College of Systems Engineering, National University of Defense Technology, Changsha 410073, China.
College of Computer, National University of Defense Technology, Changsha 410073, China.
Comput Intell Neurosci. 2020 Feb 18;2020:7839064. doi: 10.1155/2020/7839064. eCollection 2020.
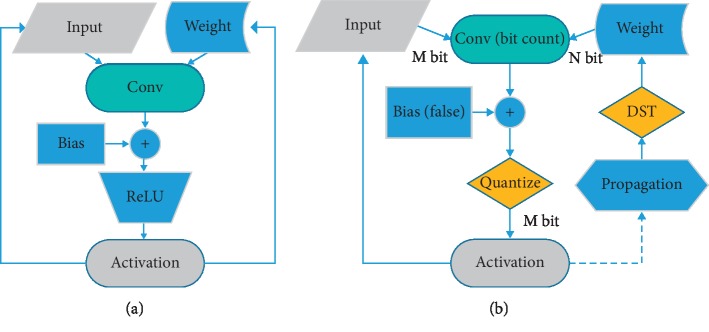
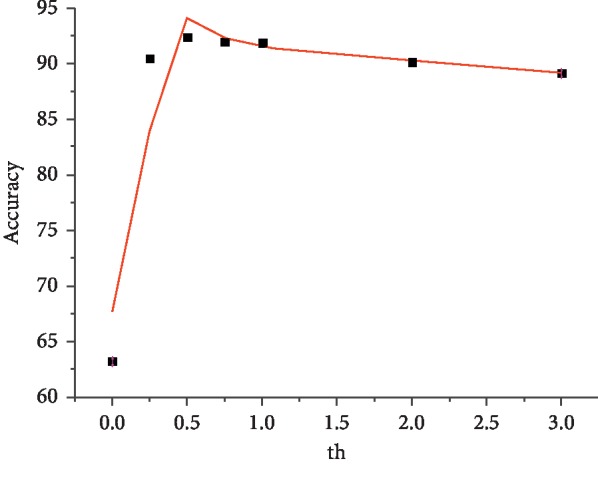
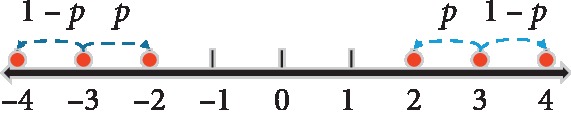
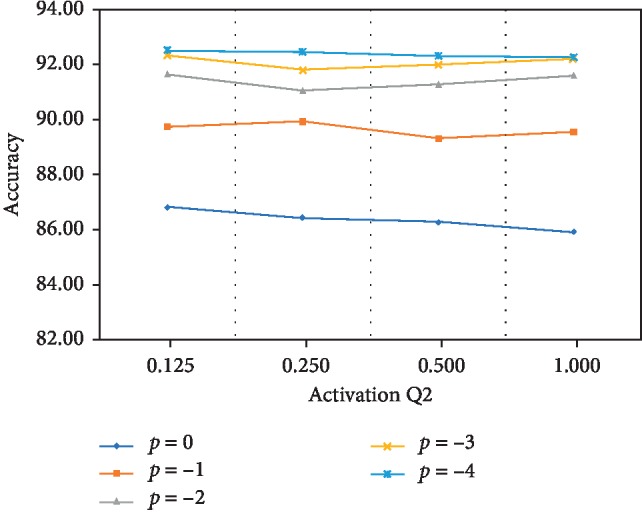
The increase in sophistication of neural network models in recent years has exponentially expanded memory consumption and computational cost, thereby hindering their applications on ASIC, FPGA, and other mobile devices. Therefore, compressing and accelerating the neural networks are necessary. In this study, we introduce a novel strategy to train low-bit networks with weights and activations quantized by several bits and address two corresponding fundamental issues. One is to approximate activations through low-bit discretization for decreasing network computational cost and dot-product memory. The other is to specify weight quantization and update mechanism for discrete weights to avoid gradient mismatch. With quantized low-bit weights and activations, the costly full-precision operation will be replaced by shift operation. We evaluate the proposed method on common datasets, and results show that this method can dramatically compress the neural network with slight accuracy loss.
近年来,神经网络模型的复杂性不断提高,导致内存消耗和计算成本呈指数级增长,从而阻碍了它们在 ASIC、FPGA 和其他移动设备上的应用。因此,需要对神经网络进行压缩和加速。在本研究中,我们提出了一种新的策略,用于训练权重和激活量化为几个比特的低比特网络,并解决了两个相应的基本问题。一个是通过低比特离散化来近似激活,以降低网络计算成本和点积内存。另一个是指定离散权重的量化和更新机制,以避免梯度失配。通过量化的低比特权重和激活,昂贵的全精度运算将被移位运算所取代。我们在常见数据集上评估了所提出的方法,结果表明,该方法可以在略微降低精度的情况下显著压缩神经网络。