School of Science, Kunming University of Science and Technology, Kunming, 650500, People's Republic of China.
School of Mathematics, The University of Manchester, Manchester, M13 9PL, UK.
BMC Bioinformatics. 2020 Mar 23;21(1):121. doi: 10.1186/s12859-020-3411-3.
Feature selection in class-imbalance learning has gained increasing attention in recent years due to the massive growth of high-dimensional class-imbalanced data across many scientific fields. In addition to reducing model complexity and discovering key biomarkers, feature selection is also an effective method of combating overlapping which may arise in such data and become a crucial aspect for determining classification performance. However, ordinary feature selection techniques for classification can not be simply used for addressing class-imbalanced data without any adjustment. Thus, more efficient feature selection technique must be developed for complicated class-imbalanced data, especially in the context of high-dimensionality.
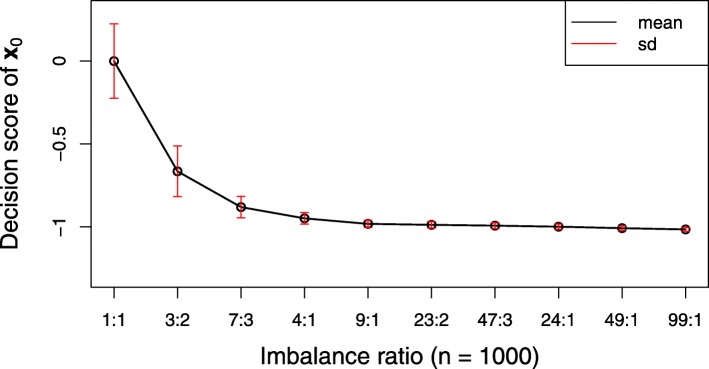
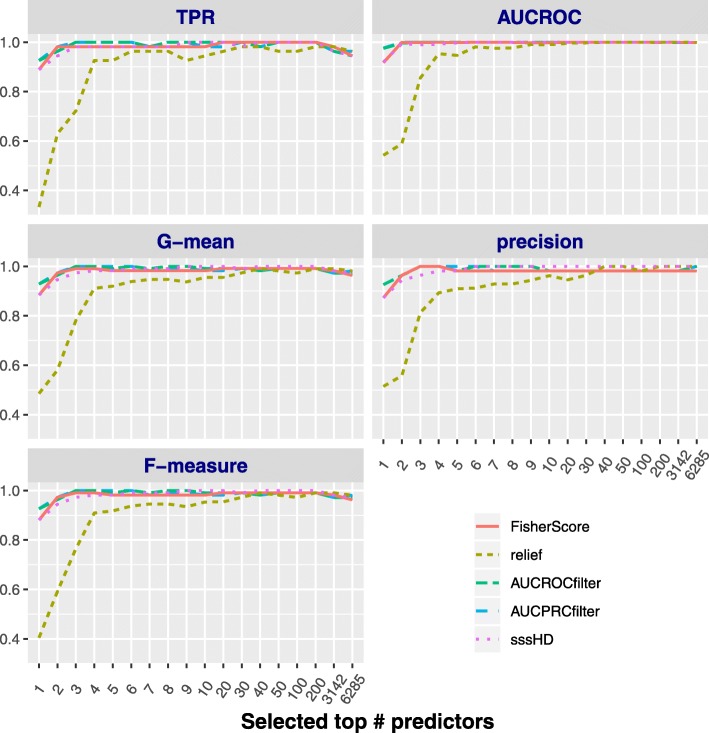
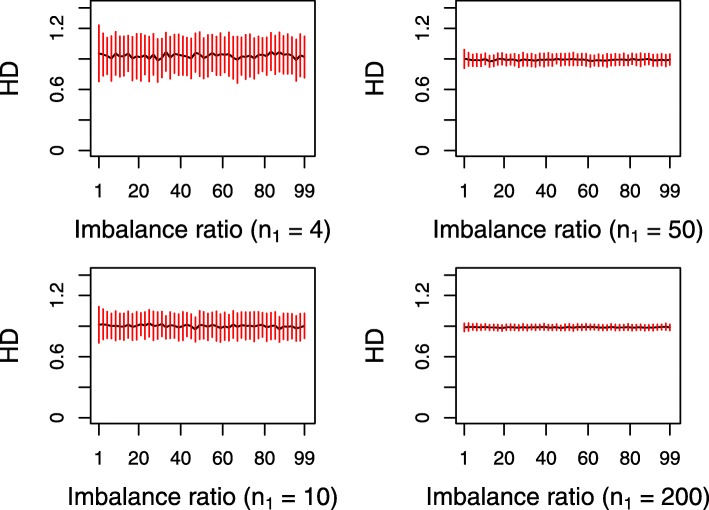
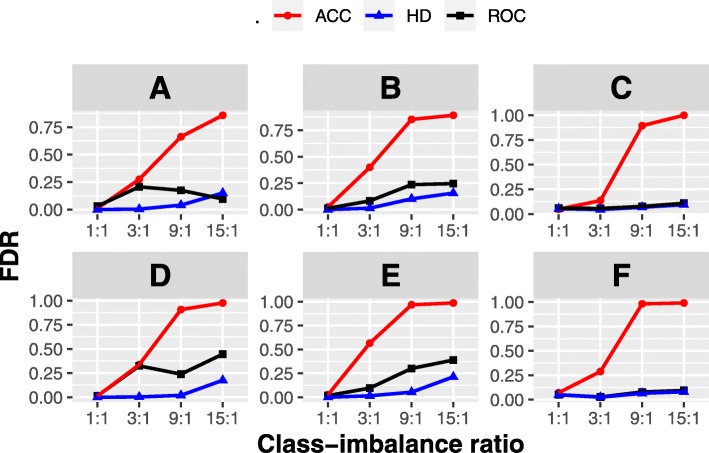
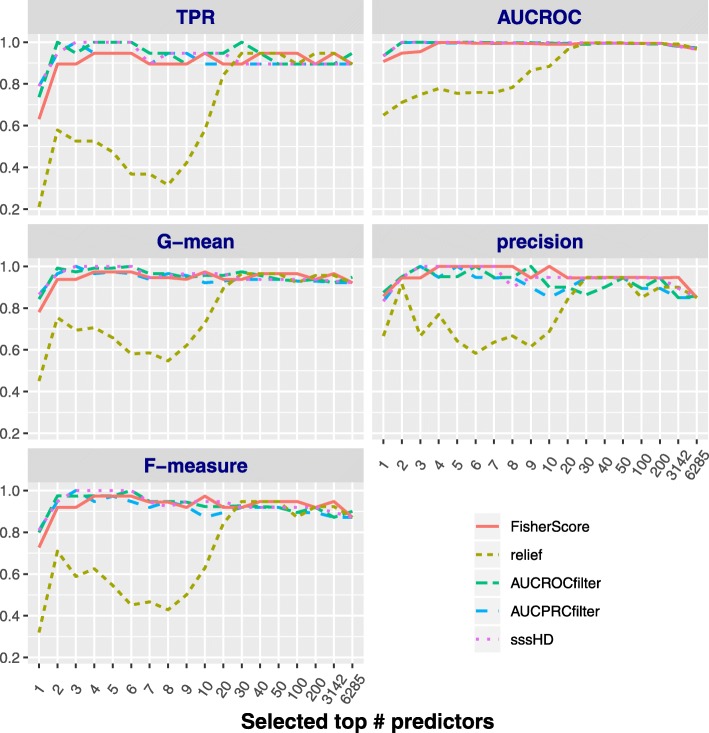
We proposed an algorithm called sssHD to achieve stable sparse feature selection applied it to complicated class-imbalanced data. sssHD is based on the Hellinger distance (HD) coupled with sparse regularization techniques. We stated that Hellinger distance is not only class-insensitive but also translation-invariant. Simulation result indicates that HD-based selection algorithm is effective in recognizing key features and control false discoveries for class-imbalance learning. Five gene expression datasets are also employed to test the performance of the sssHD algorithm, and a comparison with several existing selection procedures is performed. The result shows that sssHD is highly competitive in terms of five assessment metrics. In addition, sssHD presents limited differences between performing and not performing re-balance preprocessing.
sssHD is a practical feature selection method for high-dimensional class-imbalanced data, which is simple and can be an alternative for performing feature selection in class-imbalanced data. sssHD can be easily extended by connecting it with different re-balance preprocessing, different sparse regularization structures as well as different classifiers. As such, the algorithm is extremely general and has a wide range of applicability.
由于许多科学领域的高维类别不平衡数据的大量增长,特征选择在类别不平衡学习中越来越受到关注。除了降低模型的复杂性和发现关键生物标志物之外,特征选择也是一种有效的方法,可以克服此类数据中可能出现的重叠问题,并且成为确定分类性能的关键方面。但是,普通的分类特征选择技术不能在不进行任何调整的情况下简单地用于处理类别不平衡数据。因此,必须针对复杂的类别不平衡数据,特别是在高维情况下,开发更有效的特征选择技术。
我们提出了一种名为 sssHD 的算法,用于实现稳定稀疏的特征选择,并将其应用于复杂的类别不平衡数据。sssHD 基于 Hellinger 距离(HD)和稀疏正则化技术。我们指出,Hellinger 距离不仅对类别不敏感,而且还具有平移不变性。模拟结果表明,基于 HD 的选择算法在识别关键特征和控制类别不平衡学习中的错误发现方面非常有效。我们还使用五个基因表达数据集来测试 sssHD 算法的性能,并与几种现有的选择过程进行了比较。结果表明,sssHD 在五个评估指标方面具有很强的竞争力。此外,sssHD 在执行和不执行重新平衡预处理之间的差异有限。
sssHD 是一种适用于高维类别不平衡数据的实用特征选择方法,它简单易用,可以作为类别不平衡数据中执行特征选择的替代方法。sssHD 可以通过连接不同的重新平衡预处理、不同的稀疏正则化结构以及不同的分类器来轻松扩展。因此,该算法非常通用,具有广泛的适用性。