Department of Psychology, Center for Studies in Behavioral Neurobiology/Groupe de recherche en neurobiologie comportementale, Concordia University, Montreal, Quebec, Canada.
Department of Psychology, Brooklyn College of the City University of New York, Brooklyn, NY, USA.
Sci Rep. 2019 Apr 12;9(1):5962. doi: 10.1038/s41598-019-42244-4.
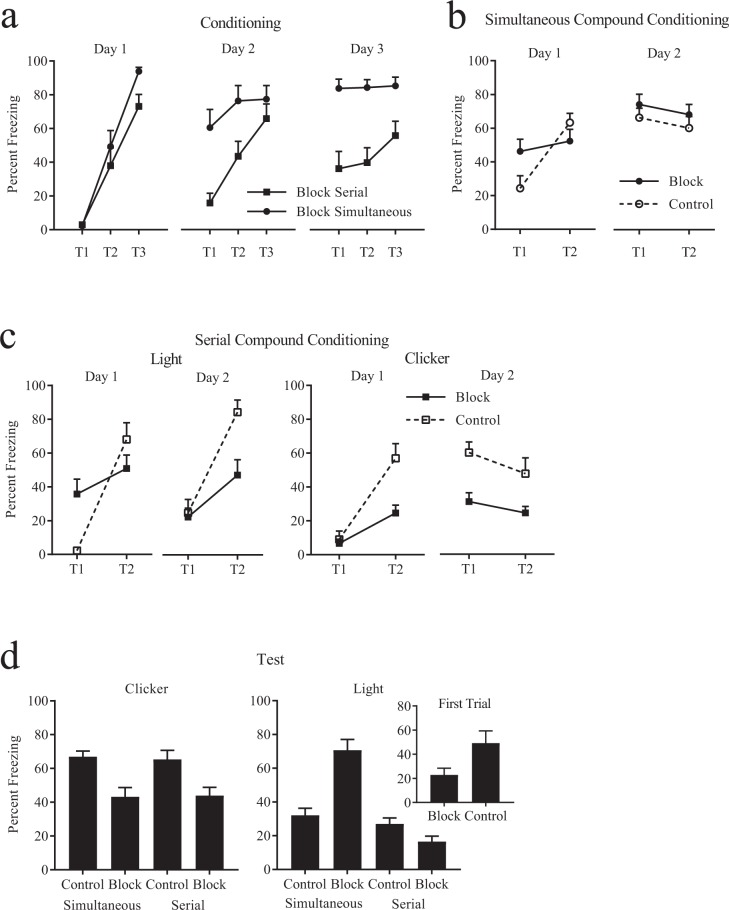
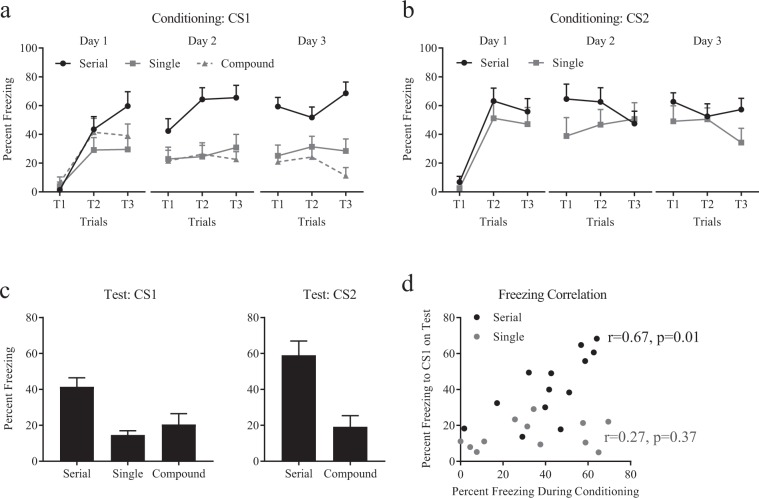
Temporal-difference (TD) learning models afford the neuroscientist a theory-driven roadmap in the quest for the neural mechanisms of reinforcement learning. The application of these models to understanding the role of phasic midbrain dopaminergic responses in reward prediction learning constitutes one of the greatest success stories in behavioural and cognitive neuroscience. Critically, the classic learning paradigms associated with TD are poorly suited to cast light on its neural implementation, thus hampering progress. Here, we present a serial blocking paradigm in rodents that overcomes these limitations and allows for the simultaneous investigation of two cardinal TD tenets; namely, that learning depends on the computation of a prediction error, and that reinforcing value, whether intrinsic or acquired, propagates back to the onset of the earliest reliable predictor. The implications of this paradigm for the neural exploration of TD mechanisms are highlighted.
时频差(TD)学习模型为神经科学家提供了一条理论驱动的路线,以探索强化学习的神经机制。将这些模型应用于理解中脑多巴胺能反应的相位在奖励预测学习中的作用,是行为和认知神经科学中最成功的案例之一。关键的是,与 TD 相关的经典学习范式不太适合揭示其神经实现,从而阻碍了进展。在这里,我们在啮齿动物中提出了一个序列阻断范式,克服了这些限制,并允许同时研究 TD 的两个主要原则;即学习取决于预测误差的计算,以及强化价值,无论是内在的还是获得的,都会传播到最早可靠预测器的开始。该范式对 TD 机制的神经探索的影响被强调了。