Faculty of Computer Science, National Research University Higher School of Economics, 125319, Moscow, 3 Kochnovsky Proezd, Russia.
BMC Cancer. 2019 May 10;19(1):434. doi: 10.1186/s12885-019-5653-x.
Chromosomal rearrangements are the typical phenomena in cancer genomes causing gene disruptions and fusions, corruption of regulatory elements, damage to chromosome integrity. Among the factors contributing to genomic instability are non-B DNA structures with stem-loops and quadruplexes being the most prevalent. We aimed at investigating the impact of specifically these two classes of non-B DNA structures on cancer breakpoint hotspots using machine learning approach.
We developed procedure for machine learning model building and evaluation as the considered data are extremely imbalanced and it was required to get a reliable estimate of the prediction power. We built logistic regression models predicting cancer breakpoint hotspots based on the densities of stem-loops and quadruplexes, jointly and separately. We also tested Random Forest models varying different resampling schemes (leave-one-out cross validation, train-test split, 3-fold cross-validation) and class balancing techniques (oversampling, stratification, synthetic minority oversampling).
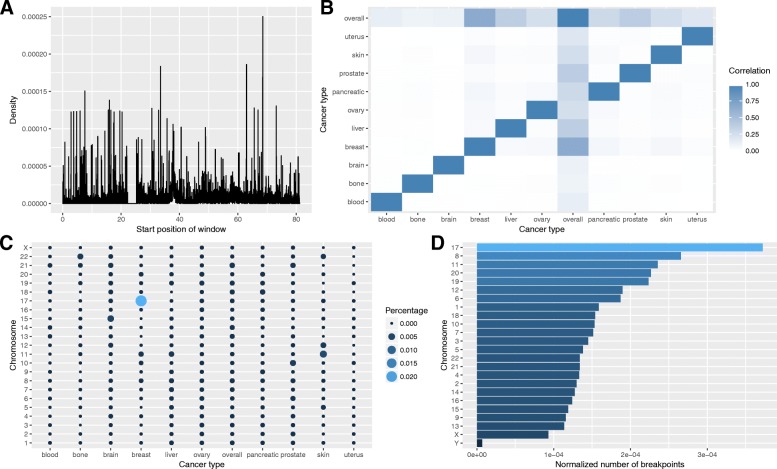
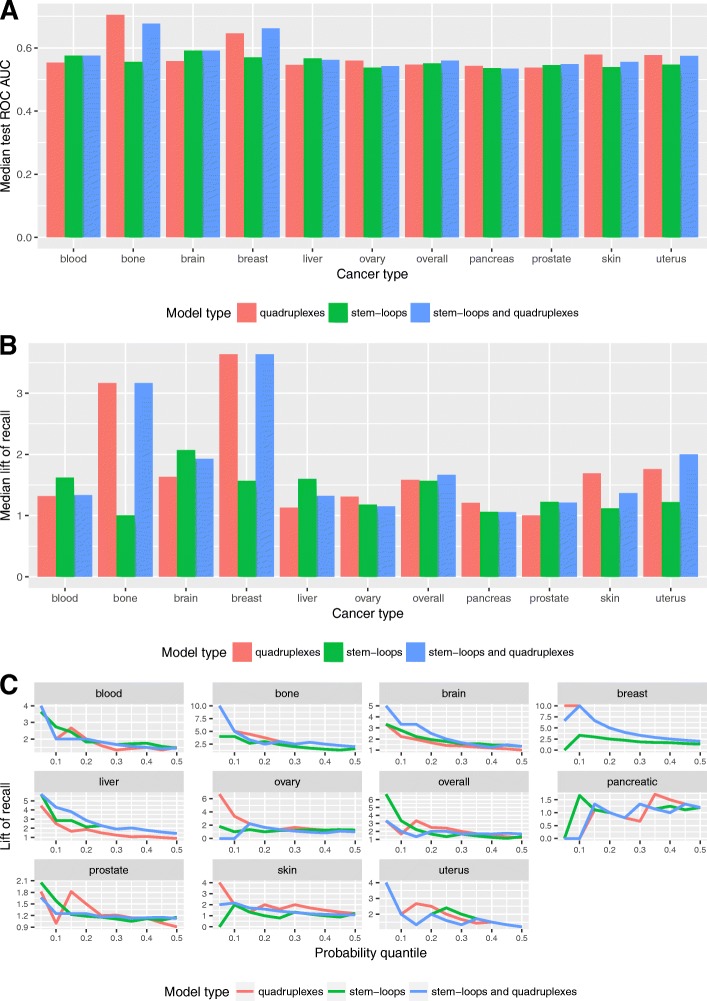
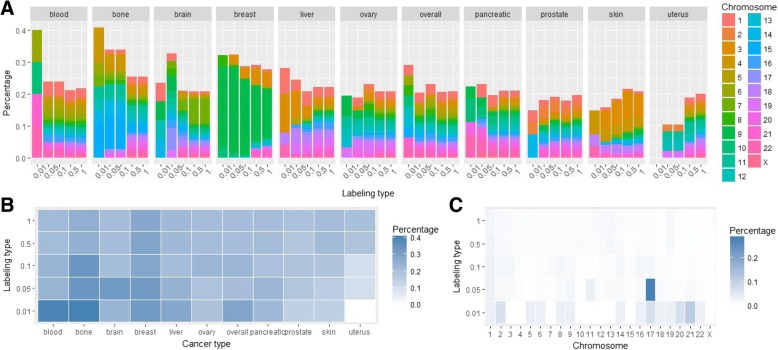
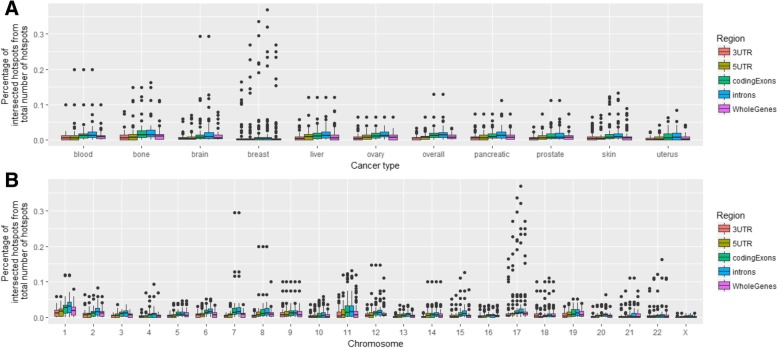
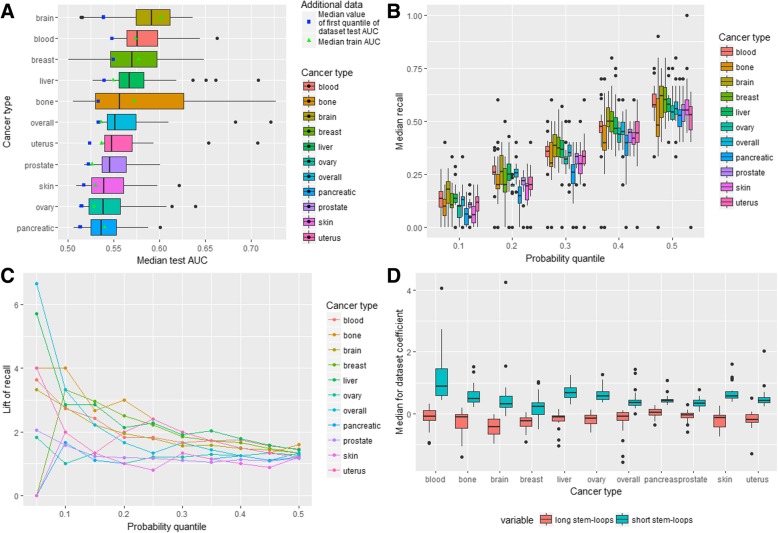
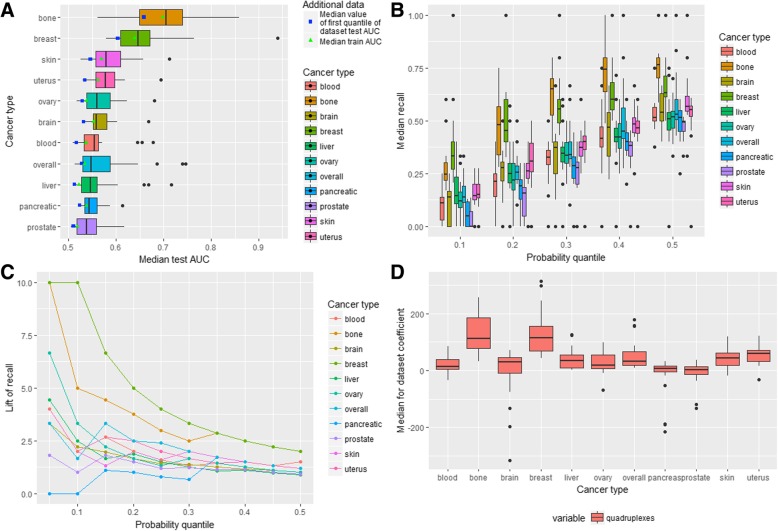
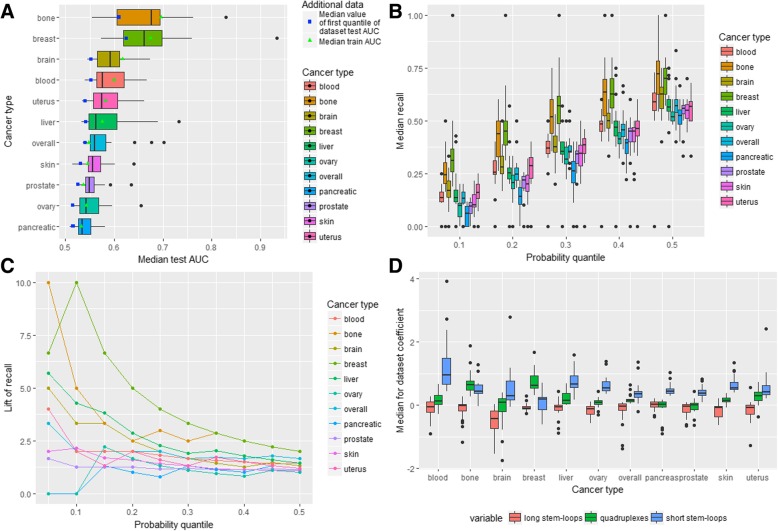
We performed analysis of 487,425 breakpoints from 2234 samples covering 10 cancer types available from the International Cancer Genome Consortium. We showed that distribution of breakpoint hotspots in different types of cancer are not correlated, confirming the heterogeneous nature of cancer. It appeared that stem-loop-based model best explains the blood, brain, liver, and prostate cancer breakpoint hotspot profiles while quadruplex-based model has higher performance for the bone, breast, ovary, pancreatic, and skin cancer. For the overall cancer profile and uterus cancer the joint model shows the highest performance. For particular datasets the constructed models reach high predictive power using just one predictor, and in the majority of the cases, the model built on both predictors does not increase the model performance.
Despite the heterogeneity in breakpoint hotspots' distribution across different cancer types, our results demonstrate an association between cancer breakpoint hotspots and stem-loops and quadruplexes. Approximately for half of the cancer types stem-loops are the most influential factors while for the others these are quadruplexes. This fact reflects the differences in regulatory potential of stem-loops and quadruplexes at the tissue-specific level, which yet to be discovered at the genome-wide scale. The performed analysis demonstrates that influence of stem-loops and quadruplexes on breakpoint hotspots formation is tissue-specific.
染色体重排是癌症基因组中的典型现象,导致基因断裂和融合,调控元件失活,染色体完整性受损。导致基因组不稳定性的因素包括具有茎环和四链体的非 B 型 DNA 结构,其中最常见的是茎环和四链体。我们旨在使用机器学习方法研究这两类非 B 型 DNA 结构对癌症断裂点热点的影响。
我们开发了机器学习模型构建和评估的程序,因为所考虑的数据极不平衡,需要可靠估计预测能力。我们构建了基于茎环和四链体密度的预测癌症断裂点热点的逻辑回归模型,分别和联合进行预测。我们还测试了随机森林模型,改变了不同的重采样方案(留一交叉验证、训练-测试分割、3 倍交叉验证)和类别平衡技术(过采样、分层、合成少数过采样)。
我们分析了来自国际癌症基因组联盟的 10 种癌症类型的 2234 个样本中 487425 个断裂点。我们表明,不同类型癌症中断裂点热点的分布没有相关性,证实了癌症的异质性。似乎基于茎环的模型能够最好地解释血液、大脑、肝脏和前列腺癌的断裂点热点分布,而基于四链体的模型在骨骼、乳腺、卵巢、胰腺和皮肤癌方面具有更高的性能。对于整体癌症图谱和子宫癌,联合模型显示出最高的性能。对于特定的数据集,构建的模型仅使用一个预测器就可以达到很高的预测能力,并且在大多数情况下,使用两个预测器构建的模型不会提高模型性能。
尽管不同癌症类型的断裂点热点分布存在异质性,但我们的结果表明癌症断裂点热点与茎环和四链体之间存在关联。对于大约一半的癌症类型,茎环是最具影响力的因素,而对于其他类型,这些是四链体。这一事实反映了茎环和四链体在组织特异性水平上的调节潜力的差异,这一差异尚未在全基因组范围内发现。所进行的分析表明,茎环和四链体对断裂点热点形成的影响是组织特异性的。