FDA/National Center for Toxicological Research, 3900 NCTR Rd, Jefferson, AR, 72079, USA.
University of Arkansas at Little Rock, 2801 S. University Ave, Little Rock, AR, 72204, USA.
BMC Med Inform Decis Mak. 2020 Apr 15;20(1):68. doi: 10.1186/s12911-020-1078-3.
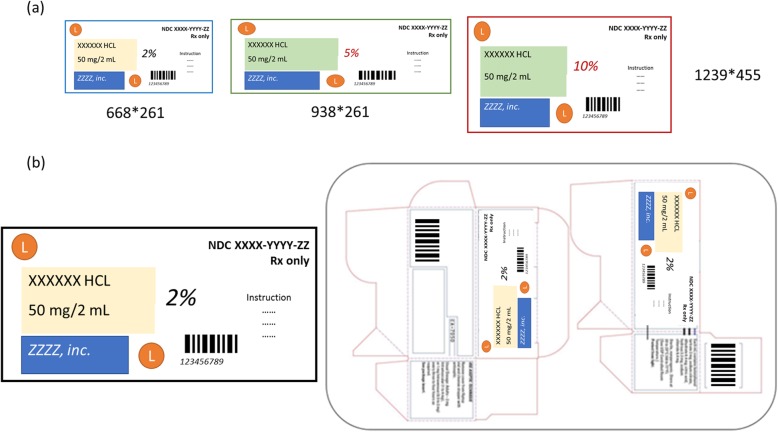
Drug label, or packaging insert play a significant role in all the operations from production through drug distribution channels to the end consumer. Image of the label also called Display Panel or label could be used to identify illegal, illicit, unapproved and potentially dangerous drugs. Due to the time-consuming process and high labor cost of investigation, an artificial intelligence-based deep learning model is necessary for fast and accurate identification of the drugs.
In addition to image-based identification technology, we take advantages of rich text information on the pharmaceutical package insert of drug label images. In this study, we developed the Drug Label Identification through Image and Text embedding model (DLI-IT) to model text-based patterns of historical data for detection of suspicious drugs. In DLI-IT, we first trained a Connectionist Text Proposal Network (CTPN) to crop the raw image into sub-images based on the text. The texts from the cropped sub-images are recognized independently through the Tesseract OCR Engine and combined as one document for each raw image. Finally, we applied universal sentence embedding to transform these documents into vectors and find the most similar reference images to the test image through the cosine similarity.
We trained the DLI-IT model on 1749 opioid and 2365 non-opioid drug label images. The model was then tested on 300 external opioid drug label images, the result demonstrated our model achieves up-to 88% of the precision in drug label identification, which outperforms previous image-based or text-based identification method by up-to 35% improvement.
To conclude, by combining Image and Text embedding analysis under deep learning framework, our DLI-IT approach achieved a competitive performance in advancing drug label identification.
药品标签或包装插页在从生产到药品分销渠道再到最终消费者的所有环节中都发挥着重要作用。标签的图像也称为展示面板或标签,可用于识别非法、违禁、未经批准和潜在危险的药品。由于调查过程耗时且劳动成本高,因此需要基于人工智能的深度学习模型来快速准确地识别药品。
除了基于图像的识别技术外,我们还利用药品标签图像的包装插页上丰富的文本信息。在这项研究中,我们开发了通过图像和文本嵌入模型识别药品标签(DLI-IT),以对历史数据的基于文本的模式进行建模,从而检测可疑药品。在 DLI-IT 中,我们首先训练一个连接文本提议网络(CTPN),根据文本将原始图像裁剪成子图像。通过 Tesseract OCR 引擎识别裁剪后的子图像中的文本,并将其组合成每个原始图像的一个文档。最后,我们应用通用句子嵌入将这些文档转换为向量,并通过余弦相似度找到与测试图像最相似的参考图像。
我们在 1749 张阿片类药物和 2365 张非阿片类药物标签图像上训练了 DLI-IT 模型。然后,我们在 300 张外部阿片类药物标签图像上对该模型进行了测试,结果表明,我们的模型在药物标签识别方面的准确率高达 88%,比以前的基于图像或基于文本的识别方法提高了高达 35%。
总之,通过在深度学习框架下结合图像和文本嵌入分析,我们的 DLI-IT 方法在推进药物标签识别方面取得了有竞争力的性能。