Qi Xinpeng, Ogden Elizabeth L, Ehlenfeldt Mark K, Rowland Lisa J
USDA-ARS, BARC-West, Genetic Improvement of Fruits and Vegetables Laboratory, Beltsville, MD 20705, USA.
USDA-ARS, Genetic Improvement of Fruits and Vegetables Laboratory, at Rutgers University, P.E. Marucci Center for Blueberry and Cranberry Research and Extension, Chatsworth, NJ 08019, USA.
Data Brief. 2019 Aug 12;25:104390. doi: 10.1016/j.dib.2019.104390. eCollection 2019 Aug.
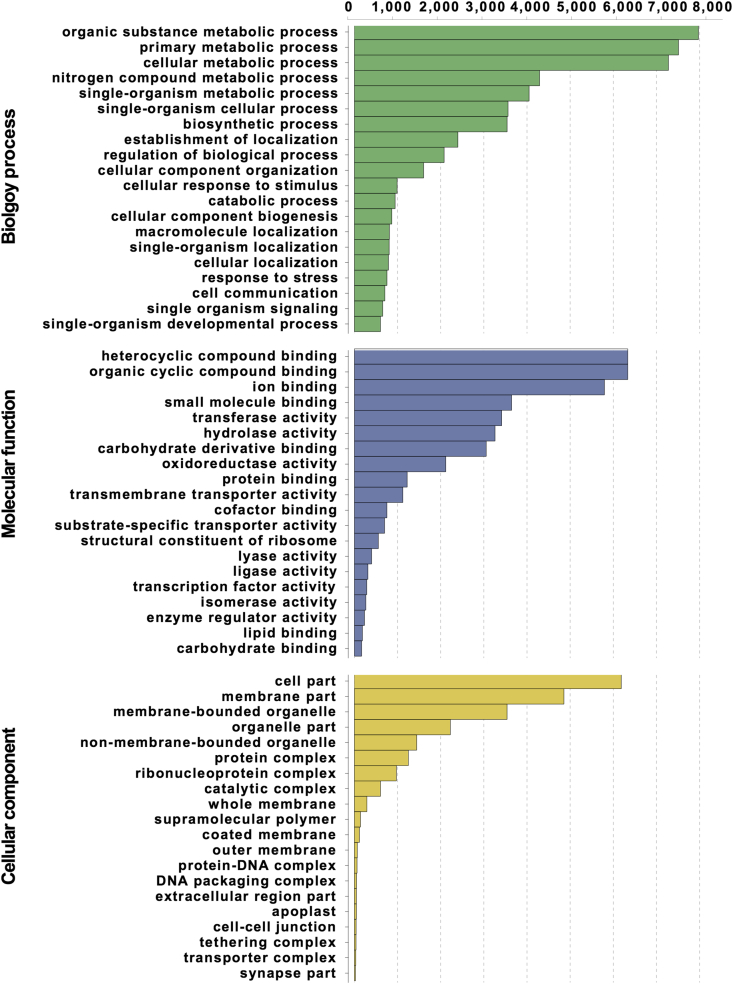
Blueberry is an economically important berry crop. Both production and consumption of blueberries have increased sharply worldwide in recent years at least partly due to their known health benefits. The development of improved genomic resources for blueberry, such as a well-assembled genome and transcriptome, could accelerate breeding through genomic-assisted approaches. To enrich available transcriptome data and identify genes potentially involved in fruit quality, RNA sequencing was performed on fruit tissue from two northern-adapted hybrid blueberry breeding populations. RNA-seq was carried out using the Illumina HiSeq 2500 platform. Because of the absence of a reference-grade genome for blueberry, a transcriptome was assembled from this RNA-seq data and other publicly available transcriptome data from blueberry downloaded from the National Center for Biotechnology Information (NCBI) Short Read Archive (SRA) using Trinity. After removing redundancy, this resulted in a dataset of 91,861 blueberry unigenes. This unigene dataset was functionally annotated using the NCBI-Nr protein database. All raw reads from the breeding populations were deposited in the NCBI SRA with accession numbers SRR6281886, SRR6281887, SRR6281888, and SRR6281889. The transcriptome assembly was deposited at NCBI Transcriptome Shotgun Assembly (TSA) database with accession number GGAB00000000. These data will provide real expression evidence for the blueberry genome gene prediction and gene functional annotation and a reference transcriptome for future gene expression studies involving blueberry fruit.
蓝莓是一种具有重要经济价值的浆果作物。近年来,全球蓝莓的产量和消费量均大幅增长,这至少部分归因于其已知的健康益处。开发改良的蓝莓基因组资源,如组装良好的基因组和转录组,可通过基因组辅助方法加速育种进程。为了丰富可用的转录组数据并鉴定可能参与果实品质形成的基因,对来自两个适应北方环境的杂交蓝莓育种群体的果实组织进行了RNA测序。RNA测序使用Illumina HiSeq 2500平台进行。由于缺乏蓝莓的参考基因组,利用Trinity从该RNA测序数据以及从美国国立生物技术信息中心(NCBI)短读存档(SRA)下载的其他公开可用的蓝莓转录组数据中组装了一个转录组。去除冗余后,得到了一个包含91,861个蓝莓单基因的数据集。该单基因数据集使用NCBI-Nr蛋白质数据库进行了功能注释。来自育种群体的所有原始读数已存入NCBI SRA,登录号为SRR6281886、SRR6281887、SRR6281888和SRR6281889。转录组组装已存入NCBI转录组鸟枪法组装(TSA)数据库,登录号为GGAB00000000。这些数据将为蓝莓基因组基因预测和基因功能注释提供真实的表达证据,并为未来涉及蓝莓果实的基因表达研究提供参考转录组。