Computational Biology Unit, Department of Informatics, University of Bergen, P.O. Box 7803, N-5020 Bergen, Norway.
Integrated Research Institute (IRI) for the Life Sciences and Department of Biology, Humboldt-Universität zu Berlin, Unter den Linden 6, 10099 Berlin, Germany.
Nucleic Acids Res. 2019 Sep 5;47(15):7781-7797. doi: 10.1093/nar/gkz617.
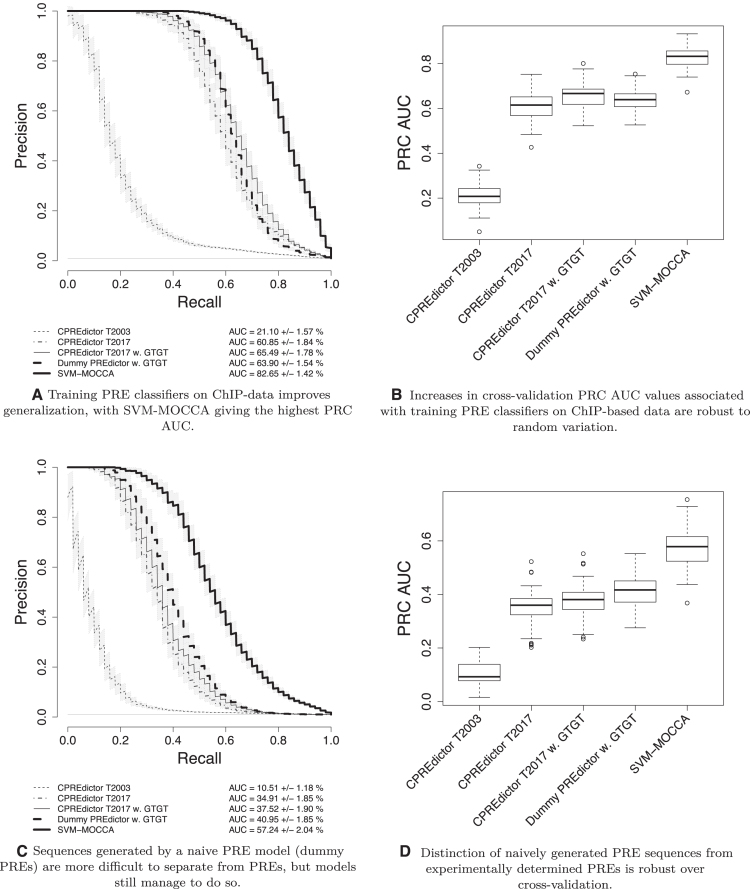
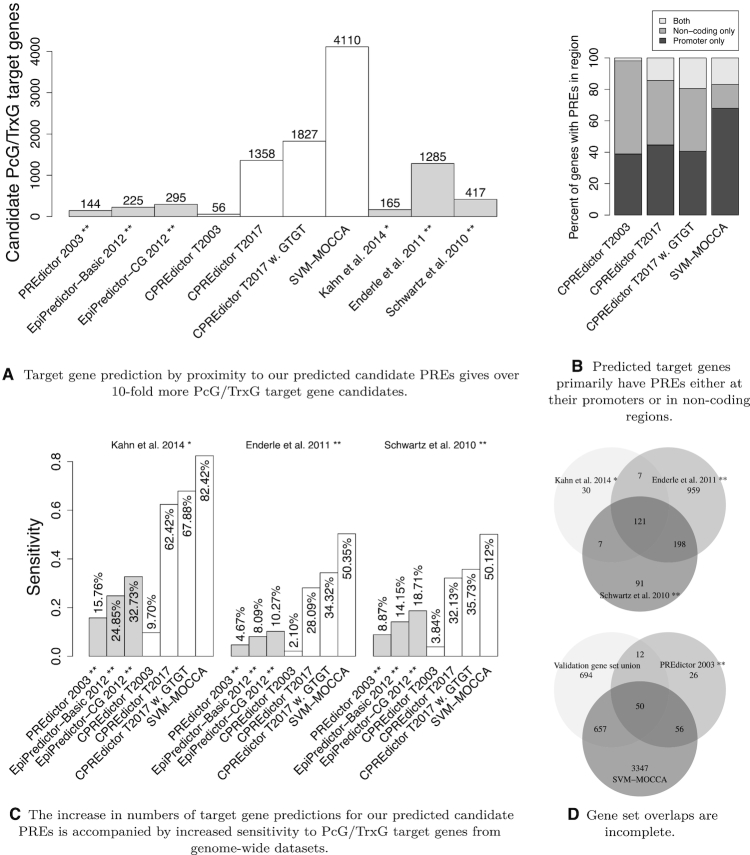
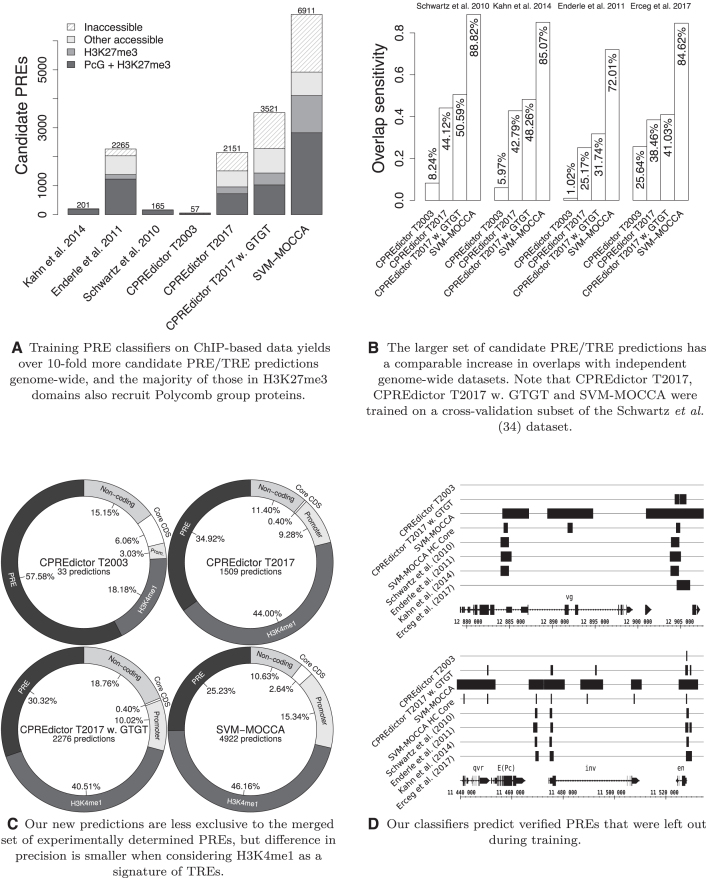
Polycomb Response Elements (PREs) are cis-regulatory DNA elements that maintain gene transcription states through DNA replication and mitosis. PREs have little sequence similarity, but are enriched in a number of sequence motifs. Previous methods for modelling Drosophila melanogaster PRE sequences (PREdictor and EpiPredictor) have used a set of 7 motifs and a training set of 12 PREs and 16-23 non-PREs. Advances in experimental methods for mapping chromatin binding factors and modifications has led to the publication of several genome-wide sets of Polycomb targets. In addition to the seven motifs previously used, PREs are enriched in the GTGT motif, recently associated with the sequence-specific DNA binding protein Combgap. We investigated whether models trained on genome-wide Polycomb sites generalize to independent PREs when trained with control sequences generated by naive PRE models and including the GTGT motif. We also developed a new PRE predictor: SVM-MOCCA. Training PRE predictors with genome-wide experimental data improves generalization to independent data, and SVM-MOCCA predicts the majority of PREs in three independent experimental sets. We present 2908 candidate PREs enriched in sequence and chromatin signatures. 2412 of these are also enriched in H3K4me1, a mark of Trithorax activated chromatin, suggesting that PREs/TREs have a common sequence code.
多梳抑制元件 (PREs) 是顺式调控 DNA 元件,通过 DNA 复制和有丝分裂维持基因转录状态。PREs 序列相似性较小,但富含许多序列基序。以前用于模拟黑腹果蝇 PRE 序列的方法 (PREdictor 和 EpiPredictor) 使用了一组 7 个基序和 12 个 PRE 和 16-23 个非 PRE 的训练集。用于绘制染色质结合因子和修饰的实验方法的进步导致了几个全基因组 Polycomb 靶标的发表。除了以前使用的七个基序外,PREs 富含 GTGT 基序,最近与序列特异性 DNA 结合蛋白 Combgap 相关。我们研究了当使用天真 PRE 模型生成的对照序列和包括 GTGT 基序进行训练时,基于全基因组 Polycomb 位点训练的模型是否可以推广到独立的 PRE。我们还开发了一种新的 PRE 预测器:SVM-MOCCA。使用全基因组实验数据训练 PRE 预测器可以提高对独立数据的泛化能力,并且 SVM-MOCCA 可以预测三个独立实验集中的大多数 PRE。我们提出了 2908 个富含序列和染色质特征的候选 PRE。其中 2412 个也富含 H3K4me1,这是一种转录激活染色质的标记,表明 PREs/TREs 具有共同的序列代码。