Center for Cancer Systems Biology (CCSB), Dana-Farber Cancer Institute, Boston, MA, 02215, USA.
Department of Genetics, Blavatnik Institute, Harvard Medical School, Boston, MA, 02115, USA.
Nat Commun. 2020 May 11;11(1):2326. doi: 10.1038/s41467-020-16174-z.
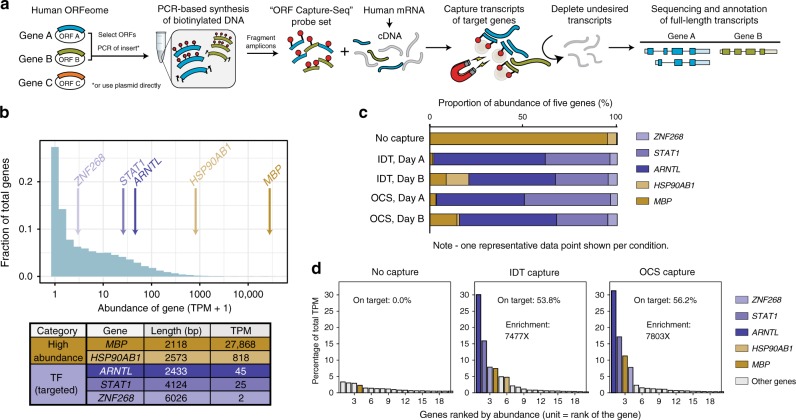
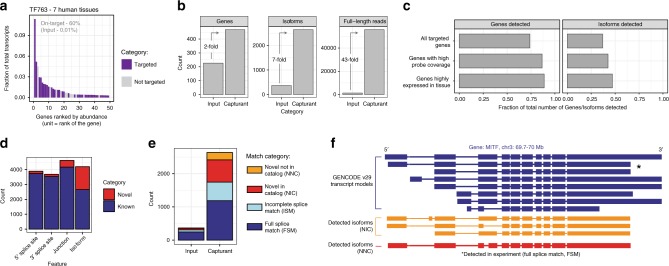
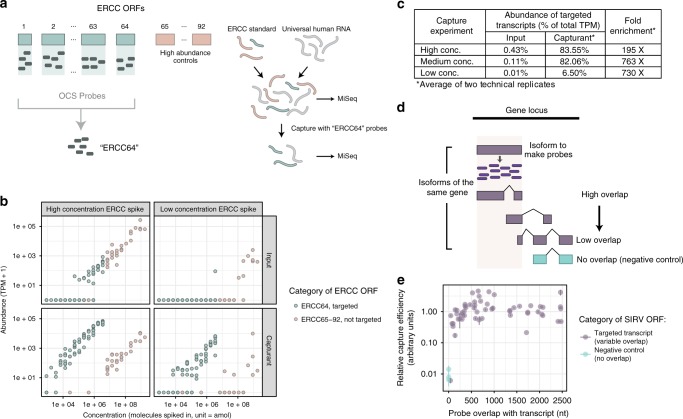
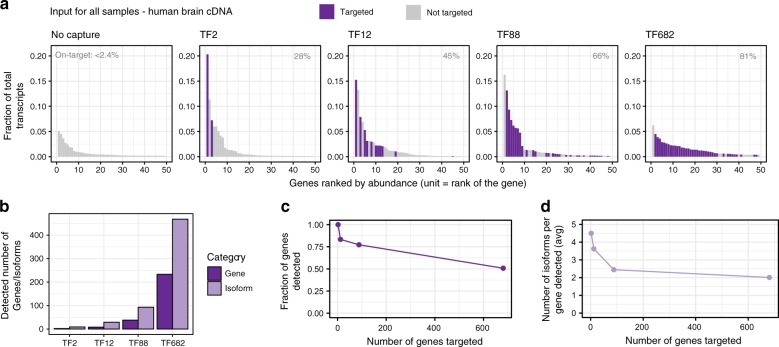
Most human protein-coding genes are expressed as multiple isoforms, which greatly expands the functional repertoire of the encoded proteome. While at least one reliable open reading frame (ORF) model has been assigned for every coding gene, the majority of alternative isoforms remains uncharacterized due to (i) vast differences of overall levels between different isoforms expressed from common genes, and (ii) the difficulty of obtaining full-length transcript sequences. Here, we present ORF Capture-Seq (OCS), a flexible method that addresses both challenges for targeted full-length isoform sequencing applications using collections of cloned ORFs as probes. As a proof-of-concept, we show that an OCS pipeline focused on genes coding for transcription factors increases isoform detection by an order of magnitude when compared to unenriched samples. In short, OCS enables rapid discovery of isoforms from custom-selected genes and will accelerate mapping of the human transcriptome.
大多数人类蛋白编码基因都表达为多种异构体,这极大地扩展了编码蛋白质组的功能范围。虽然每个编码基因都至少分配了一个可靠的开放阅读框(ORF)模型,但由于(i)来自常见基因的不同异构体的整体水平差异很大,以及(ii)获得全长转录本序列的困难,大多数替代异构体仍然未被表征。在这里,我们提出了 ORF Capture-Seq(OCS),这是一种灵活的方法,使用克隆的 ORF 作为探针,针对靶向全长异构体测序应用解决了这两个挑战。作为概念验证,我们展示了一个专注于转录因子编码基因的 OCS 管道,与未富集的样本相比,其异构体检测增加了一个数量级。简而言之,OCS 能够从自定义选择的基因中快速发现异构体,并加速人类转录组的映射。