Bonanno Etienne, Ebejer Jean-Paul
Department of Artificial Intelligence, University of Malta, Msida, Malta.
Centre for Molecular Medicine and Biobanking, University of Malta, Msida, Malta.
Front Pharmacol. 2020 Feb 19;10:1675. doi: 10.3389/fphar.2019.01675. eCollection 2019.
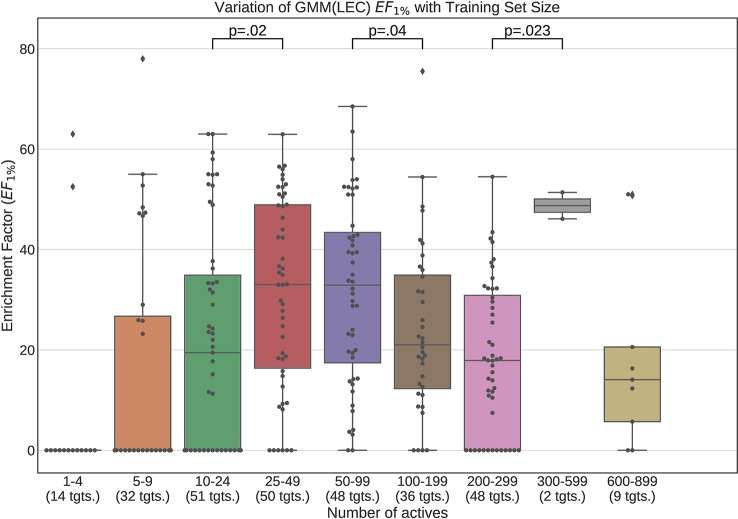
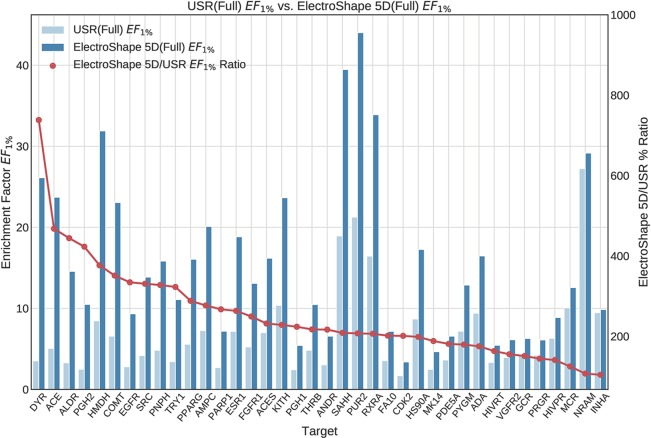
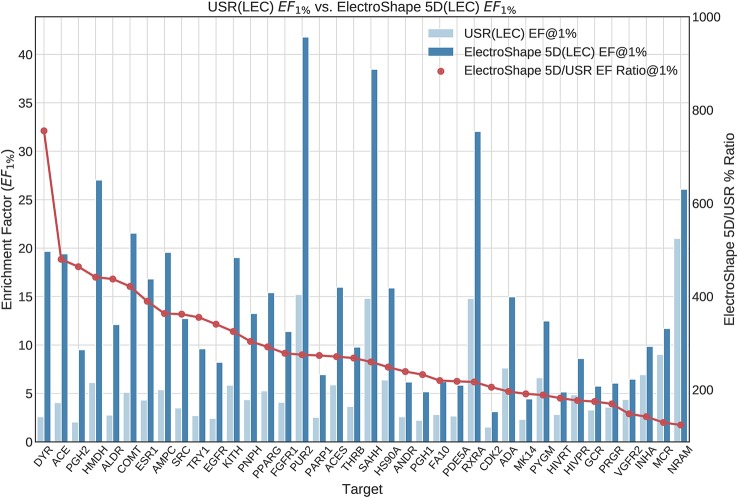
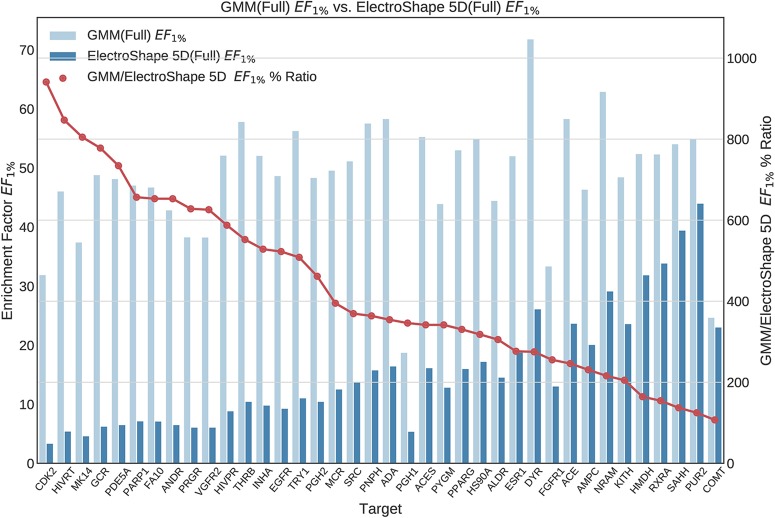
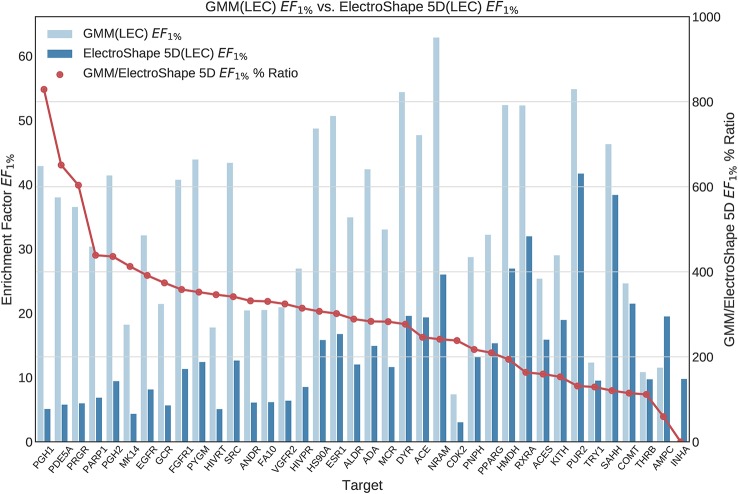
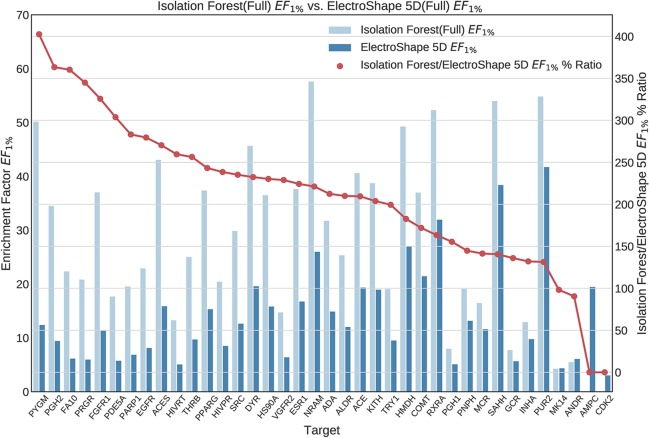
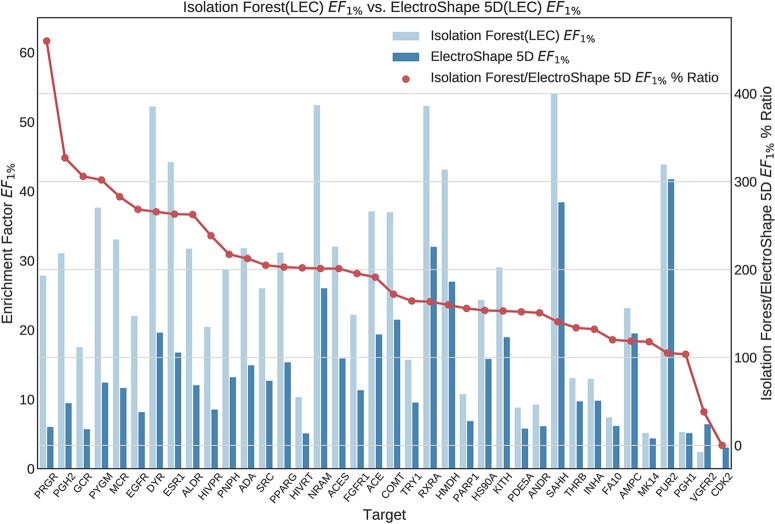
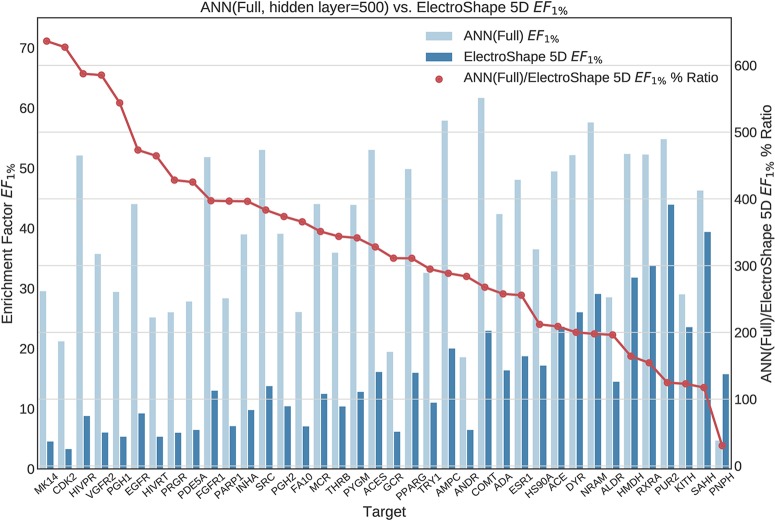
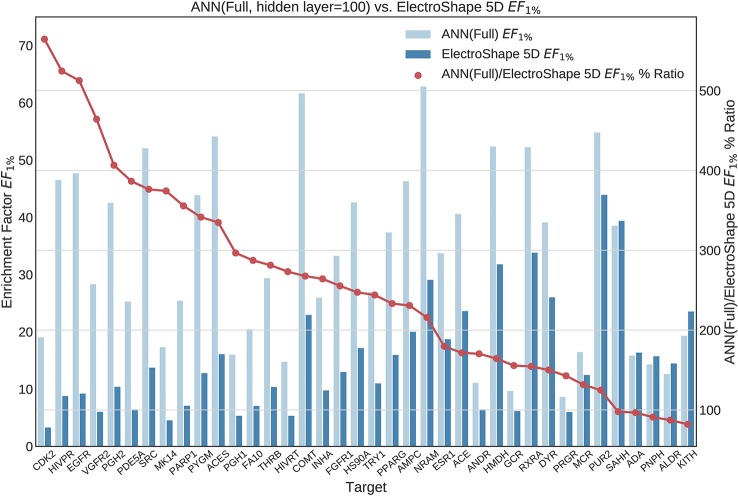
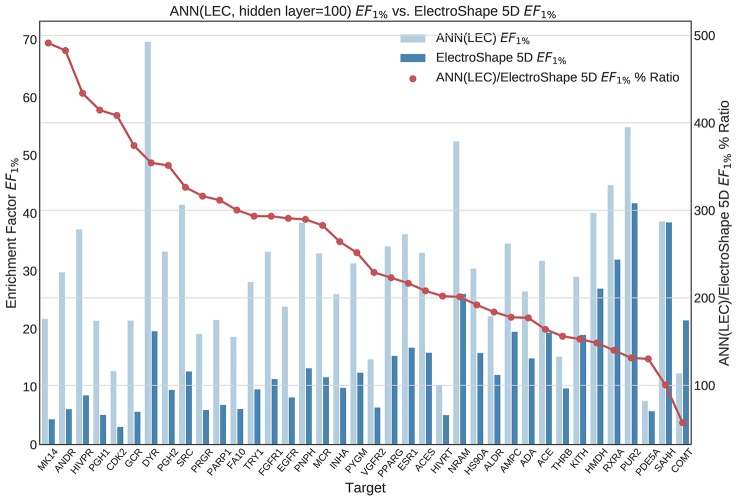
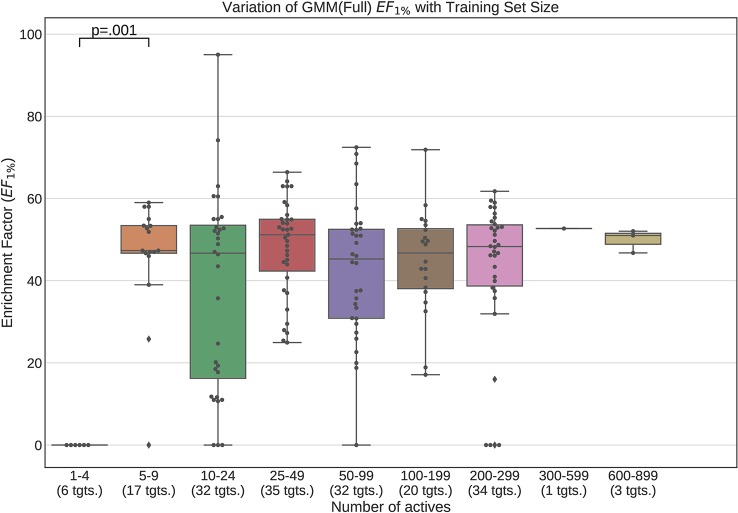
Ultrafast Shape Recognition (USR), along with its derivatives, are Ligand-Based Virtual Screening (LBVS) methods that condense 3-dimensional information about molecular shape, as well as other properties, into a small set of numeric descriptors. These can be used to efficiently compute a measure of similarity between pairs of molecules using a simple inverse Manhattan Distance metric. In this study we explore the use of suitable Machine Learning techniques that can be trained using USR descriptors, so as to improve the similarity detection of potential new leads. We use molecules from the Directory for Useful Decoys-Enhanced to construct machine learning models based on three different algorithms: Gaussian Mixture Models (GMMs), Isolation Forests and Artificial Neural Networks (ANNs). We train models based on full molecule conformer models, as well as the Lowest Energy Conformations (LECs) only. We also investigate the performance of our models when trained on smaller datasets so as to model virtual screening scenarios when only a small number of actives are known . Our results indicate significant performance gains over a state of the art USR-derived method, ElectroShape 5D, with GMMs obtaining a mean performance up to 430% better than that of ElectroShape 5D in terms of Enrichment Factor with a maximum improvement of up to 940%. Additionally, we demonstrate that our models are capable of maintaining their performance, in terms of enrichment factor, within 10% of the mean as the size of the training dataset is successively reduced. Furthermore, we also demonstrate that running times for retrospective screening using the machine learning models we selected are faster than standard USR, on average by a factor of 10, including the time required for training. Our results show that machine learning techniques can significantly improve the virtual screening performance and efficiency of the USR family of methods.
超快形状识别(USR)及其衍生方法是基于配体的虚拟筛选(LBVS)方法,可将有关分子形状以及其他性质的三维信息浓缩为一小组数值描述符。这些描述符可用于使用简单的逆曼哈顿距离度量有效地计算分子对之间的相似性度量。在本研究中,我们探索使用可通过USR描述符进行训练的合适机器学习技术,以提高对潜在新先导物的相似性检测。我们使用来自有用诱饵增强目录的分子,基于三种不同算法构建机器学习模型:高斯混合模型(GMM)、孤立森林和人工神经网络(ANN)。我们基于完整分子构象模型以及仅最低能量构象(LEC)来训练模型。我们还研究了在较小数据集上训练模型时的性能,以便在仅知道少量活性化合物的情况下对虚拟筛选场景进行建模。我们的结果表明,与一种先进的基于USR的方法ElectroShape 5D相比,性能有显著提升,GMM在富集因子方面的平均性能比ElectroShape 5D高出430%,最大提升高达940%。此外,我们证明,随着训练数据集大小的相继减少,我们的模型在富集因子方面能够将其性能保持在均值的10%以内。此外,我们还证明,使用我们选择的机器学习模型进行回顾性筛选的运行时间比标准USR更快,平均快10倍,包括训练所需的时间。我们的结果表明,机器学习技术可以显著提高USR系列方法的虚拟筛选性能和效率。