Häckl Sebastian, Koch Armin, Lasch Florian
Institute of Biostatistics, Hannover Medical School, Hannover, Germany.
Pharm Stat. 2019 Nov;18(6):636-644. doi: 10.1002/pst.1964. Epub 2019 Jul 3.
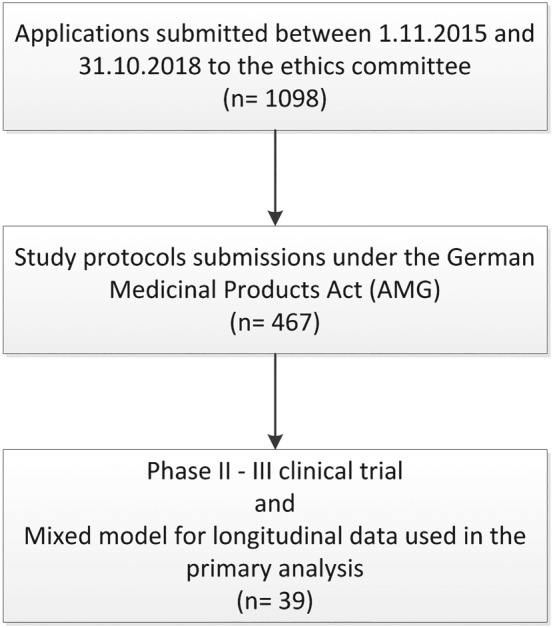
In confirmatory clinical trials, the prespecification of the primary analysis model is a universally accepted scientific principle to allow strict control of the type I error. Consequently, both the ICH E9 guideline and the European Medicines Agency (EMA) guideline on missing data in confirmatory clinical trials require that the primary analysis model is defined unambiguously. This requirement applies to mixed models for longitudinal data handling missing data implicitly. To evaluate the compliance with the EMA guideline, we evaluated the model specifications in those clinical study protocols from development phases II and III submitted between 2015 and 2018 to the Ethics Committee at Hannover Medical School under the German Medicinal Products Act, which planned to use a mixed model for longitudinal data in the confirmatory testing strategy. Overall, 39 trials from different types of sponsors and a wide range of therapeutic areas were evaluated. While nearly all protocols specify the fixed and random effects of the analysis model (95%), only 77% give the structure of the covariance matrix used for modeling the repeated measurements. Moreover, the testing method (36%), the estimation method (28%), the computation method (3%), and the fallback strategy (18%) are given by less than half the study protocols. Subgroup analyses indicate that these findings are universal and not specific to clinical trial phases or size of company. Altogether, our results show that guideline compliance is to various degrees poor and consequently, strict type I error rate control at the intended level is not guaranteed.
在确证性临床试验中,预先设定主要分析模型是一项被广泛接受的科学原则,以严格控制I类错误。因此,国际人用药品注册技术协调会(ICH)E9指南以及欧洲药品管理局(EMA)关于确证性临床试验中缺失数据的指南都要求明确界定主要分析模型。这一要求隐含地适用于处理缺失数据的纵向数据混合模型。为评估对EMA指南的遵循情况,我们对2015年至2018年间根据德国药品法提交给汉诺威医学院伦理委员会的II期和III期开发阶段的临床研究方案中的模型规范进行了评估,这些方案计划在确证性测试策略中使用纵向数据混合模型。总体而言,对来自不同类型申办方和广泛治疗领域的39项试验进行了评估。虽然几乎所有方案都明确了分析模型的固定效应和随机效应(95%),但只有77%给出了用于重复测量建模的协方差矩阵结构。此外,不到一半的研究方案给出了检验方法(36%)、估计方法(28%)、计算方法(3%)和后备策略(18%)。亚组分析表明,这些发现具有普遍性,并非特定于临床试验阶段或公司规模。总之,我们的结果表明,对指南的遵循程度在不同程度上较差,因此,无法保证将I类错误率严格控制在预期水平。