Lee Seunghoon, Lee Young Hoon
Department of Industrial Engineering, Yonsei University, 50 Yonsei-ro, Seoul 03722, Korea.
Healthcare (Basel). 2020 Mar 27;8(2):77. doi: 10.3390/healthcare8020077.
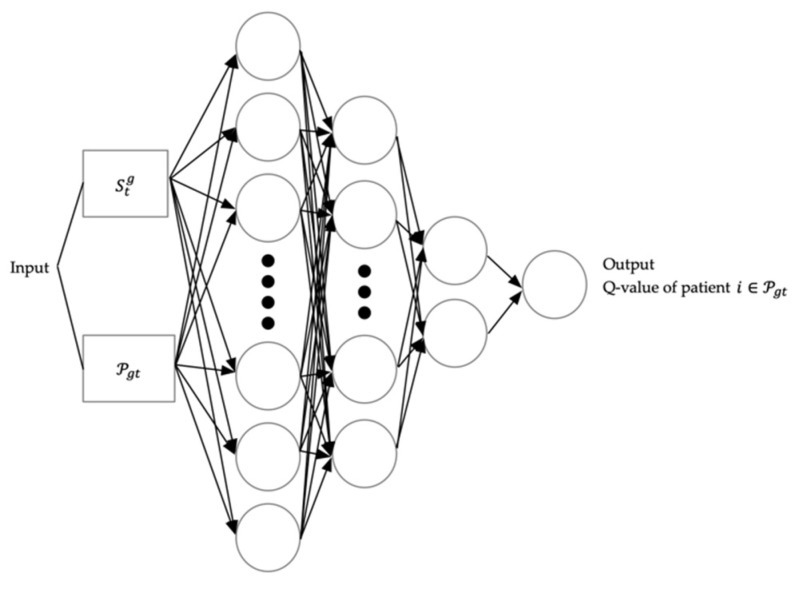
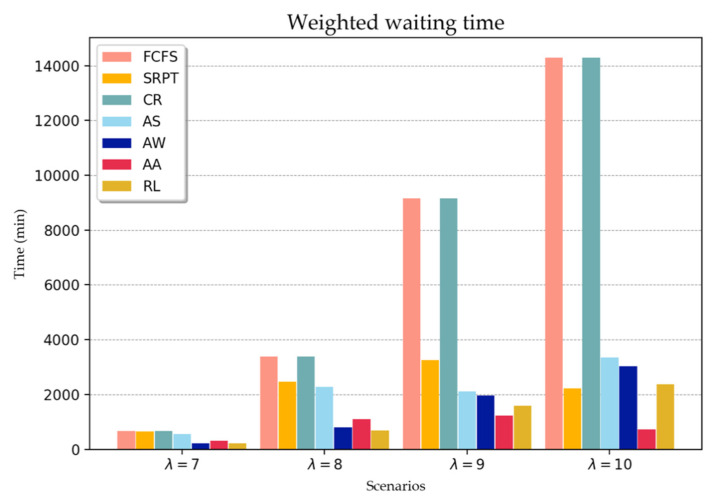
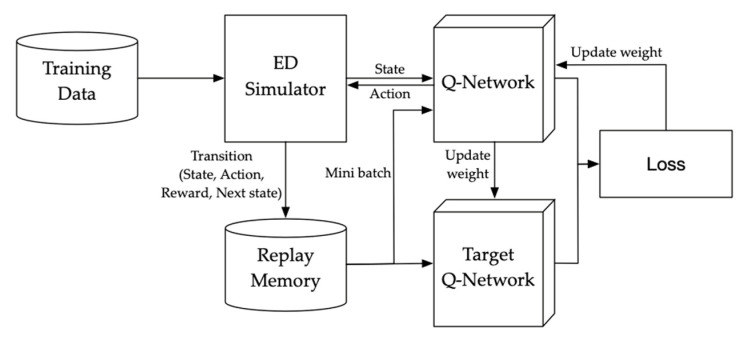
Emergency departments (ED) in hospitals usually suffer from crowdedness and long waiting times for treatment. The complexity of the patient's path flows and their controls come from the patient's diverse acute level, personalized treatment process, and interconnected medical staff and resources. One of the factors, which has been controlled, is the dynamic situation change such as the patient's composition and resources' availability. The patient's scheduling is thus complicated in consideration of various factors to achieve ED efficiency. To address this issue, a deep reinforcement learning (RL) is designed and applied in an ED patients' scheduling process. Before applying the deep RL, the mathematical model and the Markov decision process (MDP) for the ED is presented and formulated. Then, the algorithm of the RL based on deep Q-networks (DQN) is designed to determine the optimal policy for scheduling patients. To evaluate the performance of the deep RL, it is compared with the dispatching rules presented in the study. The deep RL is shown to outperform the dispatching rules in terms of minimizing the weighted waiting time of the patients and the penalty of emergent patients in the suggested scenarios. This study demonstrates the successful implementation of the deep RL for ED applications, particularly in assisting decision-makers under the dynamic environment of an ED.
医院的急诊科通常面临拥挤和患者等待治疗时间长的问题。患者就医流程及其管控的复杂性源于患者不同的急症程度、个性化的治疗过程以及医护人员和资源的相互关联性。其中一个已得到控制的因素是动态情况的变化,如患者构成和资源可用性。因此,考虑到各种因素,患者调度变得复杂,以实现急诊科的效率。为解决这一问题,设计了一种深度强化学习(RL)并将其应用于急诊科患者调度过程。在应用深度强化学习之前,给出并构建了急诊科的数学模型和马尔可夫决策过程(MDP)。然后,设计了基于深度Q网络(DQN)的强化学习算法,以确定患者调度的最优策略。为评估深度强化学习的性能,将其与该研究中提出的调度规则进行比较。在建议的场景中,深度强化学习在最小化患者加权等待时间和急症患者惩罚方面表现优于调度规则。本研究证明了深度强化学习在急诊科应用中的成功实施,特别是在急诊科动态环境下协助决策者方面。