Wellcome/EPSRC Centre for Interventional and Surgical Sciences (WEISS), University College London, London, UK.
Digital Surgery Ltd., London, UK.
Int J Comput Assist Radiol Surg. 2019 Jul;14(7):1167-1176. doi: 10.1007/s11548-019-01962-w. Epub 2019 Apr 15.
Colorectal cancer is the third most common cancer worldwide, and early therapeutic treatment of precancerous tissue during colonoscopy is crucial for better prognosis and can be curative. Navigation within the colon and comprehensive inspection of the endoluminal tissue are key to successful colonoscopy but can vary with the skill and experience of the endoscopist. Computer-assisted interventions in colonoscopy can provide better support tools for mapping the colon to ensure complete examination and for automatically detecting abnormal tissue regions.
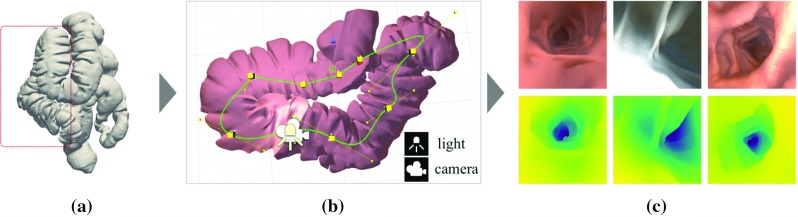
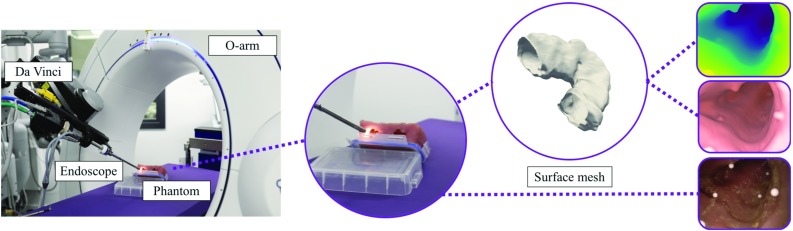
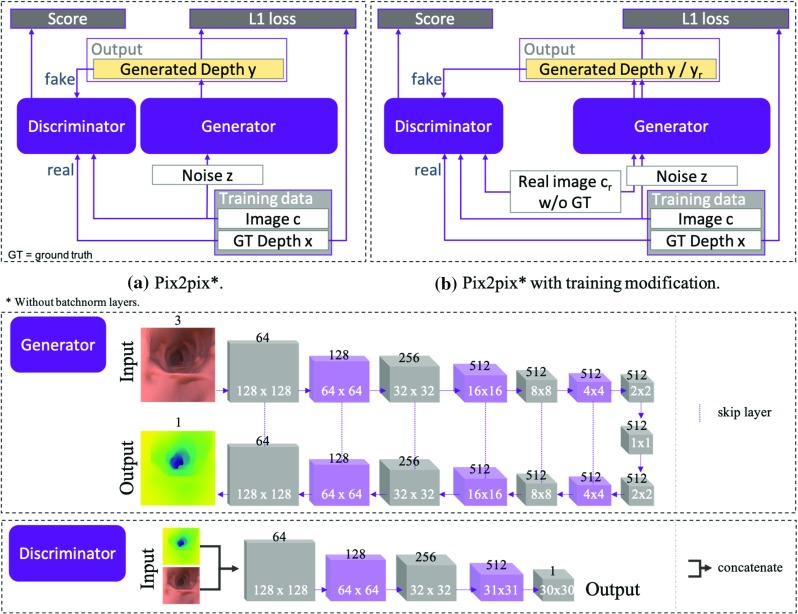
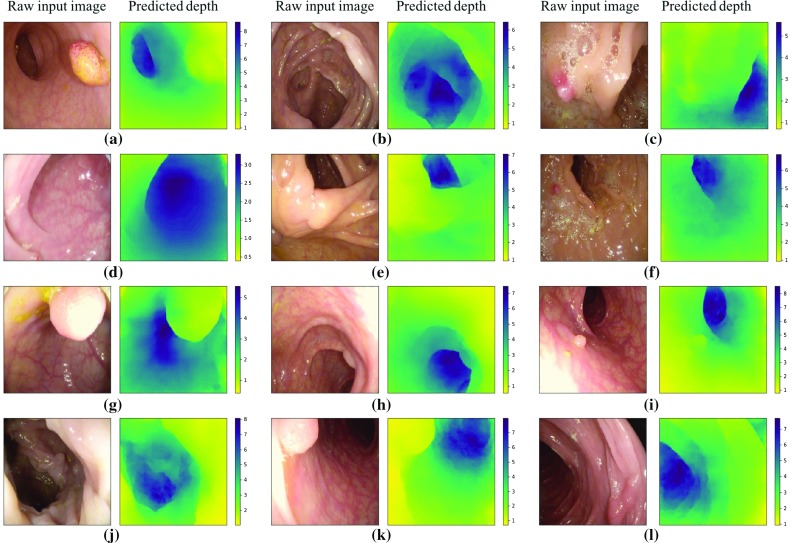
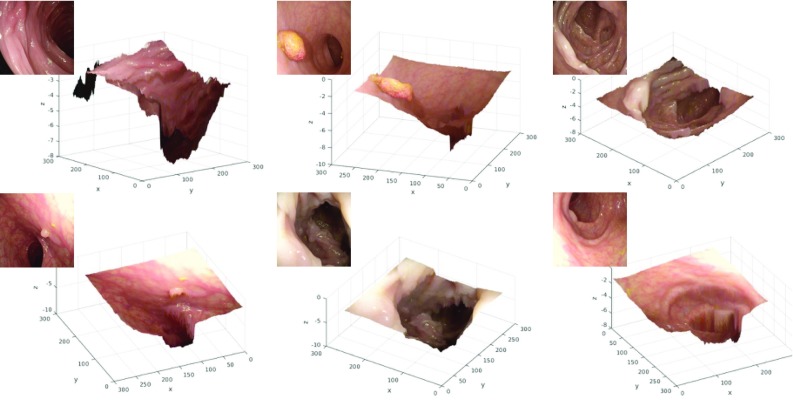
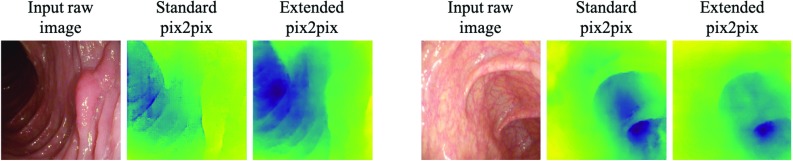
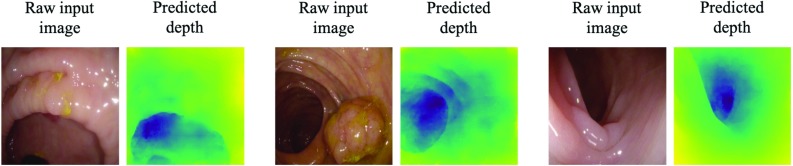
We train the conditional generative adversarial network pix2pix, to transform monocular endoscopic images to depth, which can be a building block in a navigational pipeline or be used to measure the size of polyps during colonoscopy. To overcome the lack of labelled training data in endoscopy, we propose to use simulation environments and to additionally train the generator and discriminator of the model on unlabelled real video frames in order to adapt to real colonoscopy environments.
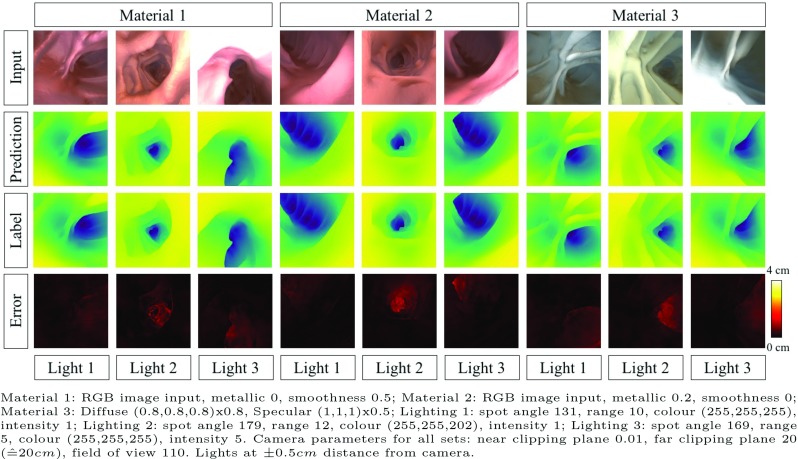
We report promising results on synthetic, phantom and real datasets and show that generative models outperform discriminative models when predicting depth from colonoscopy images, in terms of both accuracy and robustness towards changes in domains.
Training the discriminator and generator of the model on real images, we show that our model performs implicit domain adaptation, which is a key step towards bridging the gap between synthetic and real data. Importantly, we demonstrate the feasibility of training a single model to predict depth from both synthetic and real images without the need for explicit, unsupervised transformer networks mapping between the domains of synthetic and real data.
结直肠癌是全球第三大常见癌症,在结肠镜检查中对癌前组织进行早期治疗对于改善预后至关重要,并且可能具有治愈效果。在结肠内导航和对腔内组织进行全面检查是结肠镜检查成功的关键,但这可能因内镜医生的技能和经验而异。结肠镜检查中的计算机辅助干预可以为绘制结肠提供更好的支持工具,以确保全面检查,并自动检测异常组织区域。
我们训练条件生成对抗网络 pix2pix,将单目内窥镜图像转换为深度,这可以作为导航管道中的构建块,也可以用于在结肠镜检查中测量息肉的大小。为了克服内窥镜中缺乏标记训练数据的问题,我们建议使用模拟环境,并在未标记的真实视频帧上额外训练模型的生成器和判别器,以适应真实的结肠镜检查环境。
我们在合成、幻影和真实数据集上报告了有前景的结果,并表明在从结肠镜图像预测深度方面,生成模型优于判别模型,无论是在准确性方面还是在对域变化的稳健性方面。
通过在真实图像上训练模型的判别器和生成器,我们表明我们的模型执行了隐式域自适应,这是弥合合成数据和真实数据之间差距的关键步骤。重要的是,我们证明了仅使用单个模型从合成和真实图像预测深度的可行性,而无需在合成和真实数据域之间使用显式、无监督的转换器网络进行映射。