Department of Bioengineering and Therapeutic Sciences, University of California, San Francisco, USA.
Applied Science, BioPharmics LLC, Santa Rosa, CA, USA.
J Comput Aided Mol Des. 2019 Jun;33(6):531-558. doi: 10.1007/s10822-019-00203-1. Epub 2019 May 3.
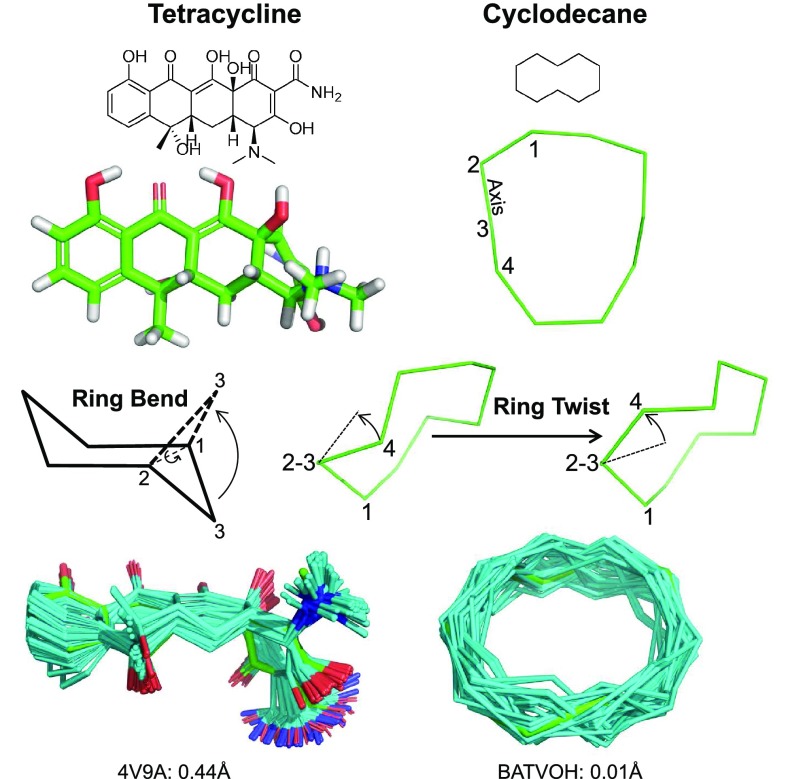
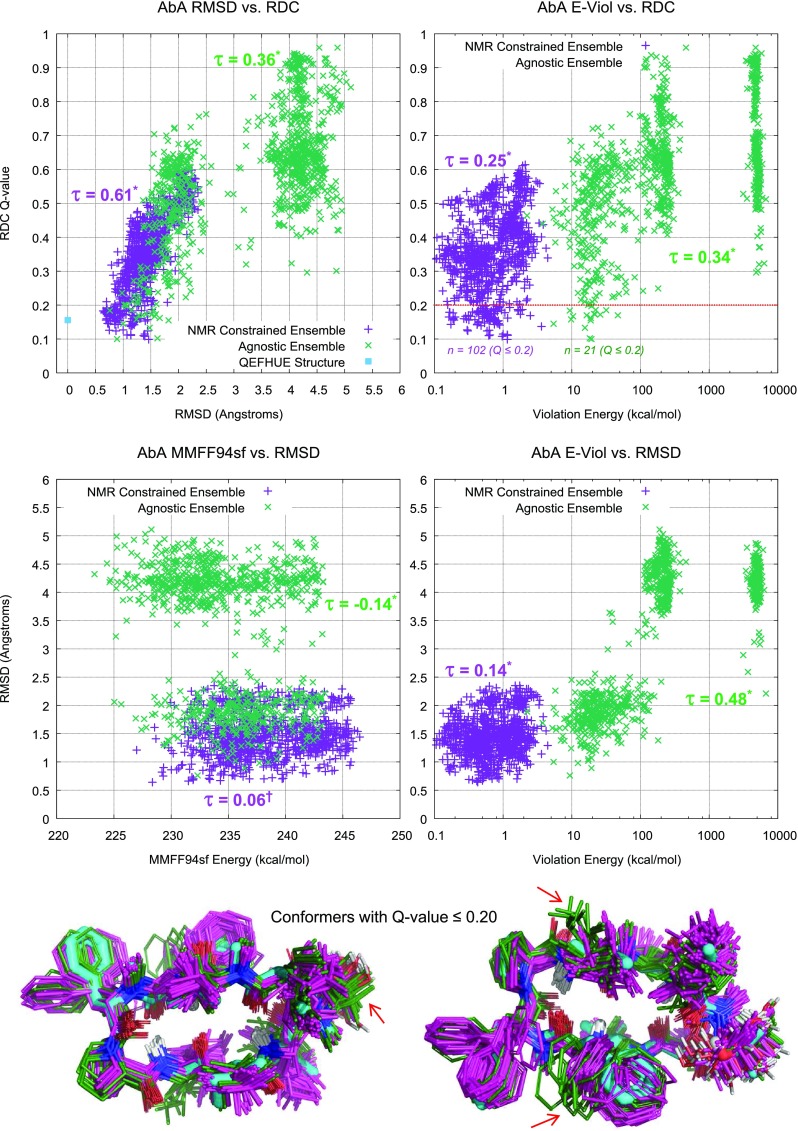
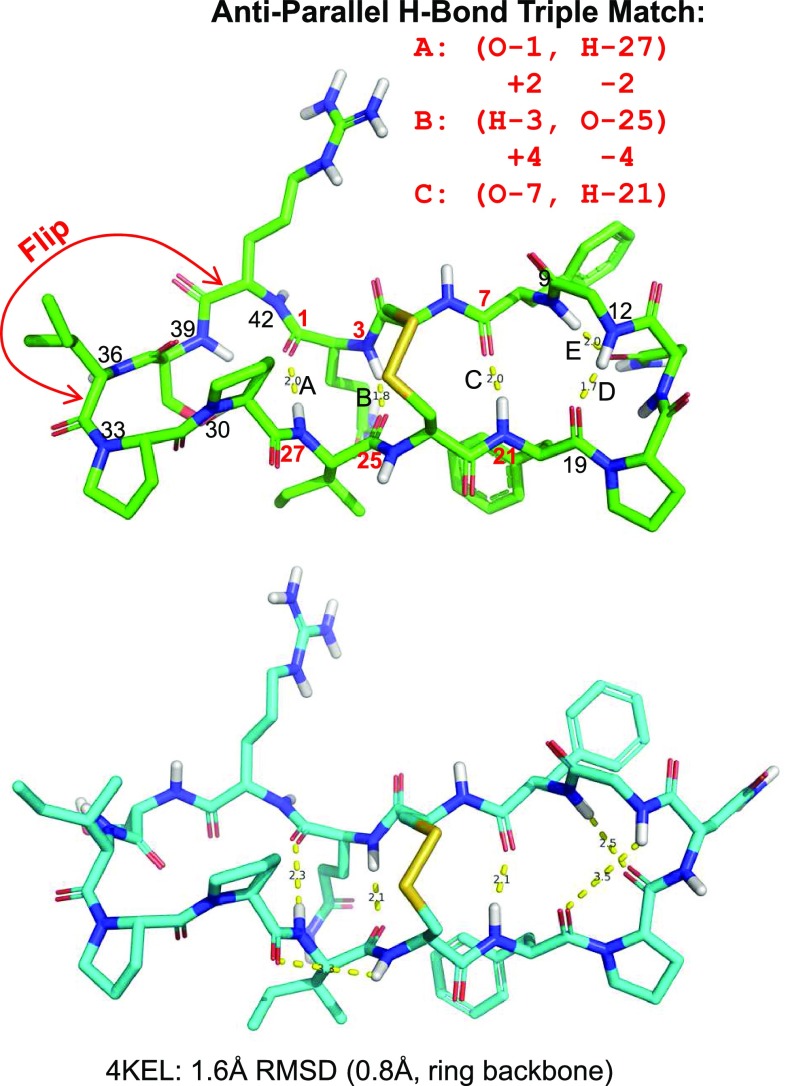
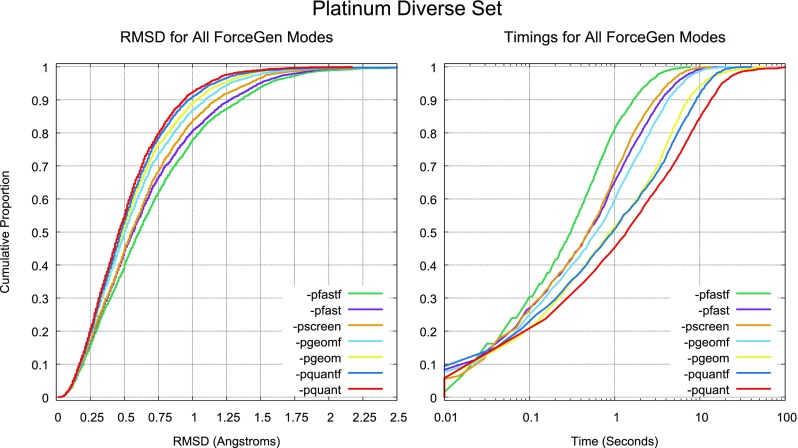
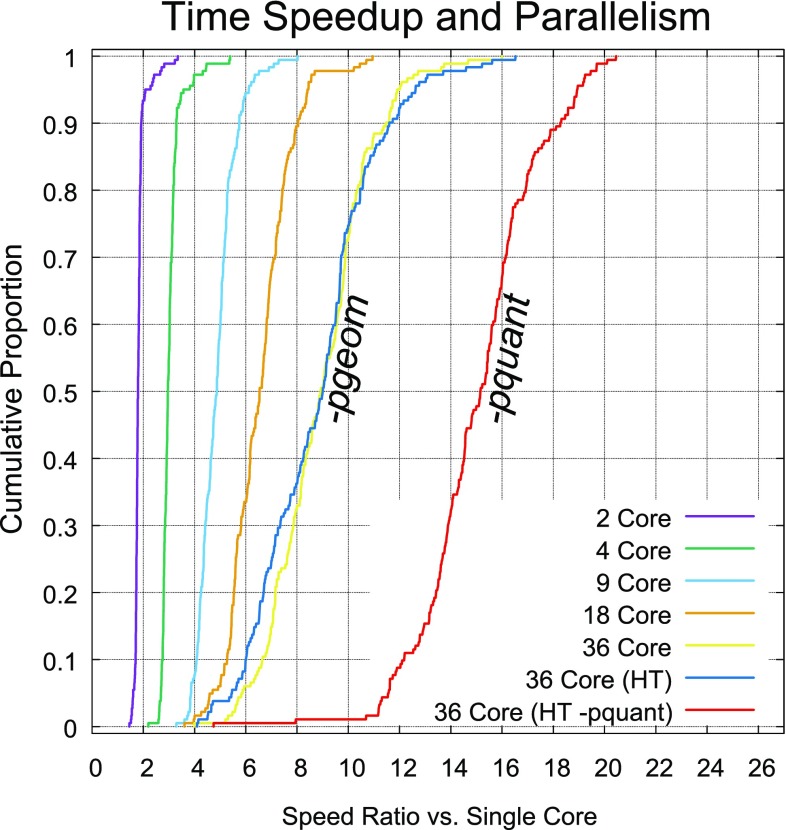
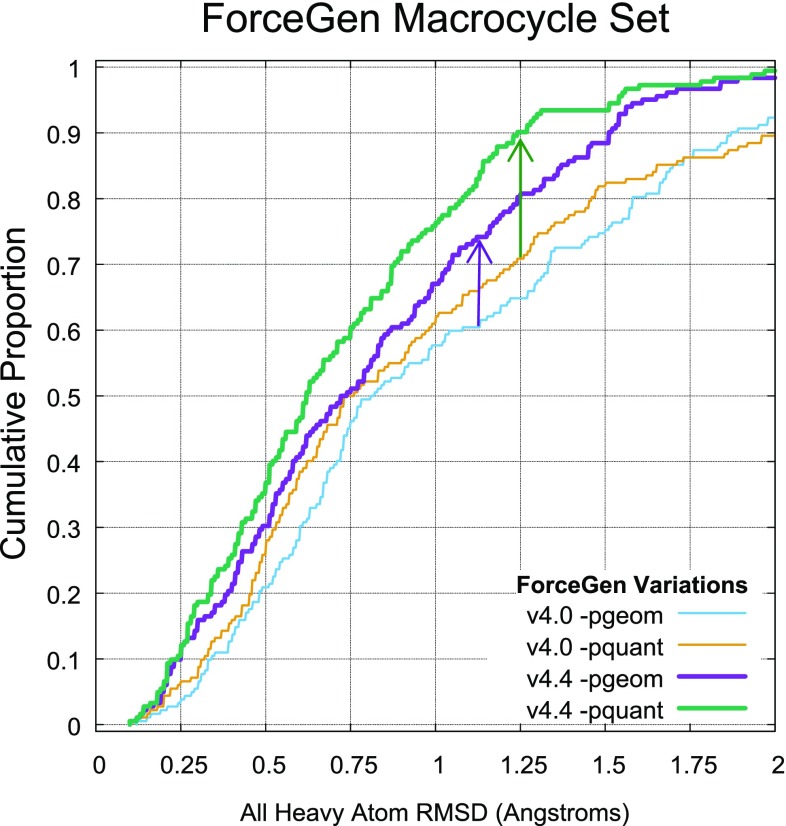
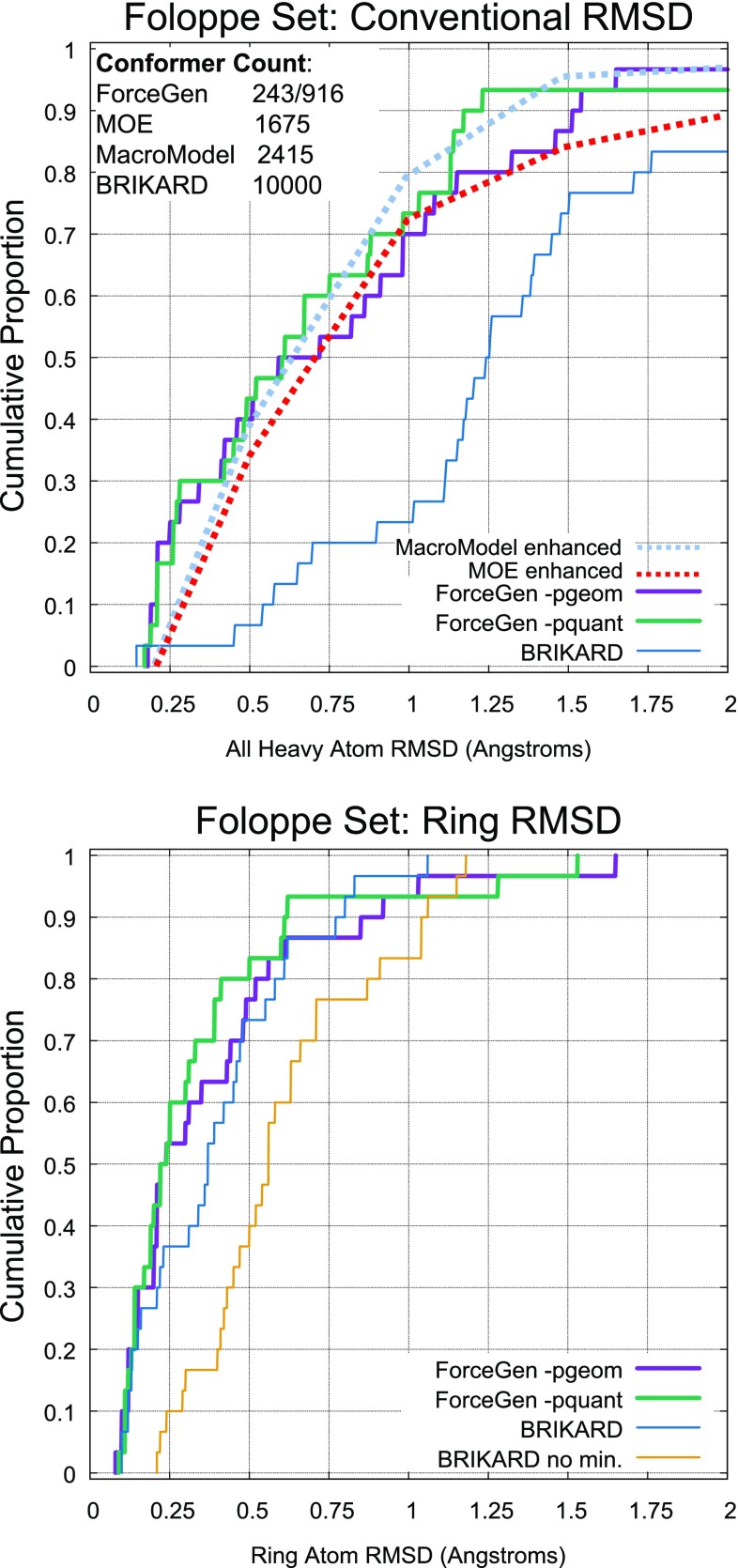
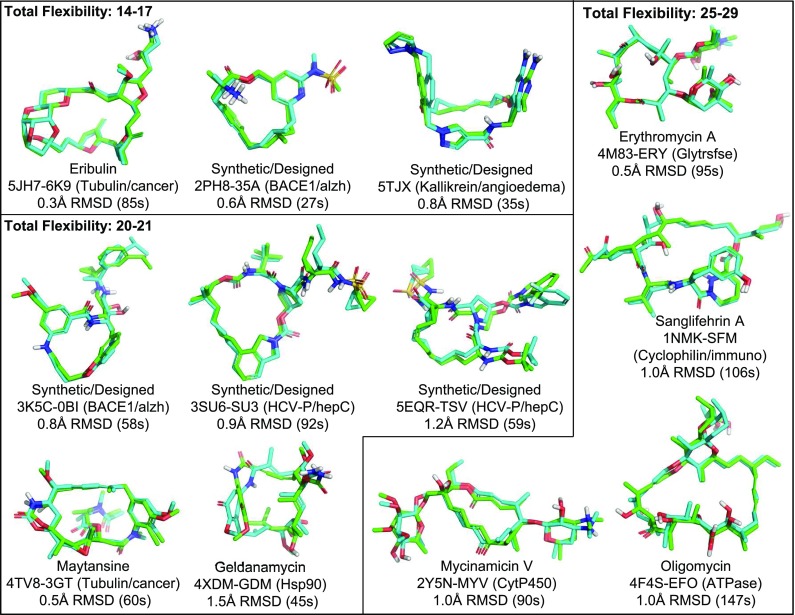
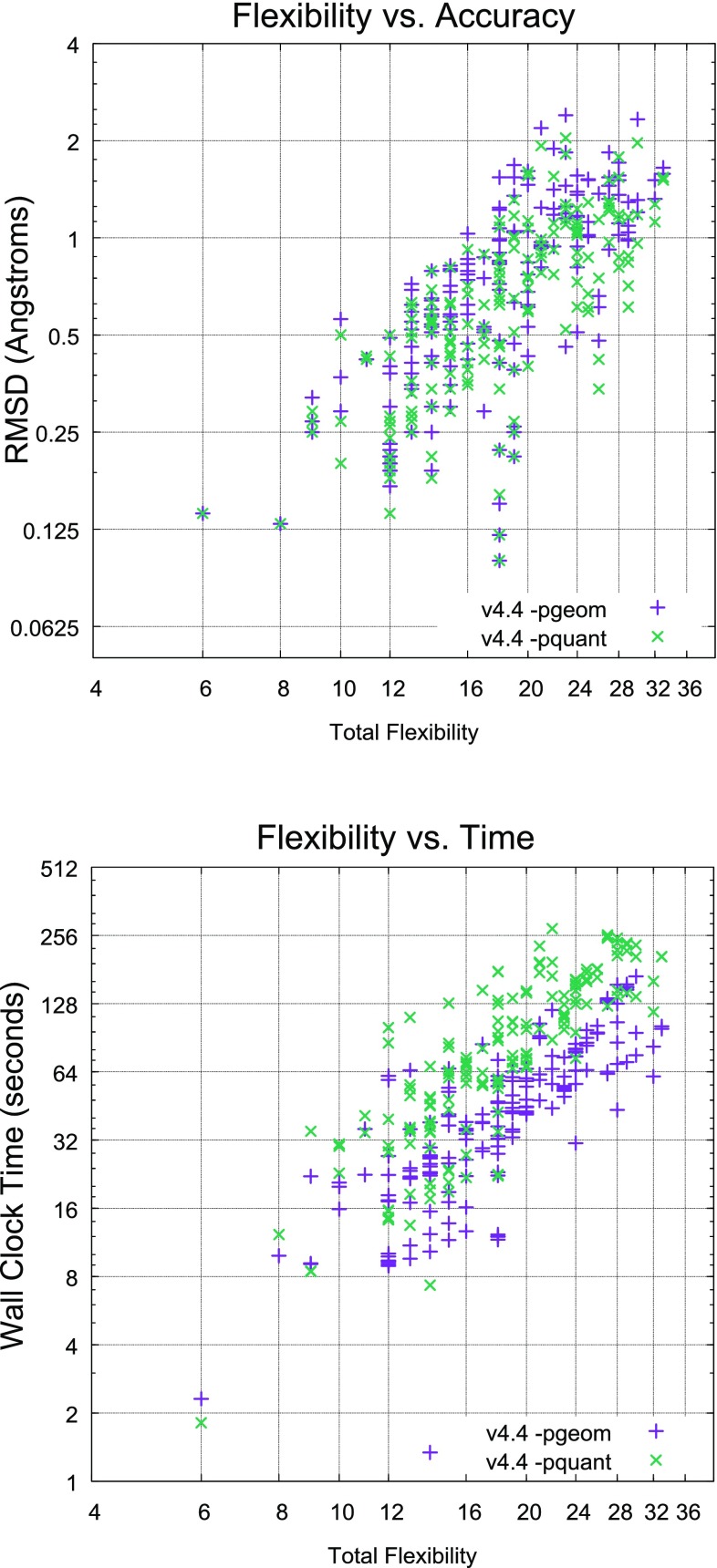
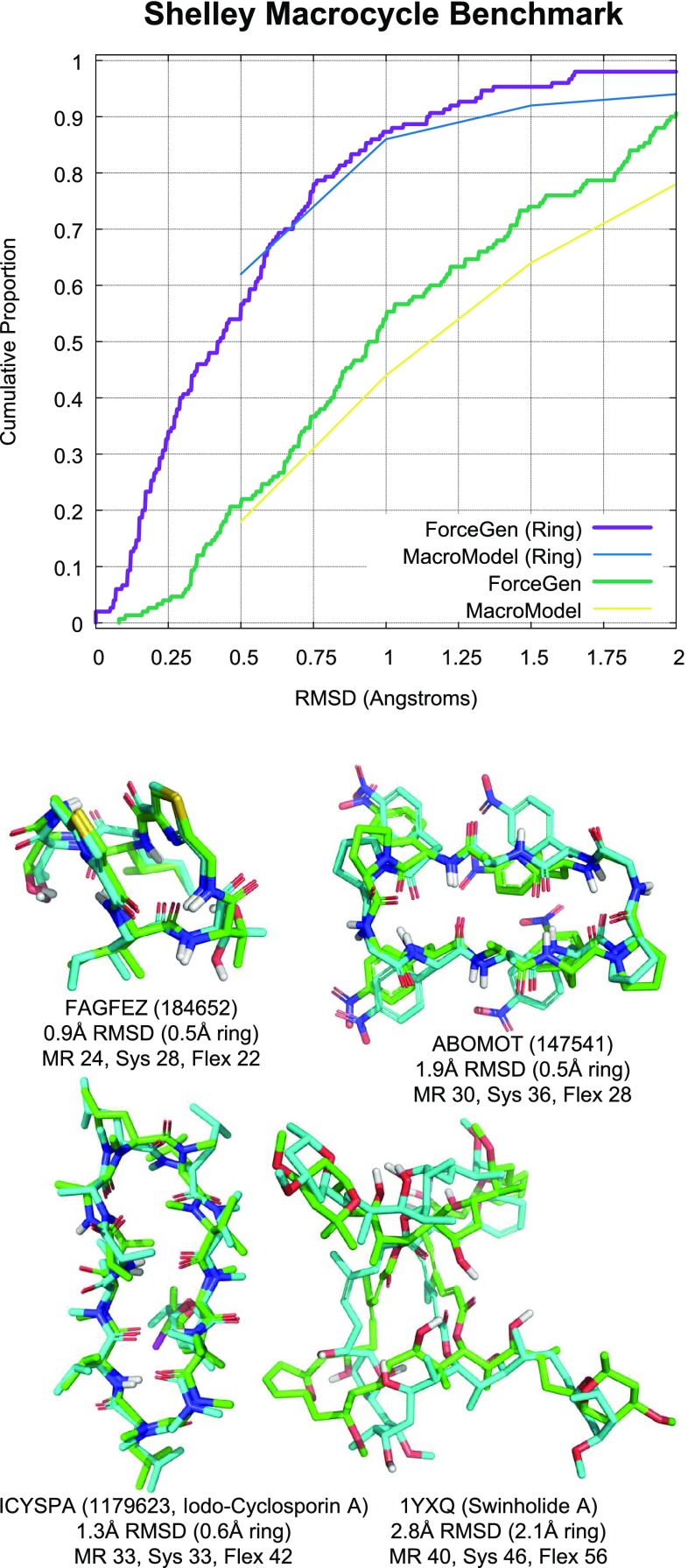
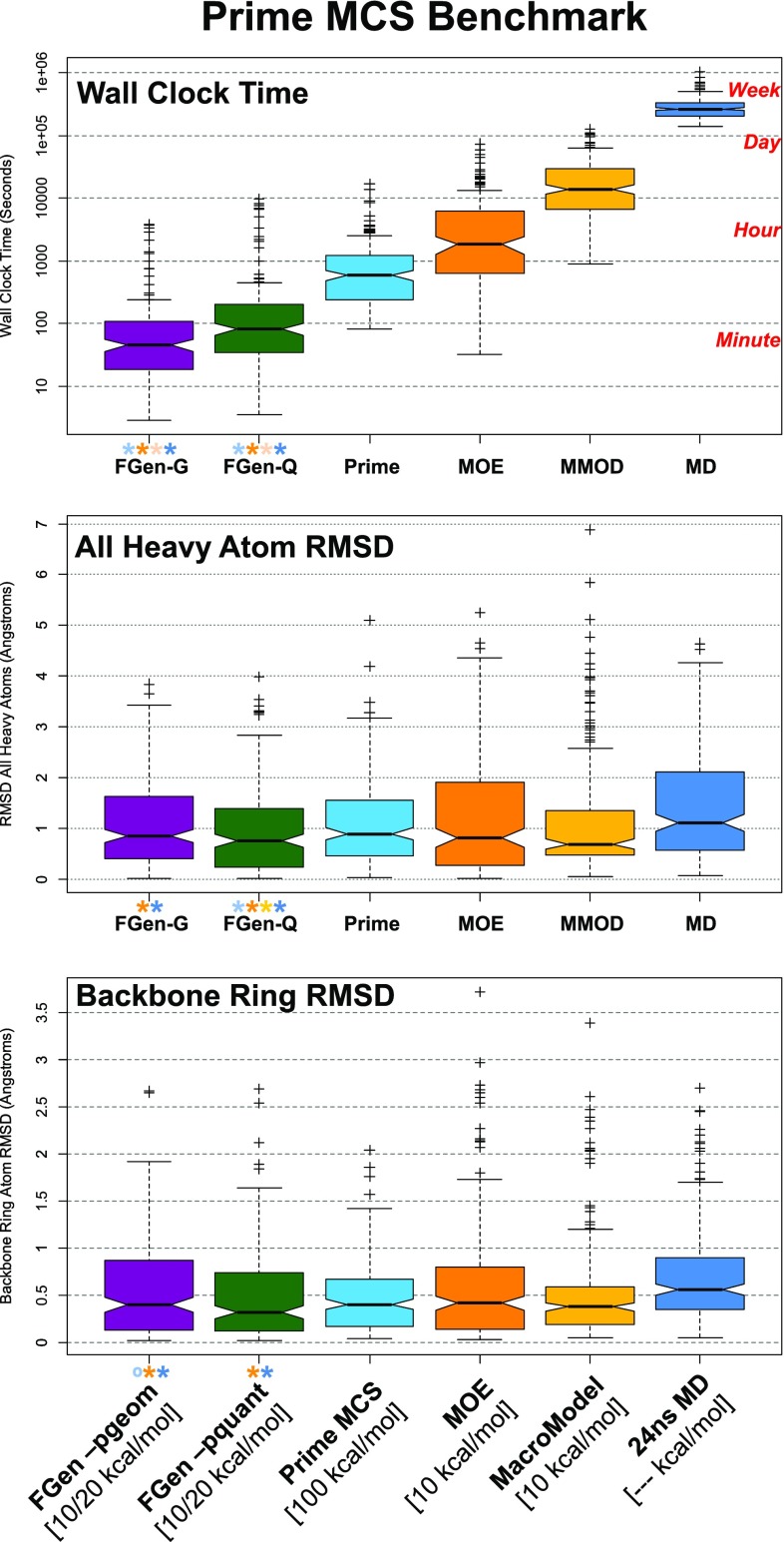
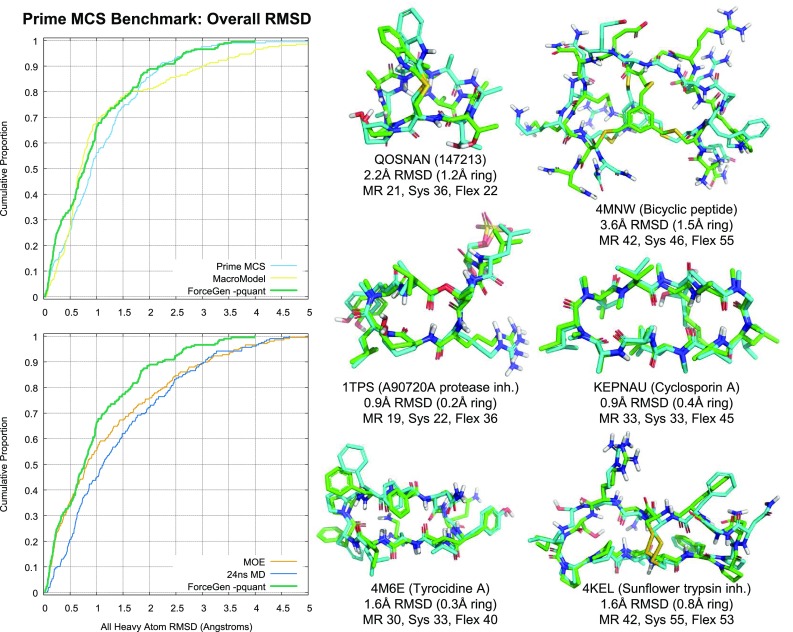
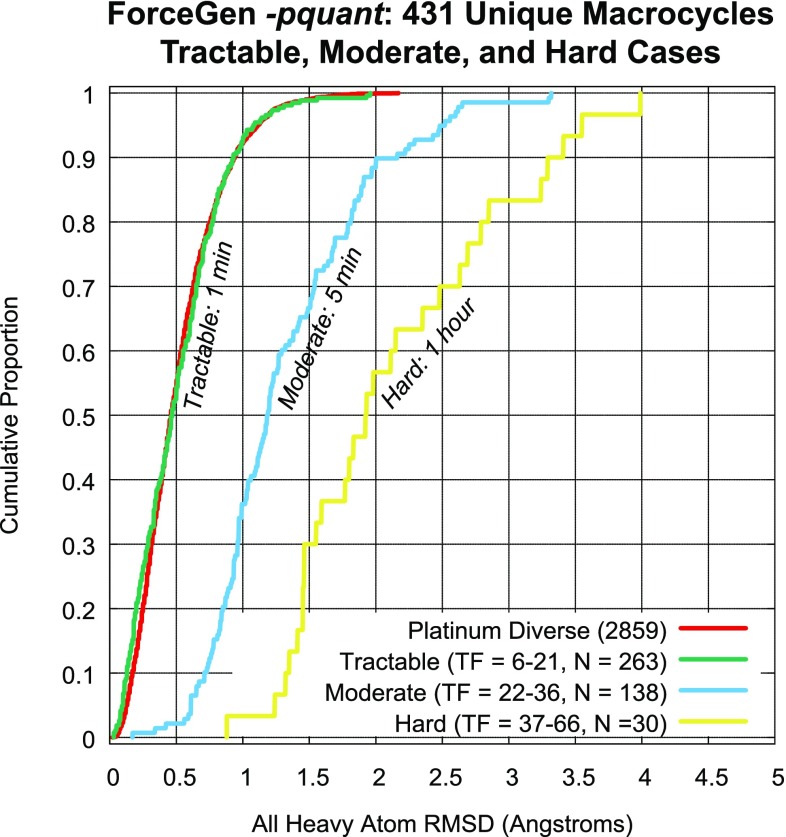
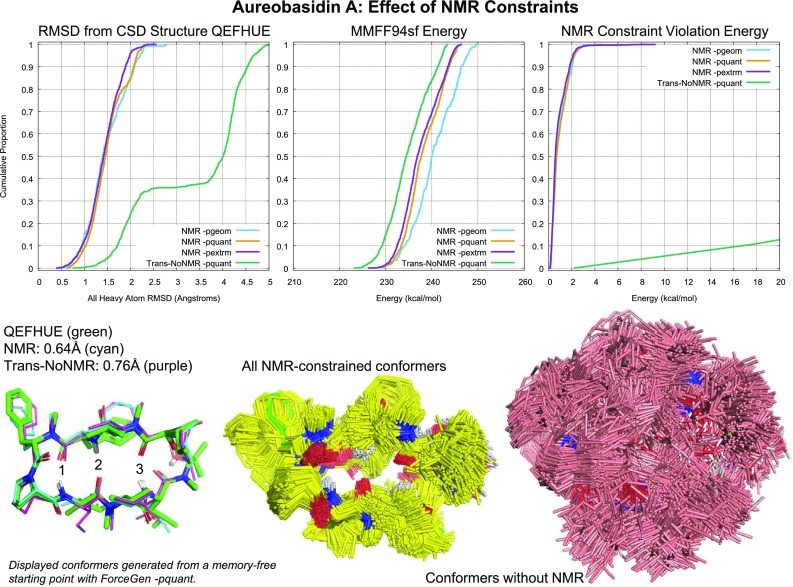
ForceGen is a template-free, non-stochastic approach for 2D to 3D structure generation and conformational elaboration for small molecules, including both non-macrocycles and macrocycles. For conformational search of non-macrocycles, ForceGen is both faster and more accurate than the best of all tested methods on a very large, independently curated benchmark of 2859 PDB ligands. In this study, the primary results are on macrocycles, including results for 431 unique examples from four separate benchmarks. These include complex peptide and peptide-like cases that can form networks of internal hydrogen bonds. By making use of new physical movements ("flips" of near-linear sub-cycles and explicit formation of hydrogen bonds), ForceGen exhibited statistically significantly better performance for overall RMS deviation from experimental coordinates than all other approaches. The algorithmic approach offers natural parallelization across multiple computing-cores. On a modest multi-core workstation, for all but the most complex macrocycles, median wall-clock times were generally under a minute in fast search mode and under 2 min using thorough search. On the most complex cases (roughly cyclic decapeptides and larger) explicit exploration of likely hydrogen bonding networks yielded marked improvements, but with calculation times increasing to several minutes and in some cases to roughly an hour for fast search. In complex cases, utilization of NMR data to constrain conformational search produces accurate conformational ensembles representative of solution state macrocycle behavior. On macrocycles of typical complexity (up to 21 rotatable macrocyclic and exocyclic bonds), design-focused macrocycle optimization can be practically supported by computational chemistry at interactive time-scales, with conformational ensemble accuracy equaling what is seen with non-macrocyclic ligands. For more complex macrocycles, inclusion of sparse biophysical data is a helpful adjunct to computation.
ForceGen 是一种无模板、非随机的方法,用于小分子的 2D 到 3D 结构生成和构象细化,包括非大环和大环。对于非大环的构象搜索,ForceGen 在一个非常大的、独立编纂的 2859 个 PDB 配体基准测试中,比所有测试方法都更快、更准确。在这项研究中,主要结果是关于大环的,包括来自四个独立基准的 431 个独特示例的结果。这些包括可以形成内部氢键网络的复杂肽和类似肽的情况。通过利用新的物理运动(近线性子环的“翻转”和氢键的显式形成),ForceGen 在与实验坐标的整体 RMS 偏差方面表现出明显优于所有其他方法的统计学显著更好的性能。该算法方法提供了跨多个计算核心的自然并行化。在一个适度的多核工作站上,对于除了最复杂的大环之外的所有大环,快速搜索模式下的中位数墙钟时间通常在一分钟以内,全面搜索时在两分钟以内。对于最复杂的情况(大致是环状十肽及更大的),对可能的氢键网络的显式探索产生了显著的改进,但计算时间增加到几分钟,在某些情况下,快速搜索的计算时间增加到大约一个小时。在复杂情况下,利用 NMR 数据来约束构象搜索可以生成准确的构象集合,代表溶液状态大环的行为。对于典型复杂度的大环(最多 21 个可旋转的大环和环外键),以设计为重点的大环优化可以在交互式时间尺度上得到计算化学的实际支持,构象集合的准确性与非大环配体相当。对于更复杂的大环,稀疏生物物理数据的包含是计算的有益辅助。