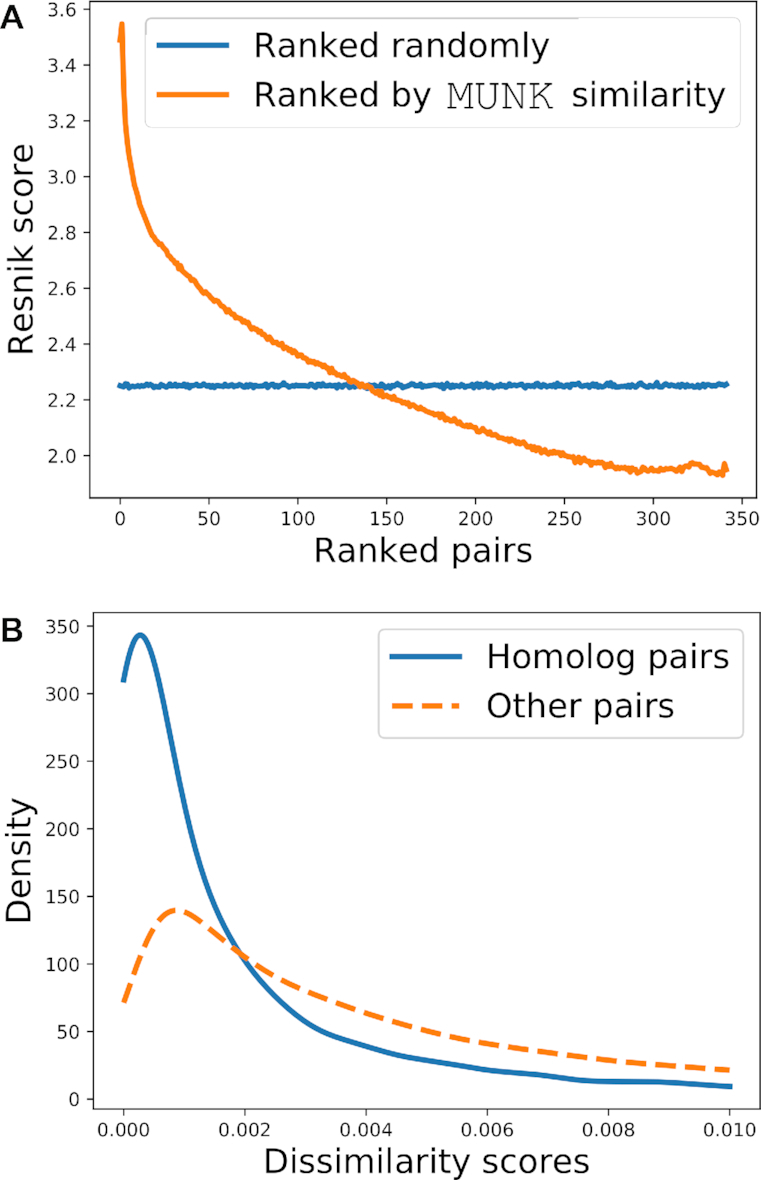
Transferring knowledge between species is key for many biological applications, but is complicated by divergent and convergent evolution. Many current approaches for this problem leverage sequence and interaction network data to transfer knowledge across species, exemplified by network alignment methods. While these techniques do well, they are limited in scope, creating metrics to address one specific problem or task. We take a different approach by creating an environment where multiple knowledge transfer tasks can be performed using the same protein representations. Specifically, our kernel-based method, MUNK, integrates sequence and network structure to create functional protein representations, embedding proteins from different species in the same vector space. First we show proteins in different species that are close in MUNK-space are functionally similar. Next, we use these representations to share knowledge of synthetic lethal interactions between species. Importantly, we find that the results using MUNK-representations are at least as accurate as existing algorithms for these tasks. Finally, we generalize the notion of a phenolog ('orthologous phenotype') to use functionally similar proteins (i.e. those with similar representations). We demonstrate the utility of this broadened notion by using it to identify known phenologs and novel non-obvious ones supported by current research.
在许多生物应用中,在物种之间转移知识是关键,但这受到趋异和趋同进化的影响。目前,许多针对该问题的方法都利用序列和相互作用网络数据在物种间转移知识,网络对齐方法就是一个很好的例子。虽然这些技术表现出色,但它们的范围有限,只能创建用于解决一个特定问题或任务的指标。我们采取了一种不同的方法,创建了一个环境,可以使用相同的蛋白质表示来执行多个知识转移任务。具体来说,我们的基于核的方法 MUNK 将序列和网络结构集成在一起,创建功能蛋白质表示,将不同物种的蛋白质嵌入到相同的向量空间中。首先,我们展示了在 MUNK 空间中接近的不同物种的蛋白质在功能上是相似的。接下来,我们使用这些表示来共享物种之间的合成致死相互作用的知识。重要的是,我们发现使用 MUNK 表示的结果至少与这些任务的现有算法一样准确。最后,我们将“表型(‘同源表型’)”的概念推广到使用功能相似的蛋白质(即具有相似表示的蛋白质)。我们通过使用它来识别已知的表型和当前研究支持的新的非明显表型来证明这个广义概念的实用性。