Department of Computer Science, NMT Computer Science and Engineering, Socorro, NM 87801, USA.
Department of Medicine, University of California San Diego, San Diego, CA 92093, USA.
Nutrients. 2019 Jul 22;11(7):1681. doi: 10.3390/nu11071681.
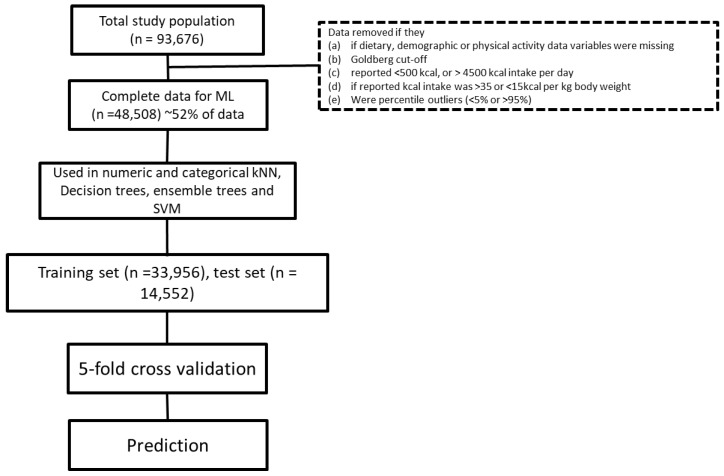
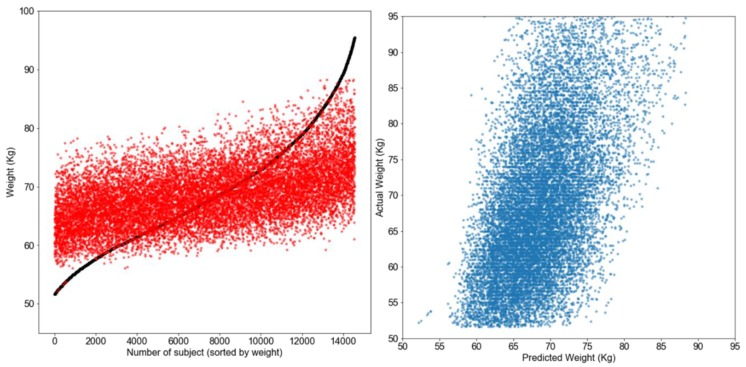
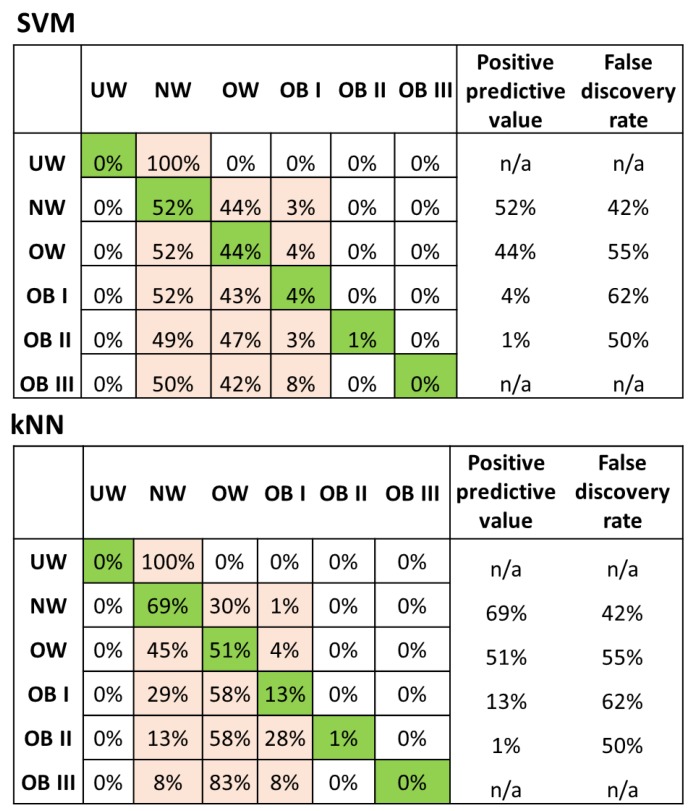
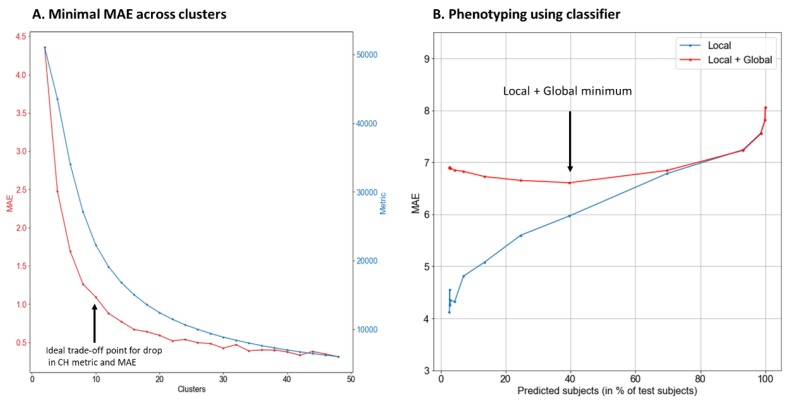
Nutritional phenotyping can help achieve personalized nutrition, and machine learning tools may offer novel means to achieve phenotyping. The primary aim of this study was to use energy balance components, namely input (dietary energy intake and macronutrient composition) and output (physical activity) to predict energy stores (body weight) as a way to evaluate their ability to identify potential phenotypes based on these parameters. From the Women's Health Initiative Observational Study (WHI OS), carbohydrates, proteins, fats, fibers, sugars, and physical activity variables, namely energy expended from mild, moderate, and vigorous intensity activity, were used to predict current body weight (both as body weight in kilograms and as a body mass index (BMI) category). Several machine learning tools were used for this prediction. Finally, cluster analysis was used to identify putative phenotypes. For the numerical predictions, the support vector machine (SVM), neural network, and k-nearest neighbor (kNN) algorithms performed modestly, with mean approximate errors (MAEs) of 6.70 kg, 6.98 kg, and 6.90 kg, respectively. For categorical prediction, SVM performed the best (54.5% accuracy), followed closely by the bagged tree ensemble and kNN algorithms. K-means cluster analysis improved prediction using numerical data, identified 10 clusters suggestive of phenotypes, with a minimum MAE of ~1.1 kg. A classifier was used to phenotype subjects into the identified clusters, with MAEs <5 kg for 15% of the test set (n = ~2000). This study highlights the challenges, limitations, and successes in using machine learning tools on self-reported data to identify determinants of energy balance.
营养表型分析有助于实现个性化营养,而机器学习工具可能为实现表型分析提供新的手段。本研究的主要目的是使用能量平衡成分(即输入[饮食能量摄入和宏量营养素组成]和输出[体力活动])来预测能量储存(体重),以此评估这些参数识别潜在表型的能力。本研究使用来自妇女健康倡议观察性研究(WHI OS)的数据,碳水化合物、蛋白质、脂肪、纤维、糖和体力活动变量,即轻、中、高强度活动所消耗的能量,来预测当前体重(体重以千克为单位和以身体质量指数(BMI)类别表示)。使用了几种机器学习工具进行预测。最后,使用聚类分析来识别潜在表型。对于数值预测,支持向量机(SVM)、神经网络和 k-最近邻(kNN)算法的表现较为一般,平均近似误差(MAE)分别为 6.70 千克、6.98 千克和 6.90 千克。对于分类预测,SVM 的表现最好(准确率为 54.5%),紧随其后的是袋装树集成和 kNN 算法。K-均值聚类分析使用数值数据提高了预测能力,确定了 10 个可能存在表型的聚类,最小 MAE 约为 1.1 千克。使用分类器将研究对象分为鉴定出的聚类,对于测试集(n=~2000)的 15%,MAE<5 千克。本研究强调了在使用机器学习工具对自我报告数据进行分析以识别能量平衡决定因素时所面临的挑战、限制和成功。