Department of Computer Science, University of Oxford, Oxford, United Kingdom.
Omics Data Automation Inc., Beaverton, Oregon, United States of America.
PLoS One. 2020 Apr 23;15(4):e0231826. doi: 10.1371/journal.pone.0231826. eCollection 2020.
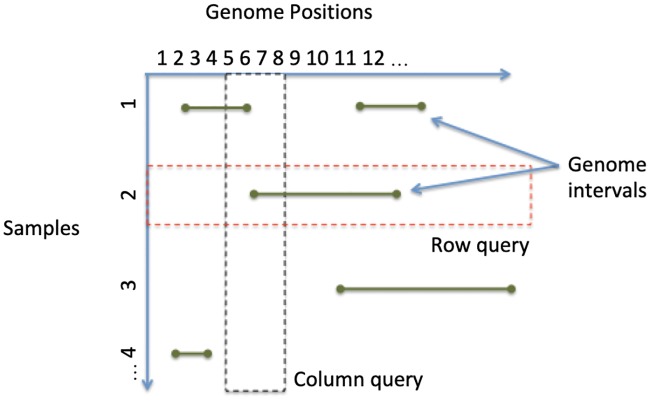
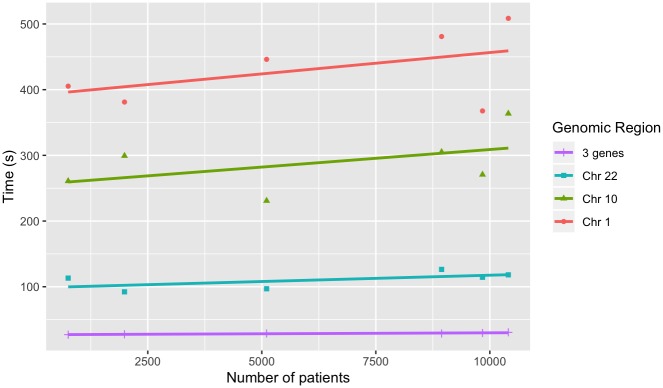
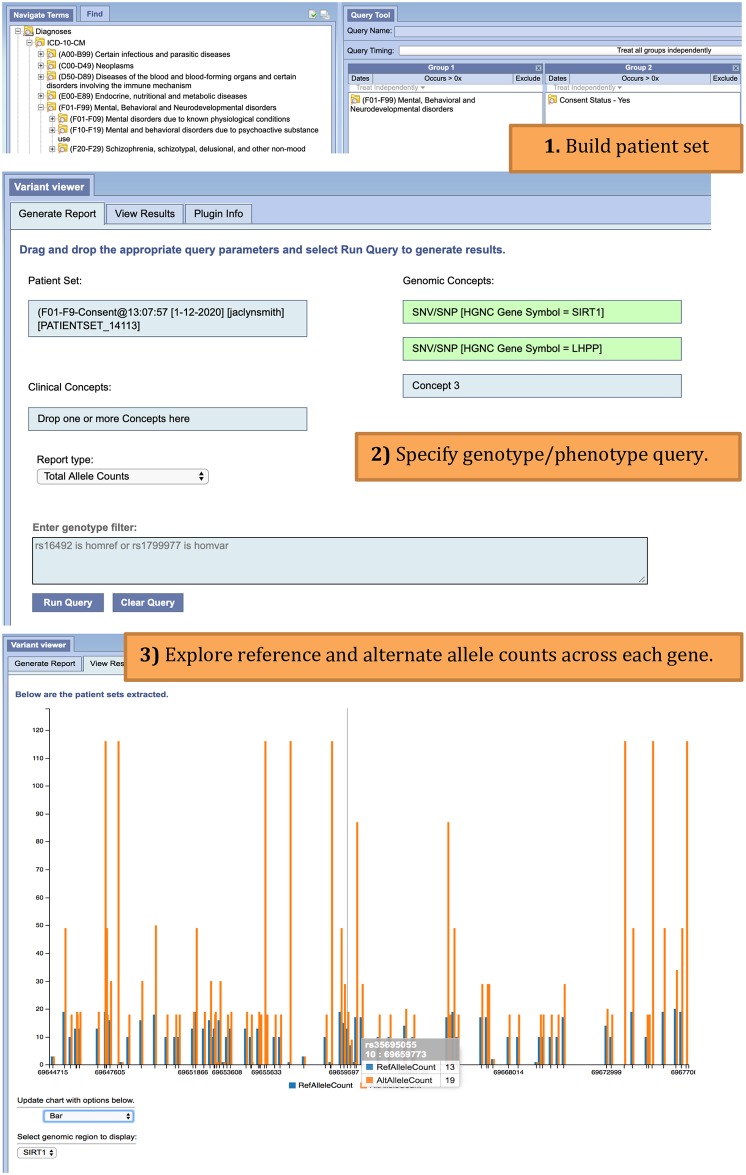
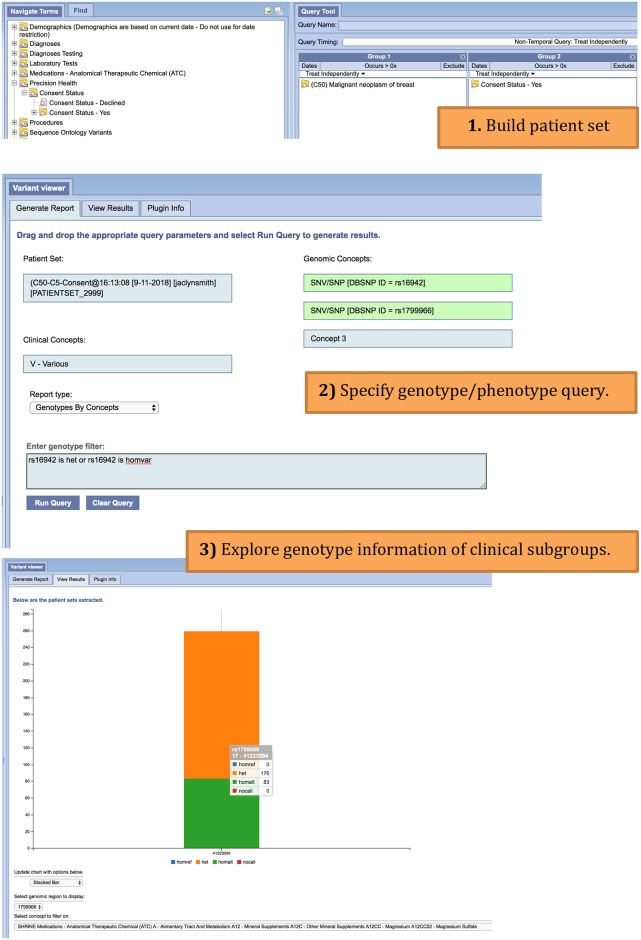
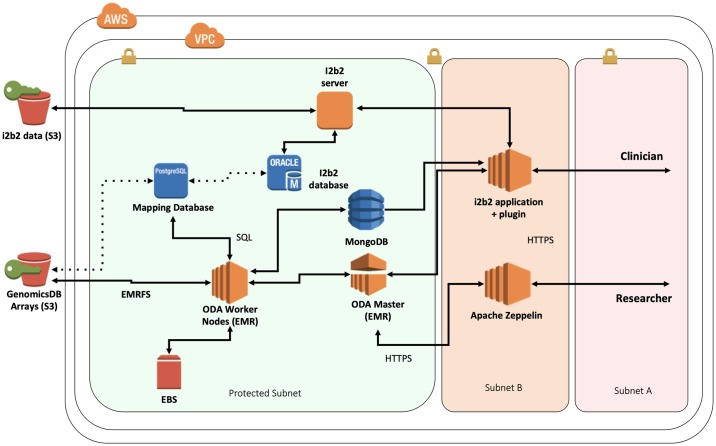
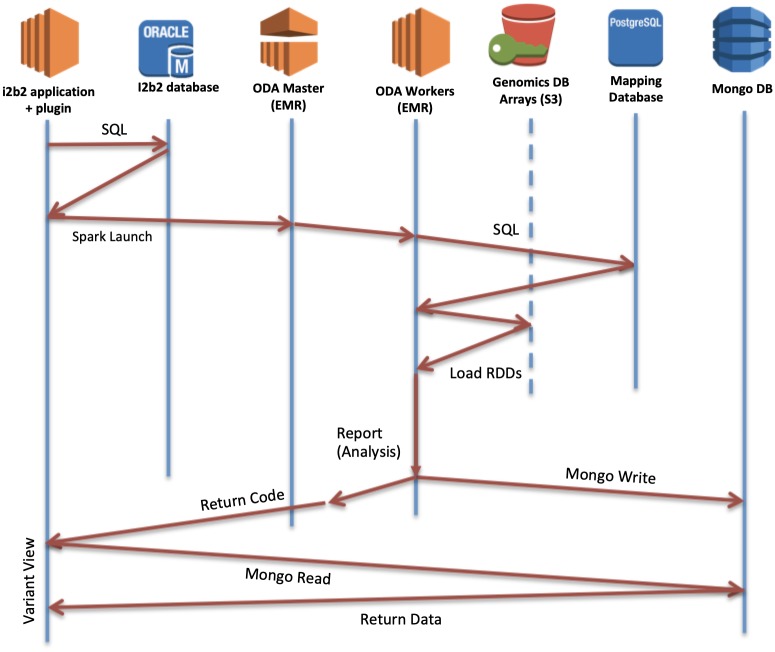
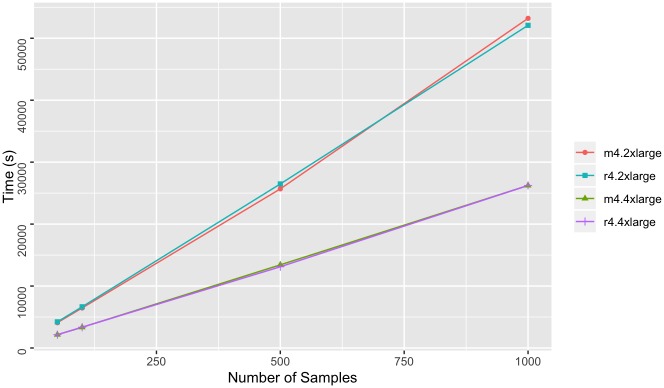
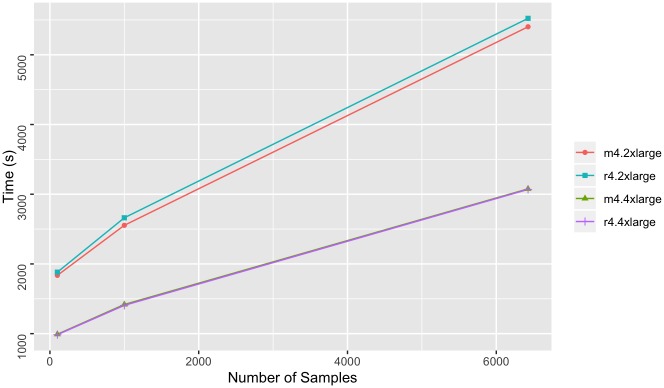
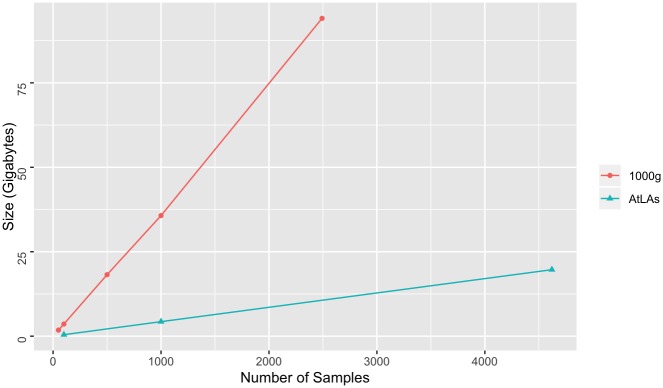
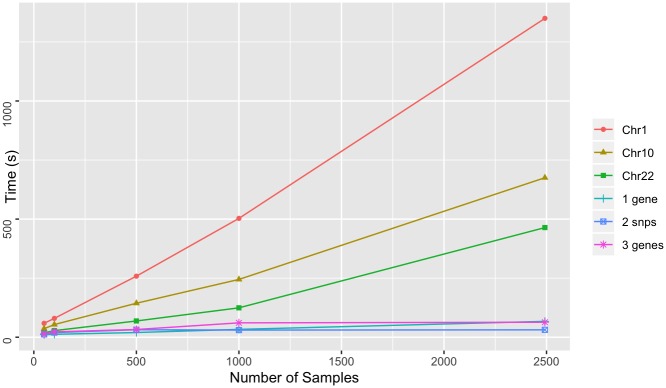
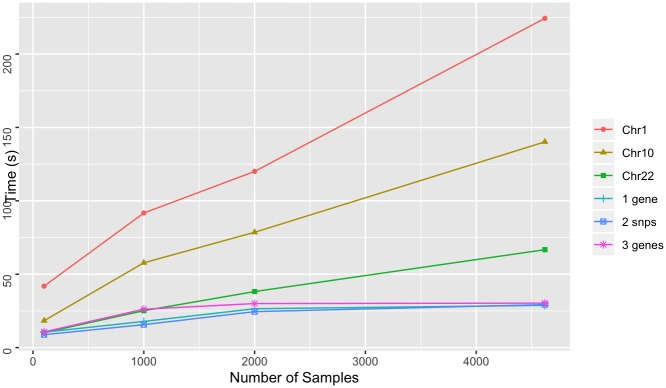
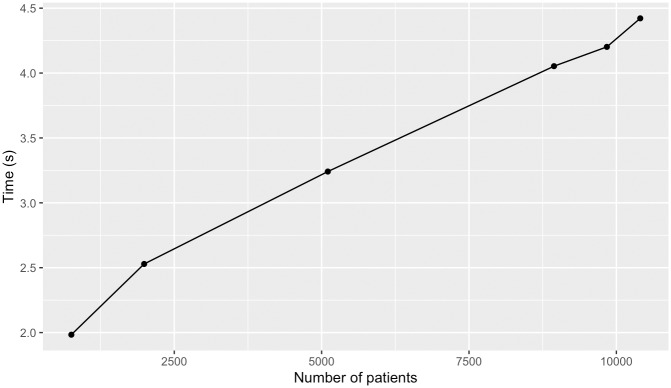
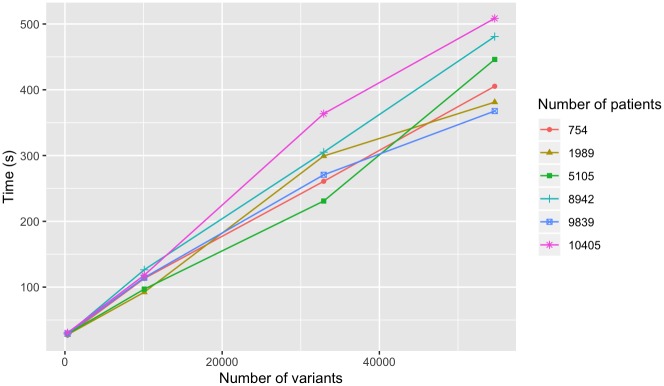
The affordability of next-generation genomic sequencing and the improvement of medical data management have contributed largely to the evolution of biological analysis from both a clinical and research perspective. Precision medicine is a response to these advancements that places individuals into better-defined subsets based on shared clinical and genetic features. The identification of personalized diagnosis and treatment options is dependent on the ability to draw insights from large-scale, multi-modal analysis of biomedical datasets. Driven by a real use case, we premise that platforms that support precision medicine analysis should maintain data in their optimal data stores, should support distributed storage and query mechanisms, and should scale as more samples are added to the system. We extended a genomics-based columnar data store, GenomicsDB, for ease of use within a distributed analytics platform for clinical and genomic data integration, known as the ODA framework. The framework supports interaction from an i2b2 plugin as well as a notebook environment. We show that the ODA framework exhibits worst-case linear scaling for array size (storage), import time (data construction), and query time for an increasing number of samples. We go on to show worst-case linear time for both import of clinical data and aggregate query execution time within a distributed environment. This work highlights the integration of a distributed genomic database with a distributed compute environment to support scalable and efficient precision medicine queries from a HIPAA-compliant, cohort system in a real-world setting. The ODA framework is currently deployed in production to support precision medicine exploration and analysis from clinicians and researchers at UCLA David Geffen School of Medicine.
从临床和研究的角度来看,下一代基因组测序的可负担性和医疗数据管理的改进极大地促进了生物分析的发展。精准医学是对这些进步的一种回应,它根据共享的临床和遗传特征将个体更好地划分为更小的亚组。个性化诊断和治疗方案的确定取决于从大规模多模式生物医学数据集分析中得出见解的能力。受实际用例的驱动,我们假设支持精准医学分析的平台应将数据保存在其最佳数据存储中,应支持分布式存储和查询机制,并应随着系统中添加更多样本而扩展。我们扩展了基于基因组学的列式数据存储 GenomicsDB,以便在临床和基因组数据集成的分布式分析平台 ODA 框架中更轻松地使用。该框架支持 i2b2 插件以及笔记本环境的交互。我们表明,对于越来越多的样本,ODA 框架在数组大小(存储)、导入时间(数据构建)和查询时间方面表现出最坏情况的线性缩放。我们接着展示了在分布式环境中,临床数据的导入和聚合查询执行时间都具有最坏情况的线性时间。这项工作强调了将分布式基因组数据库与分布式计算环境集成在一起,以支持从符合 HIPAA 标准的队列系统中进行可扩展且高效的精准医学查询。ODA 框架目前已在生产中部署,以支持加利福尼亚大学洛杉矶分校大卫格芬医学院的临床医生和研究人员进行精准医学探索和分析。