Liu Bin, Chen Shengyu, Yan Ke, Weng Fan
School of Computer Science and Technology, Beijing Institute of Technology, Beijing, China.
Advanced Research Institute of Multidisciplinary Science, Beijing Institute of Technology, Beijing, China.
Front Genet. 2019 Sep 18;10:842. doi: 10.3389/fgene.2019.00842. eCollection 2019.
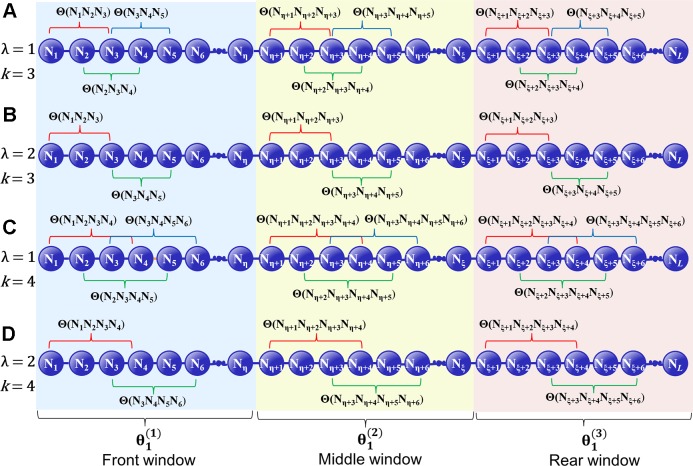
Identification of replication origins is playing a key role in understanding the mechanism of DNA replication. This task is of great significance in DNA sequence analysis. Because of its importance, some computational approaches have been introduced. Among these predictors, the iRO-3wPseKNC predictor is the first discriminative method that is able to correctly identify the entire replication origins. For further improving its predictive performance, we proposed the Pseudo k-tuple GC Composition (PsekGCC) approach to capture the "GC asymmetry bias" of yeast species by considering both the GC skew and the sequence order effects of -tuple GC Composition (-GCC) in this study. Based on PseKGCC, we proposed a new predictor called iRO-PsekGCC to identify the DNA replication origins. Rigorous jackknife test on two yeast species benchmark datasets (, ) indicated that iRO-PsekGCC outperformed iRO-3wPseKNC. It can be anticipated that iRO-PsekGCC will be a useful tool for DNA replication origin identification. The web-server for the iRO-PsekGCC predictor was established, and it can be accessed at http://bliulab.net/iRO-PsekGCC/.
复制起点的识别在理解DNA复制机制中起着关键作用。这项任务在DNA序列分析中具有重要意义。由于其重要性,已经引入了一些计算方法。在这些预测器中,iRO-3wPseKNC预测器是第一种能够正确识别整个复制起点的判别方法。为了进一步提高其预测性能,在本研究中,我们提出了伪k元组GC组成(PsekGCC)方法,通过同时考虑GC偏斜和k元组GC组成(-GCC)的序列顺序效应来捕获酵母物种的“GC不对称偏差”。基于PseKGCC,我们提出了一种名为iRO-PsekGCC的新预测器来识别DNA复制起点。对两个酵母物种基准数据集(,)进行的严格留一法测试表明,iRO-PsekGCC的性能优于iRO-3wPseKNC。可以预期,iRO-PsekGCC将成为识别DNA复制起点的有用工具。已建立了iRO-PsekGCC预测器的网络服务器,可通过http://bliulab.net/iRO-PsekGCC/访问。