Kar Anuradha
École Normale Supérieure de Lyon, 46 Allée d'Italie, 69007 Lyon, France.
Vision (Basel). 2020 May 7;4(2):25. doi: 10.3390/vision4020025.
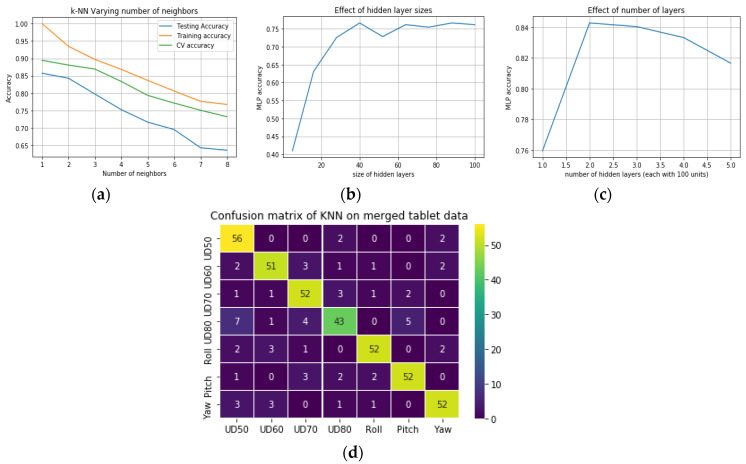
Analyzing the gaze accuracy characteristics of an eye tracker is a critical task as its gaze data is frequently affected by non-ideal operating conditions in various consumer eye tracking applications. In previous research on pattern analysis of gaze data, efforts were made to model human visual behaviors and cognitive processes. What remains relatively unexplored are questions related to identifying gaze error sources as well as quantifying and modeling their impacts on the data quality of eye trackers. In this study, gaze error patterns produced by a commercial eye tracking device were studied with the help of machine learning algorithms, such as classifiers and regression models. Gaze data were collected from a group of participants under multiple conditions that commonly affect eye trackers operating on desktop and handheld platforms. These conditions (referred here as error sources) include user distance, head pose, and eye-tracker pose variations, and the collected gaze data were used to train the classifier and regression models. It was seen that while the impact of the different error sources on gaze data characteristics were nearly impossible to distinguish by visual inspection or from data statistics, machine learning models were successful in identifying the impact of the different error sources and predicting the variability in gaze error levels due to these conditions. The objective of this study was to investigate the efficacy of machine learning methods towards the detection and prediction of gaze error patterns, which would enable an in-depth understanding of the data quality and reliability of eye trackers under unconstrained operating conditions. Coding resources for all the machine learning methods adopted in this study were included in an open repository named MLGaze to allow researchers to replicate the principles presented here using data from their own eye trackers.
分析眼动仪的注视准确性特征是一项关键任务,因为在各种消费级眼动追踪应用中,其注视数据经常受到非理想操作条件的影响。在以往关于注视数据分析模式的研究中,人们致力于对人类视觉行为和认知过程进行建模。相对而言尚未得到充分探索的是与识别注视误差源以及量化和建模它们对眼动仪数据质量的影响相关的问题。在本研究中,借助机器学习算法(如分类器和回归模型)对一款商用眼动追踪设备产生的注视误差模式进行了研究。在多种通常会影响在桌面和手持平台上运行的眼动仪的条件下,从一组参与者那里收集了注视数据。这些条件(在此称为误差源)包括用户距离、头部姿势以及眼动仪姿势变化,并且所收集的注视数据被用于训练分类器和回归模型。可以看出,虽然通过目视检查或数据统计几乎无法区分不同误差源对注视数据特征的影响,但机器学习模型成功地识别了不同误差源的影响,并预测了由于这些条件导致的注视误差水平的变化。本研究的目的是调查机器学习方法在检测和预测注视误差模式方面的有效性,这将有助于深入了解在无约束操作条件下眼动仪的数据质量和可靠性。本研究中采用的所有机器学习方法的编码资源都包含在一个名为MLGaze的开放存储库中,以便研究人员能够使用他们自己眼动仪的数据来复制此处呈现的原理。