College of Science, Beijing Forestry University, Beijing, P. R. China.
Data Science, Harrisburg University of Science and Technology, Harrisburg, PA, United States of America.
PLoS One. 2020 Feb 11;15(2):e0228645. doi: 10.1371/journal.pone.0228645. eCollection 2020.
As an essential component in reducing anthropogenic CO2 emissions to the atmosphere, tree planting is the key to keeping carbon dioxide emissions under control. In 1992, the United Nations agreed to take action at the Earth Summit to stabilize and reduce net zero global anthropogenic CO2 emissions. Tree planting was identified as an effective method to offset CO2 emissions. A high net photosynthetic rate (Pn) with fast-growing trees could efficiently fulfill the goal of CO2 emission reduction. Net photosynthetic rate model can provide refernece for plant's stability of photosynthesis productivity.
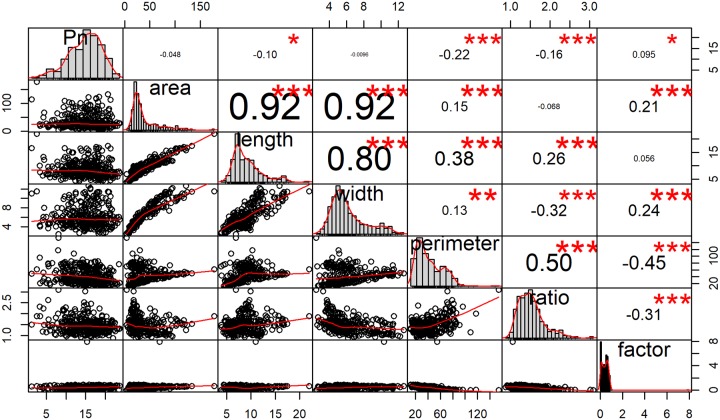
Using leaf phenotype data to predict the Pn can help effectively guide tree planting policies to offset CO2 release into the atmosphere. Tree planting has been proposed as one climate change solution. One of the most popular trees to plant are poplars. This study used a Populus simonii (P. simonii) dataset collected from 23 artificial forests in northern China. The samples represent almost the entire geographic distribution of P. simonii. The geographic locations of these P. simonii trees cover most of the major provinces of northern China. The northwestern point reaches (36°30'N, 98°09'E). The northeastern point reaches (40°91'N, 115°83'E). The southwestern point reaches (32°31'N, 108°90'E). The southeastern point reaches (34°39'N, 113°74'E). The collected data on leaf phenotypic traits are sparse, noisy, and highly correlated. The photosynthetic rate data are nonnormal and skewed. Many machine learning algorithms can produce reasonably accurate predictions despite these data issues. Influential outliers are removed to allow an accurate and precise prediction, and cluster analysis is implemented as part of a data exploratory analysis to investigate further details in the dataset. We select four regression methods, extreme gradient boosting (XGBoost), support vector machine (SVM), random forest (RF) and generalized additive model (GAM), which are suitable to use on the dataset given in this study. Cross-validation and regularization mechanisms are implemented in the XGBoost, SVM, RF, and GAM algorithms to ensure the validity of the outputs.
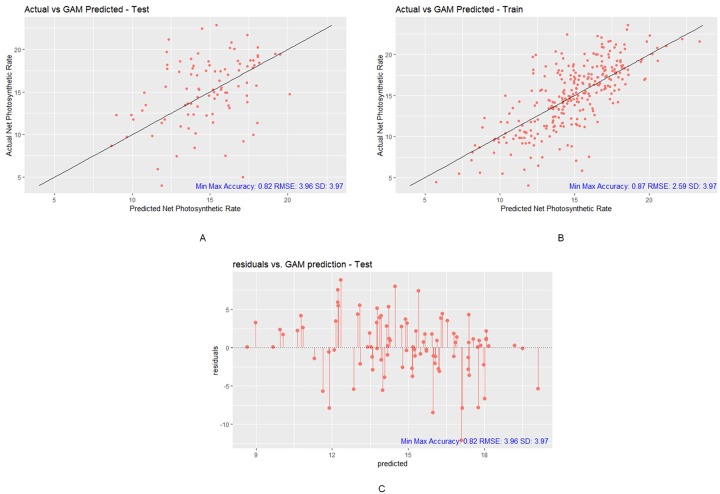
The best-performing approach is XGBoost, which generates a net photosynthetic rate prediction that has a 0.77 correlation with the actual rates. Moreover, the root mean square error (RMSE) is 2.57, which is approximately 35 percent smaller than the standard deviation of 3.97. The other metrics, i.e., the MAE, R2, and the min-max accuracy are 1.12, 0.60, and 0.93, respectively. This study demonstrates the ability of machine learning models to use noisy leaf phenotype data to predict the net photosynthetic rate with significant accuracy. Most net photosynthetic rate prediction studies are conducted on herbaceous plants. The net photosynthetic rate prediction of P. simonii, a kind of woody plant, illustrates significant guidance for plant science or environmental science regarding the predictive relationship between leaf phenotypic characteristics and the Pn for woody plants in northern China.
植树造林作为减少人为 CO2 排放到大气中的重要组成部分,是控制二氧化碳排放的关键。1992 年,联合国在地球峰会上同意采取行动,以稳定和减少全球人为 CO2 排放的净零排放。植树造林被确定为抵消 CO2 排放的有效方法。具有高净光合速率(Pn)和快速生长的树木可以有效地实现减排目标。净光合速率模型可以为植物光合作用生产力的稳定性提供参考。
使用叶表型数据预测 Pn 可以有效地指导植树造林政策,以抵消 CO2 向大气的释放。植树造林已被提出作为气候变化解决方案之一。最受欢迎的种植树木之一是杨树。本研究使用了来自中国北方 23 个人工林的 Populus simonii(P. simonii)数据集。这些样本代表了 P. simonii 的几乎整个地理分布。这些 P. simonii 树木的地理位置覆盖了中国北方的大部分主要省份。西北点到达(36°30'N,98°09'E)。东北点到达(40°91'N,115°83'E)。西南点到达(32°31'N,108°90'E)。东南点到达(34°39'N,113°74'E)。收集的叶表型性状数据稀疏、嘈杂且高度相关。光合速率数据是非正态和偏态的。尽管存在这些数据问题,但许多机器学习算法可以产生相当准确的预测。去除有影响力的异常值以实现准确和精确的预测,并实施聚类分析作为数据探索性分析的一部分,以进一步研究数据集的详细信息。我们选择了四种回归方法,即极端梯度提升(XGBoost)、支持向量机(SVM)、随机森林(RF)和广义加性模型(GAM),这些方法适用于本研究中提供的数据集。在 XGBoost、SVM、RF 和 GAM 算法中实现了交叉验证和正则化机制,以确保输出的有效性。
表现最佳的方法是 XGBoost,它生成的净光合速率预测与实际速率的相关性为 0.77。此外,均方根误差(RMSE)为 2.57,比 3.97 的标准偏差小约 35%。其他指标,即均方误差(MAE)、R2 和最小-最大准确度分别为 1.12、0.60 和 0.93。本研究表明,机器学习模型能够使用嘈杂的叶表型数据以显著的准确性预测净光合速率。大多数净光合速率预测研究都是在草本植物上进行的。P. simonii 的净光合速率预测,一种木本植物,为中国北方木本植物的叶表型特征与 Pn 之间的预测关系提供了重要的指导,无论是对植物科学还是环境科学而言。