Eli and Edythe L. Broad Institute of Massachusetts Institute of Technology and Harvard University, Cambridge, MA 02142, USA; The University of Texas Southwestern Medical School, Dallas, TX 75390, USA.
Department of Genetics, Lineberger Comprehensive Cancer Center, the University of North Carolin at Chapel Hill, Chapel Hill, NC 27599, USA.
Cell Syst. 2019 Jul 24;9(1):24-34.e10. doi: 10.1016/j.cels.2019.06.006.
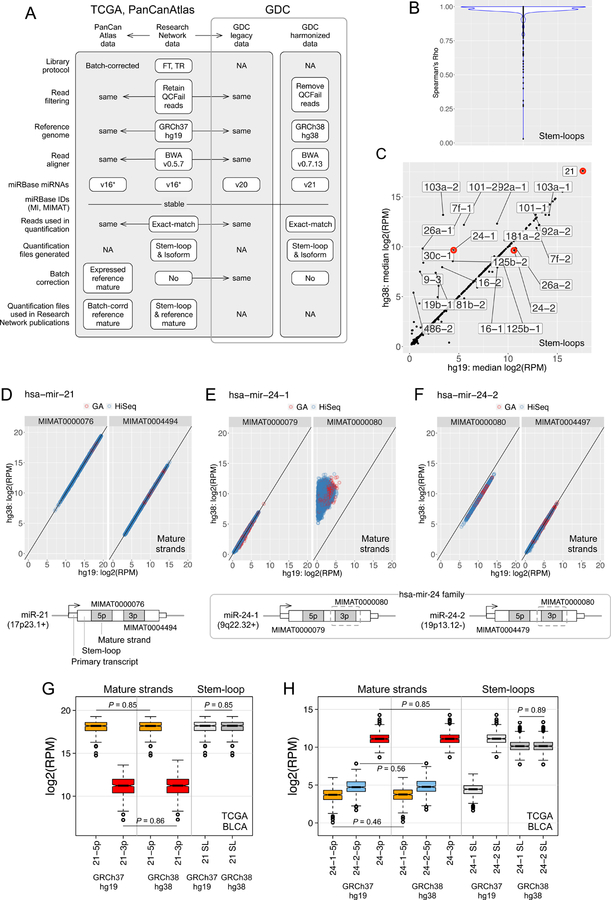
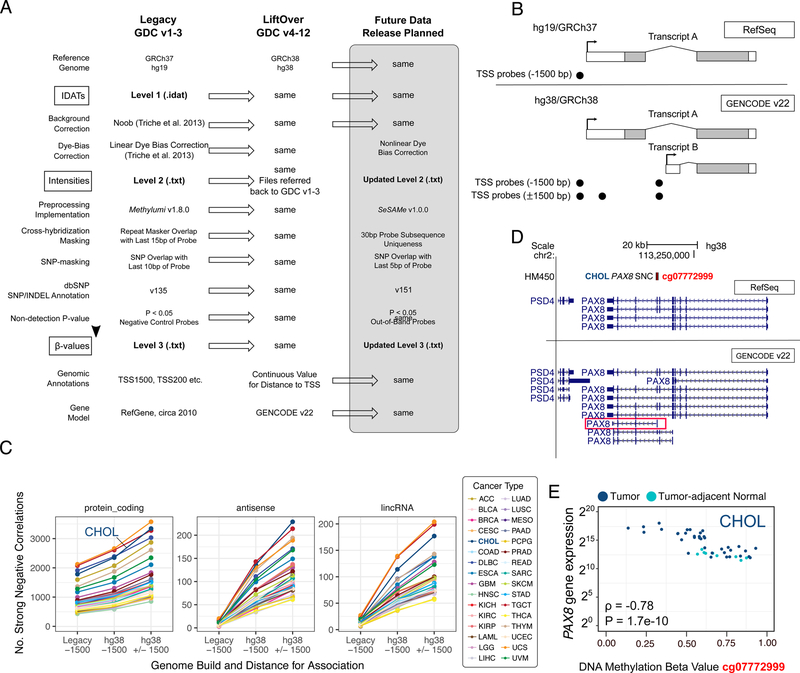
We present a systematic analysis of the effects of synchronizing a large-scale, deeply characterized, multi-omic dataset to the current human reference genome, using updated software, pipelines, and annotations. For each of 5 molecular data platforms in The Cancer Genome Atlas (TCGA)-mRNA and miRNA expression, single nucleotide variants, DNA methylation and copy number alterations-comprehensive sample, gene, and probe-level studies were performed, towards quantifying the degree of similarity between the 'legacy' GRCh37 (hg19) TCGA data and its GRCh38 (hg38) version as 'harmonized' by the Genomic Data Commons. We offer gene lists to elucidate differences that remained after controlling for confounders, and strategies to mitigate their impact on biological interpretation. Our results demonstrate that the hg19 and hg38 TCGA datasets are very highly concordant, promote informed use of either legacy or harmonized omics data, and provide a rubric that encourages similar comparisons as new data emerge and reference data evolve.
我们展示了一种系统的分析方法,该方法将大规模、深度特征化的多组学数据集同步到当前人类参考基因组,使用了更新的软件、管道和注释。对于癌症基因组图谱 (TCGA) 中的 5 种分子数据平台中的每一种 - mRNA 和 miRNA 表达、单核苷酸变体、DNA 甲基化和拷贝数改变 - 都进行了全面的样本、基因和探针水平研究,以量化“传统”GRCh37(hg19)TCGA 数据与其通过基因组数据共享资源“协调”的 GRCh38(hg38)版本之间的相似程度。我们提供了基因列表,以阐明在控制混杂因素后仍然存在的差异,并提供了减轻这些差异对生物学解释影响的策略。我们的结果表明,hg19 和 hg38 TCGA 数据集非常一致,促进了对传统或协调的组学数据的明智使用,并提供了一个准则,鼓励在新数据出现和参考数据演变时进行类似的比较。